Information
Title: Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Reference
Code: SUDO-AI-3D/zero123plus
Author: Sangwoo Jo
Last updated on Dec. 16, 2024
Zero123++#
1. Introduction#

Fig. 742 High-quality, consistent multi-view 3D images from Zero123++#
Zero-1-to-3(Zero123) 논문이 zero-shot 형태로 single-image-to-3D conversion 을 하는 기법을 처음으로 소개하였습니다. 하지만 해당 방식으로는 주어진 view 에 대해서 독립적으로 객체를 생성하게 됨으로써 multi-view consistency 에서 부족한 부분을 보여주게 된다고 설명합니다. Zero123++ 논문에서 이를 해결하기 위해 여섯개의 view 로부터 하나의 이미지를 생성하여 multi-view 에 대한 joint distirbution 을 학습할 수 있도록 설정합니다.
또한, Zero-1-to-3 논문에서 다음과 같은 한계점이 있다고 제시합니다.
a) 첫번째로 global 및 local conditioning mechanism 을 비롯한 Stable Diffusion model prior 를 효율적으로 사용하지 않았고,
b) 두번째로 Zero-1-to-3 논문에서 512x512 이미지 해상도로 학습 시 불안정하게 수렴하게 되어 256x256 해상도로 줄인 부분에 대해 논문 저자는 원인을 분석하며 새로운 scheduling 기법을 소개합니다.
2. Improving Consistency and Conditioning#
2.1. Multi-view Generation#
Zero-1-to-3 모델은 단일 이미지를 독립적으로 생성하며 multi-view 이미지에 대한 상관관계를 학습 혹은 생성 시에 고려하지 않습니다. 따라서, Zero123++에서는 3×2 layout 의 6개 이미지를 단일 프레임으로 tiling 하여 multiple image 에 대한 joint distribution 을 학습하게 됩니다.
Objaverse 데이터셋은 기본적으로 gravity axis 은 동일하지만 객체들이 일관된 canonical pose 를 가지고 있지 않습니다. 따라서 절대적인 camera pose 를 기반으로 해당 데이터셋을 학습하게 되면 객체의 orientation 을 학습하는데 어려움이 있다고 주장합니다.
반면에 Zero-1-to-3 는 input view 에 대한 상대적인 camera pose(elevation/azimuth angle) 을 입력받아 학습하였습니다. 그러나 해당 방식을 활용한다면 novel view 에 대한 relative pose 를 구하기 위해서는 input view 에 대한 elevation angle 을 사전에 알아야 한다는 단점이 있습니다. 후속적으로 One-2-3-45 그리고 DreamGaussian 논문에서 elevation angle 을 추가적으로 예측하는 모듈을 정의하고, 이에 따라 오차율도 증가하게 됩니다.
Elevation/Azimuth angle 이란?
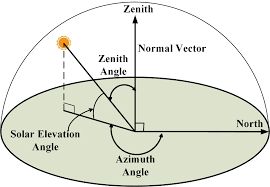
Fig. 743 Elevation/Azimuth angle#
이러한 문제를 해결하기 위해 elevation angle 을 고정시킨 상태에서 상대적인 azimuth angle 을 통한 novel view pose 를 정의합니다. 더 자세하게는 6개의 pose 를 아래 사진과 같이 정의하게 됩니다.
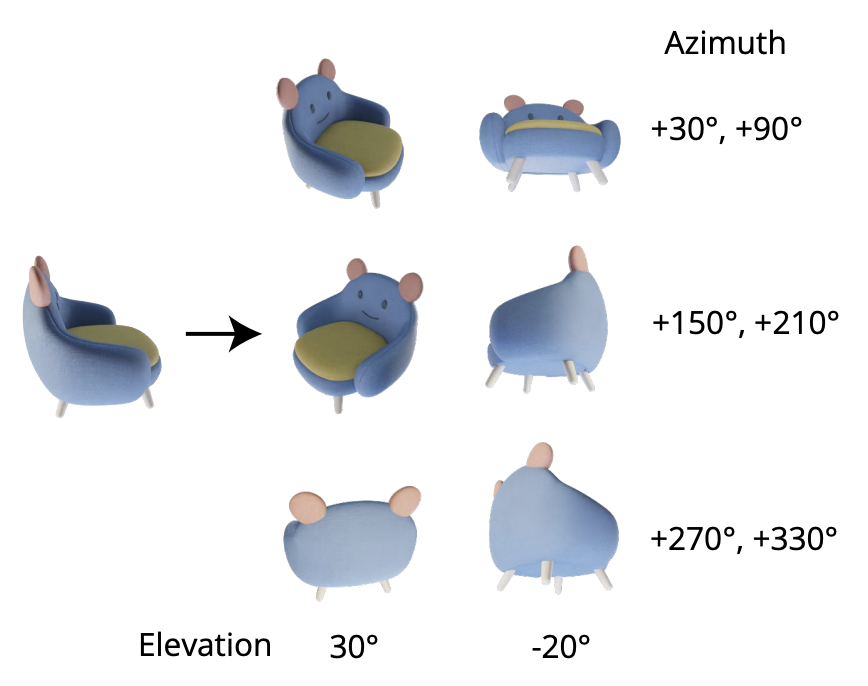
Fig. 744 3x2 layout of Zero123++ prediction#
2.2. Consistency and Stability: Noise Schedule#
Stable Diffusion 모델에서 사용되었던 scaled-linear schedule 은 local detail 을 학습하는데 초점을 두고 Signal-to-Noise Ratio (SNR) 가 낮은 timestep 이 극히 드뭅니다. SNR 이 낮은 구간에서 global low frequency 정보들을 학습하게 되며 해당 단계에서 step 수가 적으면 구조적인 변형이 클 수가 있습니다. 따라서, 이러한 scheduling 은 단일 이미지를 생성하는데는 유용하지만 multi-view consistent 한 이미지를 생성하는데 한계가 있다고 주장합니다.
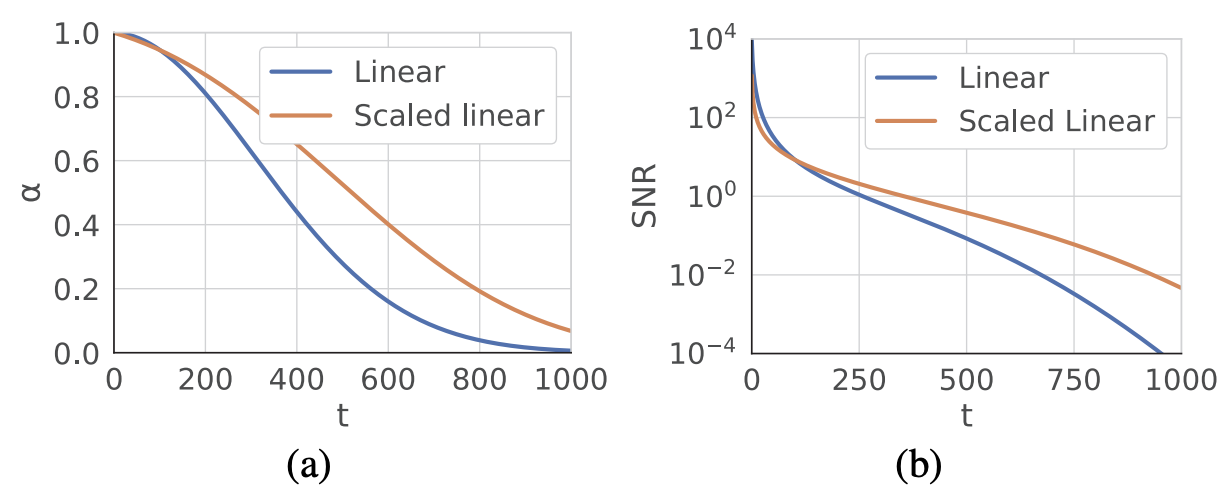
Fig. 745 Linear vs Scaled linear schedule#
또한, 동일한 noise 가 주입되었을때 고해상도 이미지가 저해상도 이미지에 비해 noise level 이 적기 때문에, Zero-1-to-3 모델에서 고해상도 이미지를 학습하였을 때 불안정한 모습을 보여주었던 것도 동일한 원인 때문이라고 설명합니다.
Zero123++ 에서는 scaled-linear schedule 대신에 linear schedule 를 사용하게 되고, 변화된 schedule 에 따라 \(x\)-prediction, \(\epsilon\)-prediction 모델보다 \(v\)-prediction 모델이 더 안정적으로 학습되었다고 합니다. 따라서, Stable Diffusion 2 \(v\)-prediction 모델로 fine-tuning 을 진행하였다고 합니다.
2.3. Local Condition: Scaled Reference Attention#
기존에 Zero-1-to-3 논문에서 noisy input 과 conditioned image(single-view input) 가 feature-wise concatenate 하는데 해당 방식으로는 pixel-wise spatial correspondence 가 정확하지 않다고 합니다.
Zero123++ 에서는 이 부분을 보완하여 Reference Attention 이라는 기법을 소개합니다. Reference Attention 이란, 아래 그림과 같이 noisy latent 와 conditioned latent 간에 self-attention 모듈에서의 key, value 값을 추가하여 연산 작업을 진행합니다. 이때, noisy input 에 주입된 noise 를 동일하게 conditioned image 에 적용하였다고 합니다.
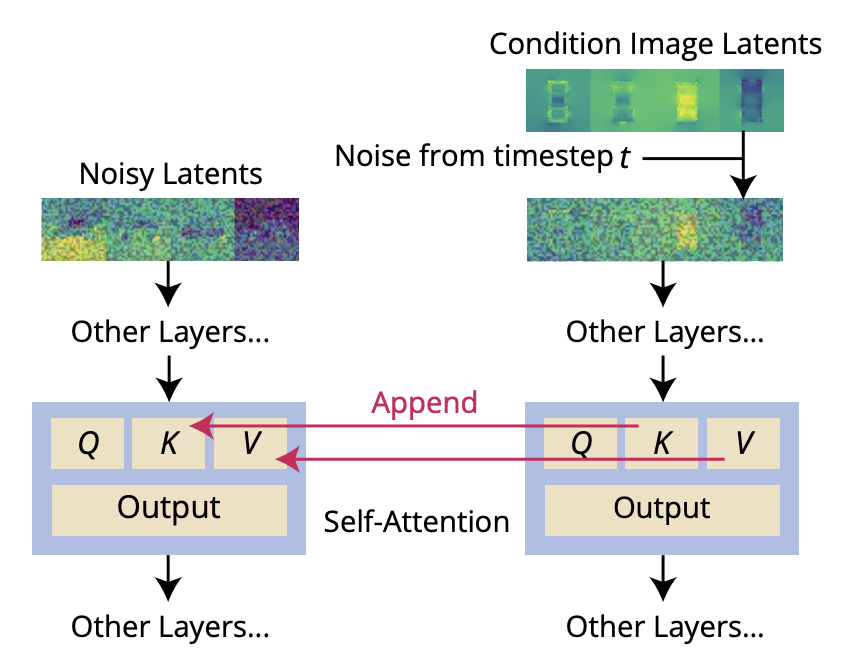
Fig. 746 Reference Attention#
Reference Attention 기법을 적용한 결과, fine-tuning 작업을 진행하지 않아도 reference image 에서의 semantic content 와 texture 가 잘 반영되었습니다. 또한, fine-tuning 을 하였을때 reference latent 을 5x scaling 하였을때 reference image 와의 일관성을 가장 잘 보여주었다고 합니다.

Fig. 747 Comparison on local conditioning#
2.4. Global Condition: FlexDiffuse#
Zero123++ 논문에서 추가적으로 FlexDiffuse 에서 소개한 linear guidance mechanism 을 활용하여 fine-tuning 범위를 최소화하는 선에서 global image conditioning 하였습니다.
더 자세하게는, \(L \times D\) 차원의 prompt embedding \(T\) 와 \(D\) 차원의 CLIP global image embedding \(I\) 에 global weight \(w_i\) 를 곱한 값을 더하여 모델에 입력합니다. 이때, \(L\) 은 token length 이고 \(D\) 는 token embedding 의 차원 크기입니다. 이때, \(w_i = \frac{i}{L}\) 로 초기 가중치 값을 설정하였습니다. Text condition 이 없을 경우에는 empty prompt 를 encoding 하여 \(T\) 를 얻게 됩니다.
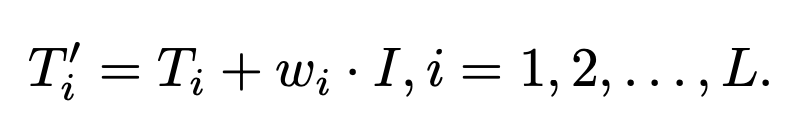
Fig. 748 FlexDiffuse’s linear guidance#
위와 같은 global conditioning 을 하였을때, 보이지 않은 unseen region 에서도 semantic 한 정보들을 유지한채 이미지를 잘 생성하는 부분을 확인할 수 있습니다.

Fig. 749 Ablation on global conditioning#
2.5. Putting Everything Together#
정리하자면 해당 논문은 Stable Diffusion 2 \(v\)-model 을 사용하였고, Objaverse 데이터를 random HDRI environment lighting 를 적용하여 렌더링한 데이터에 학습하였습니다. 그리고 Stable Diffusion Image Variations model 의 학습 방식을 도입하여 two-stage 로 학습을 진행하였습니다.
첫번째 phase 에서는 self-attention layer 와 cross-attention layer 의 KV 행렬만 fine-tuning 을 하였고, AdamW optimizer 와 cosine annealing schedule 을 사용하였습니다. 두번째 phase 에서는 UNet 모델 전체를 학습하고 \(5 \times 10^{-6}\) 값의 constant learning rate 를 사용하였습니다. 그리고 학습 과정을 더 효율적으로 하기 위해 Min-SNR weighting 기법도 활용하였습니다.
3. Comparison to the State of the Art#
3.1. Image to Multi-view#
Qualitative Comparison
논문에서 Zero-1-to-3 XL 그리고 SyncDreamer 모델과의 성능을 비교합니다. Zero123++ 모델이 unseen view 에 대해서 가장 월등하게 이미지를 생성하는 것을 확인할 수 있습니다.

Fig. 750 Qualitative comparison on image to multi-view task#
Quantitative Comparison
정량적으로 LPIPS 지표를 기준으로 비교하였을 때에도 Zero123++ 모델이 가장 좋은 성능을 보여주고 있습니다. 이때, 모델이 생성된 6개의 이미지와 Objaverse 데이터셋을 렌더링한 6개의 이미지를 각각 결합하여 LPIPS 를 측정하였다고 합니다.
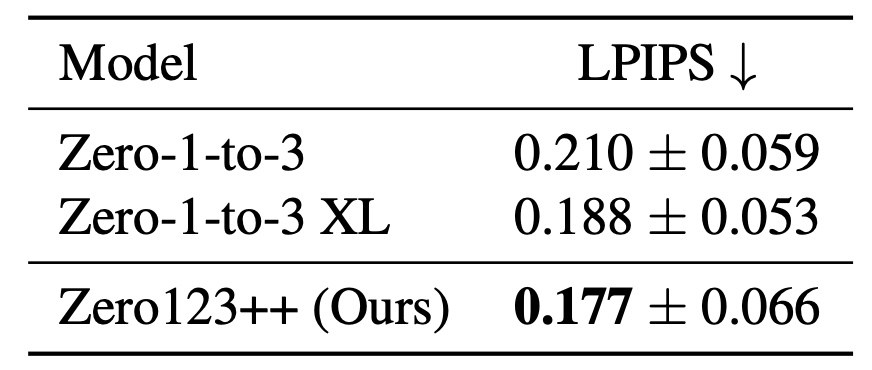
Fig. 751 Quantitative Comparison on image to multi-view task#
3.2. Text to Multi-view#
Text 를 입력받아 우선적으로 SDXL 모델을 통해 단일 이미지를 생성한 후, Zero123++ 모델을 적용한 결과입니다. MVDream 과 Zero-1-to-3 XL 모델과 비교하였을 때, Zero123++ 모델이 가장 realistic 하고 multi-view consistent 한 이미지를 생성하는 부분을 확인할 수 있습니다.

Fig. 752 Qualitative comparison on text to multi-view task#
4. Depth ControlNet for Zero123++#
아래 사진은 추가적으로 렌더링한 depth map 를 기반으로 ControlNet 을 학습한 결과입니다.

Fig. 753 Depth-controlled Zero123++#