Information
Title: Synthetic Data with Stable Diffusion for Foliar Disease Classification
Author: Jisu Kim
Last updated on Jul. 05, 2023
Synthetic Data with Stable Diffusion for Foliar Disease Classification#
1. 개요#
사과 나무의 잎에 생기는 질병을 이미지로 판별하는 Kaggle competition (링크)에서 아이디어를 얻어서 진행한 프로젝트입니다.
해당 competition은 사과나무 잎에 걸린 질병에 따라 잎 이미지를 4개의 class로 분류하는 task입니다.

Fig. 848 4 classes of leaves#
competition을 설명한 article (링크)에서 전체적인 accuracy는 97%이지만 multiple diseases class의 경우 accuracy가 51%에 불과했다고 언급합니다.
multiple diseases class의 이미지 개수가 다른 class에 비해 적은 점에 주목했고, stable diffusion을 사용하여 해당 클래스의 데이터 개수를 늘려서 classifier 학습에 사용하면 더 좋은 성능의 classifier를 얻을 수 있을 것으로 기대했습니다.
2. Baseline 구축#
문제 상황을 재현하기 위해 기존 데이터로 image classifier를 학습하여 baseline으로 잡았습니다.
모델은 pretrained된 ResNet18에 linear layer를 붙여서 사용했습니다.
전체 accuracy는 97.7%, class별 accuracy는 healthy: 99.6%, multiple diseases: 73.6%, rust: 99.2%, scab: 98.1%
multiple diseases class는 이미지 개수 91개로 다른 클래스들에 비해서 개수가 적습니다.
class별 data imbalance가 성능을 낮추는 원인일 것이라 가정하고 stable diffusion으로 multiple diseases class의 data를 추가로 생성해보기로 했습니다.
multiple diseases class 예시

Fig. 849 4 classes of leaves#
3. Stable diffusion fine tuning#
pretraned stable diffusion의 경우 multiple diseases class에 대한 정보가 없어서 이미지를 생성할 경우 아래와 같이 관련없는 이미지가 생성됩니다.

Fig. 850 prompt: “a photo of leaves with multiple diseases#
따라서 stable diffusion model (링크)에 해당 class에 대한 정보를 넣어주기 위해 dreambooth (링크)를 사용하여 stable diffusion을 fine tuning했습니다.
training에 사용한 prompt는 “a photo of a <diseaes-leaf> leaf”이며, 생성한 이미지의 예시는 아래와 같습니다.
생성 이미지 예시

Fig. 851 prompt: “a photo of a <diseaes-leaf> leaf”#
prompt engineering을 수행하던 중 의도하지않은 결과를 발견했습니다.
아래는 이에 대한 예시로 fine tuning 전의 stable diffusion model의 결과와 비교입니다.
상황1 (prompt: “a photo of a leaf”)

Fig. 852 fine tuning 전#

Fig. 853 fine tuning 후#
상황1을 보면 multiple diseases class 정보를 담은 unique identifier <diseaes-leaf>가 없음에도 multiple diseases의 정보를 담은 잎들만 생성됩니다. 이는 같은 class (leaf)에 속하는 다른 이미지들을 생성해내지 못하고 있다는 것입니다. 이 현상을 language drift라고 하며, 모델이 multiple diseases class의 leaf가 아닌 일반적인 leaf class에 관한 정보를 잊어버렸기 때문입니다.
상황2 (prompt: “a photo”)

Fig. 854 fine tuning 전#

Fig. 855 fine tuning 후#
상황2를 보면 photo라는 prompt만 사용하였는데도 생성한 이미지들에 multiple diseases class의 특징들이 나타납니다.
dreambooth에서는 language drift를 prior preservation loss를 사용해서 해결하였으므로 같은 방법을 사용했습니다. 상황2를 해결하기 위해 training prompt에서 “photo”를 제외하고 최대한 단순한 prompt “<diseases-leaf> leaf”를 사용하여 stable diffusion model을 다시 fine tuning했습니다.

Fig. 856 multiple diseases class 이미지 생성 결과, prompt: “<diseaes-leaf> leaf”#

Fig. 857 leaf 생성 결과, prompt: “leaf”#
재훈련 결과, fine tuning 이후에도 기존 stable diffusion model로 “leaf”를 생성하였을 때와 비슷한 이미지가 생성됩니다.

Fig. 858 photo 생성 결과, prompt: “photo”#
“photo”의 경우에는 여전히 multiple diseases class의 영향을 받은 것같은 이미지들이 생성됩니다. photo의 경우에는 여러 대상들과 사용되는 일반적인 특성을 가지고있어서 그런 것이라는 생각이 들었고, 이를 체크해보기 위해 특정한 대상들과 photo와 비슷한 용도로 사용되는 다른 prompt들로 이미지들을 생성보았습니다.
특정한 대상 세가지로는 cat, sea, pirate을 사용했고, photo와 비슷하게 사용되는 텍스트 세가지는 illustration, animation, wallpaper를 사용했습니다. (이미지는 글 마지막 부분의 appendix에 있습니다.)
이미지 생성 결과, 특정한 대상을 지칭하는 텍스트의 경우 대상의 특징이 잘 드러나는 이미지가 생성되었지만, 여러 대상과 함께 쓰이는 텍스트의 경우 잎사귀의 특징을 가지는 이미지들이 일부 생성되었습니다.
4. 성능 비교#
fine tuning한 stable diffusion model로 multiple diseases class의 이미지를 400장 생성하여 classifier를 다시 훈련했습니다.
baseline
전체 accuracy는 97.7%, class별 accuracy는 healthy: 99.6%, multiple diseases: 73.6%, rust: 99.2%, scab: 98.1%
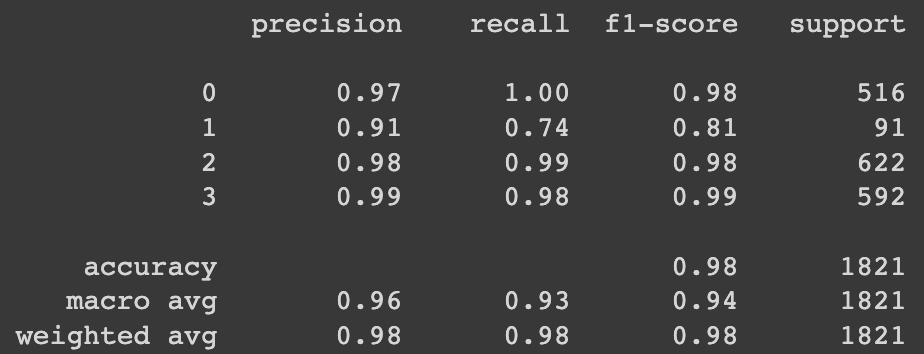
Fig. 859 result_base#
생성한 이미지를 추가 데이터로 활용한 경우
전체 accuracy는 97.9%, class별 accuracy는 healthy: 98.1%, multiple diseases: 84.6%, rust: 98.2%, scab: 99.3%
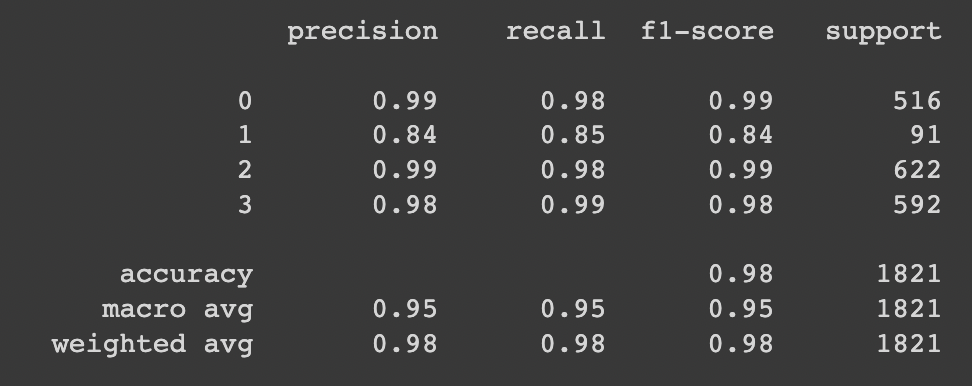
Fig. 860 result_now#
kaggle에서 제공하는 test set에 적용했을 때는 baseline이 94.6%, stable diffusion으로 생성한 이미지들을 사용한 경우가 93.7%여서 baseline보다 좋은 성능을 얻지는 못 했습니다.
5. Discussion#
stable diffusion 훈련 중간중간에 일정 step마다 이미지를 생성하게해서 훈련에 대한 모니터링이 있으면 좋겠다는 생각을 했습니다.
stable diffusion 훈련시 hyperparameter tuning을 좀 더 철저하게 해야겠다는 생각을 했습니다.
stable diffusion으로 생성한 이미지가 실제로 multiple diseases class 조건을 만족하는지 검수할 방안이 필요합니다.
multiple diseases 내에서도 카테고리를 나눌 수 있다면 나눠서 각각에 대한 stable diffusion model을 fine tuning할 수도 있을 것입니다.
다른 diffusion model fine tuning 방법을 활용해볼 수도 있을 것입니다.
submission score에서 baseline을 이기지 못 했지만 text-to-image model을 이용한 synthetic data의 가능성을 볼 수 있었다고 생각합니다.
6. Appendix#
앞에서 언급한 prompt에 대한 이미지 생성 예시입니다. 일부 이미지는 NSFW로 판단되어 검은색으로 나왔습니다.

Fig. 861 cat 생성 결과, prompt: “cat”#

Fig. 862 sea 생성 결과, prompt: “sea”#

Fig. 863 pirate 생성 결과, prompt: “pirate”#

Fig. 864 illustration 생성 결과, prompt: “illustration”#
Fig. 865 animation 생성 결과, prompt: “animation”#

Fig. 866 wallpaper 생성 결과, prompt: “wallpaper”#