Information
Title: One-Step Image Translation with Text-to-Image Models
Reference
Code: GaParmar/img2img-turbo
Author: Sangwoo Jo
Last updated on Sep. 24, 2024
One-Step Image Translation with Text-to-Image Models#
1. Introduction#
논문에서 기존의 conditional diffusion model 에 대해 다음과 같이 1) slow inference time, 2) paired data 에 대한 의존성 두 가지 한계점을 명시합니다. 이를 보완하기 위해, paired setting 과 unpaired setting 에서 모두 적용 가능한 학습 아키텍쳐를 제시합니다.
기존에 adapter 를 추가하는 방식은 one-step diffusion model 에 적합하지 않다고 설명하고, 또한 SD-Turbo 모델의 Encoder-UNet-Decoder 형태의 multi-stage pipeline 에서 이미지의 많은 시각적 디테일이 손실된다고 주장합니다. 그리고 이러한 정보 손실은 입력 이미지가 실제 이미지일 때 특히 더 치명적이라고 합니다.
이를 보완하기 위해, 논문에서는 첫번째로 input image 를 직접 noise encoder 에 입력함으로써 noise map 과 input control 의 충돌을 방지합니다. 두번째로, Encoder-Unet-Decoder 를 하나의 end-to-end 로 학습 가능한 아키텍처를 정의하고, 이를 위해 여러 LoRA adapter 를 정의합니다. 마지막으로, high-frequency detail 을 담아내기 위해 encoder 와 decoder 간의 skip connection 을 추가합니다.
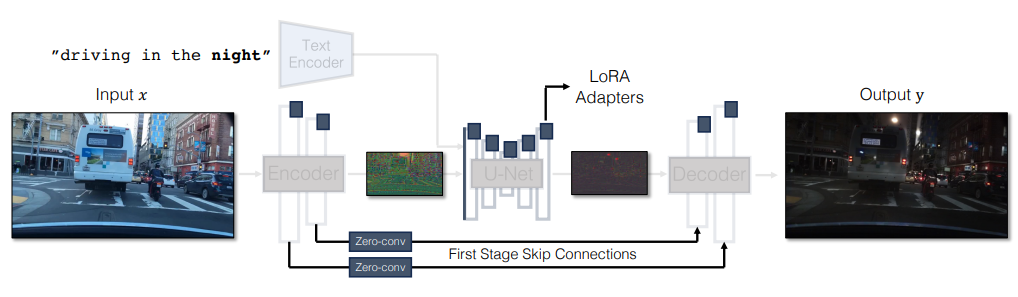
Fig. 541 Overall Architecture#
CycleGAN-Turbo 코드
class CycleGAN_Turbo(torch.nn.Module): def __init__(self, pretrained_name=None, pretrained_path=None, ckpt_folder="checkpoints", lora_rank_unet=8, lora_rank_vae=4): super().__init__() self.tokenizer = AutoTokenizer.from_pretrained("stabilityai/sd-turbo", subfolder="tokenizer") self.text_encoder = CLIPTextModel.from_pretrained("stabilityai/sd-turbo", subfolder="text_encoder").cuda() self.sched = make_1step_sched() vae = AutoencoderKL.from_pretrained("stabilityai/sd-turbo", subfolder="vae") unet = UNet2DConditionModel.from_pretrained("stabilityai/sd-turbo", subfolder="unet") vae.encoder.forward = my_vae_encoder_fwd.__get__(vae.encoder, vae.encoder.__class__) vae.decoder.forward = my_vae_decoder_fwd.__get__(vae.decoder, vae.decoder.__class__) # add the skip connection convs vae.decoder.skip_conv_1 = torch.nn.Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda() vae.decoder.skip_conv_2 = torch.nn.Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda() vae.decoder.skip_conv_3 = torch.nn.Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda() vae.decoder.skip_conv_4 = torch.nn.Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda() vae.decoder.ignore_skip = False self.unet, self.vae = unet, vae
또한, 해당 논문에서 제시하는 아케텍쳐는 CycleGAN, pix2pix 등의 GAN 기반의 모델에 plug-and-play 형태로도 적용 가능하며, CycleGAN-Turbo, pix2pix-Turbo 모델이 기존의 GAN 기반 그리고 diffusion model 기반 모델의 image translation 성능보다 우수하다고 합니다.
3. Method#
3.1. Adding Conditional Input#
SD-Turbo 와 같이 pretrained 된 one-step text-to-image 모델을 기반으로 input image 에 대한 conditioning 을 하는 방법을 다음과 같이 처음에 제안합니다. 아래 사진과 같이, 사전학습된 stable diffusion encoder 의 가중치 혹은 랜덤한 가중치를 가진 adapter 를 새로 정의하여 input image 에 대한 feature map 을 추출합니다.

Fig. 542 Adding Conditional Input#
하지만 multi-step diffusion model 과 다르게 single-step 만으로도 noise map 이 생성되는 이미지의 전체적인 layout 을 결정하기 때문에, condition encoder 를 거쳐서 나온 feature map 와의 충돌이 생겨 학습에 어려움이 생기는 현상을 보여준다고 합니다.
따라서, adapter 를 추가적으로 정의하는 방식이 아닌 conditioning input 을 network 에 직접 적용하는 방식을 논문에서 제안합니다.
3.2. Preserving Input Details#
Latent Diffusion Model (LDM) 이 image 를 encoding 하는 과정에서 차원을 8 배 축소하기 때문에 정보에 대한 손실이 크고, 따라서 이러한 방식은 fine detail 에 민감한 image translation task 에 적합하지 않을 수 있다고 주장합니다. 아래 사진을 보시면, 기존 아키텍쳐에서 skip connection 을 추가하기 전후로 원본 이미지에 대한 detail preservation 정도 차이를 확인할 수 있습니다.

Fig. 543 Preserving Input Details#
더 자세하게는, skip connection 을 encoder 내의 각 downsampling layer 를 거쳐 4개의 activation 을 추출하고 이를 1 x 1 zero-convolution layer 를 통과시켜 decoder 에 대응되는 upsampling block 에 입력시킵니다.
3.3. Unpaired Training#
논문에서는 SD-Turbo (v2.1) 를 base network 로 사용하고, 변형된 CycleGAN objective 를 적용하여 unpaired translation 을 진행하였습니다. 이때, cycle-consistency loss 와 adversarial loss 를 다음과 같이 정의합니다.
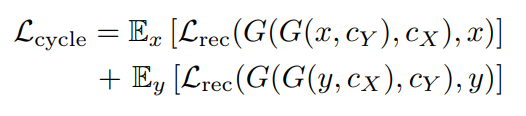
Fig. 544 Cycle-Consistency Loss#
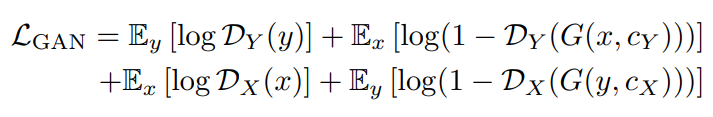
Fig. 545 Adversarial Loss#
여기서 \(X \subset \mathbb{R}^{H \times W \times 3}\), \(Y \subset \mathbb{R}^{H \times W \times 3}\) 는 각각 source domain, target domain, 그리고 \(G(x, c_Y): X → Y\), \(G(y, c_X): Y → X\) 는 translation 함수입니다. 두 translation 모두 동일한 generator \(G\) 를 사용하며, caption \(c_X,c_Y\) 만 task 에 따라 변형하게 됩니다. (i.e., day → night translation task 에서 \(c_X\) 는 “Driving in the day” 그리고 \(c_Y\) 는 “Driving in the night”)
대부분의 layer 는 고정시킨 상태에서 U-Net 의 첫번째 convolutional layer 와 LoRA adapter 를 학습시켰다고 합니다.
Fig. 546 Overall Architecture#
또한, 새롭게 소개되는 \(L_{rec}\) 손실함수는 \(L_1\) 과 \(LPIPS\) 의 조합으로 구성되어있습니다. 그리고 adversarial loss 에서 사용되는 discriminator \(D_X(x),D_Y(y)\) 는 CLIP 모델을 backbone 으로 사용하였습니다.
마지막으로, identity regularization loss 도 \(L_{idt} = E_y [L_{rec}(G(y, c_Y ), y)] + E_x [L_{rec}(G(x, c_X), x)]\) 와 같이 정의하고, 최종 objective 를 이들의 가중치 합으로 정의합니다.
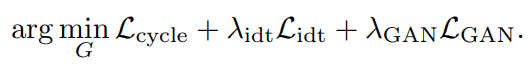
Fig. 547 Full objective#
3.4. Extensions#
해당 논문에서 unpaired training setting 뿐만 아니라 paired training 그리고 stochastic output generation 에 대해서도 실험을 진행하였습니다.
Paired Training
Paired setting 에서는 single translation function \(G(x,c): X \rightarrow Y\) 를 학습하고, objective 는 (1) perceptual loss 와 pixel-space reconstruction loss 로 구성된 reconstruction loss (2) unpaired setting 에서 target domain 에 대해서만 정의된 GAN loss, 그리고 (3) CLIP text-image alignment loss \(L_{CLIP}\) 의 가중치 합으로 정의합니다.
Generating Diverse Outputs
One-step model 로 diverse 한 output 을 생성하는 것은 어려운 일입니다. 논문에서는 해당 task 를 수행하기 위해 input image \(x\), noise map \(z\), 그리고 interpolation coefficient \(\gamma\) 를 입력받는 \(G(x,z,\gamma)\) 를 정의합니다.
\(G(x,z,\gamma)\) 는 우선 noise \(z\) 와 encoder output \(G_{enc}(x)\) 를 다음과 같이 interpolation 합니다: \(\gamma G_{enc}(x) + (1 − \gamma) z\). 그리고 LoRA adapter 가중치와 skip connection 출력값을 \(\theta = \theta_0 + \gamma \cdot \Delta \theta\) 와 같이 조정합니다. 여기서 \(\theta_0\) 는 원래 가중치이고, \(\Delta \theta\) 는 새로 추가된 가중치입니다.
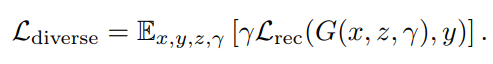
Fig. 548 Reconstruction loss with interpolation coefficient#
해당 objective 로 interpolation coefficient \(\gamma\) 를 변화시키면서 모델을 fine-tuning 함으로써 다양한 output 을 생성할 수 있었다고 합니다.
4. Experiments#
Training Details
학습하는 파라미터: LoRA 가중치, zero-convolutional layer, 그리고 첫번째 U-Net convolutional layer 가 330MB 소요됩니다.
UNet initialization 코드
def initialize_unet(rank, return_lora_module_names=False): unet = UNet2DConditionModel.from_pretrained("stabilityai/sd-turbo", subfolder="unet") unet.requires_grad_(False) unet.train() l_target_modules_encoder, l_target_modules_decoder, l_modules_others = [], [], [] l_grep = ["to_k", "to_q", "to_v", "to_out.0", "conv", "conv1", "conv2", "conv_in", "conv_shortcut", "conv_out", "proj_out", "proj_in", "ff.net.2", "ff.net.0.proj"] for n, p in unet.named_parameters(): if "bias" in n or "norm" in n: continue for pattern in l_grep: if pattern in n and ("down_blocks" in n or "conv_in" in n): l_target_modules_encoder.append(n.replace(".weight","")) break elif pattern in n and "up_blocks" in n: l_target_modules_decoder.append(n.replace(".weight","")) break elif pattern in n: l_modules_others.append(n.replace(".weight","")) break lora_conf_encoder = LoraConfig(r=rank, init_lora_weights="gaussian",target_modules=l_target_modules_encoder, lora_alpha=rank) lora_conf_decoder = LoraConfig(r=rank, init_lora_weights="gaussian",target_modules=l_target_modules_decoder, lora_alpha=rank) lora_conf_others = LoraConfig(r=rank, init_lora_weights="gaussian",target_modules=l_modules_others, lora_alpha=rank) unet.add_adapter(lora_conf_encoder, adapter_name="default_encoder") unet.add_adapter(lora_conf_decoder, adapter_name="default_decoder") unet.add_adapter(lora_conf_others, adapter_name="default_others") unet.set_adapters(["default_encoder", "default_decoder", "default_others"]) if return_lora_module_names: return unet, l_target_modules_encoder, l_target_modules_decoder, l_modules_others else: return unet
VAE initialization 코드
def initialize_vae(rank=4, return_lora_module_names=False): vae = AutoencoderKL.from_pretrained("stabilityai/sd-turbo", subfolder="vae") vae.requires_grad_(False) vae.encoder.forward = my_vae_encoder_fwd.__get__(vae.encoder, vae.encoder.__class__) vae.decoder.forward = my_vae_decoder_fwd.__get__(vae.decoder, vae.decoder.__class__) vae.requires_grad_(True) vae.train() # add the skip connection convs vae.decoder.skip_conv_1 = torch.nn.Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True) vae.decoder.skip_conv_2 = torch.nn.Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True) vae.decoder.skip_conv_3 = torch.nn.Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True) vae.decoder.skip_conv_4 = torch.nn.Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True) torch.nn.init.constant_(vae.decoder.skip_conv_1.weight, 1e-5) torch.nn.init.constant_(vae.decoder.skip_conv_2.weight, 1e-5) torch.nn.init.constant_(vae.decoder.skip_conv_3.weight, 1e-5) torch.nn.init.constant_(vae.decoder.skip_conv_4.weight, 1e-5) vae.decoder.ignore_skip = False vae.decoder.gamma = 1 l_vae_target_modules = ["conv1","conv2","conv_in", "conv_shortcut", "conv", "conv_out", "skip_conv_1", "skip_conv_2", "skip_conv_3", "skip_conv_4", "to_k", "to_q", "to_v", "to_out.0", ] vae_lora_config = LoraConfig(r=rank, init_lora_weights="gaussian", target_modules=l_vae_target_modules) vae.add_adapter(vae_lora_config, adapter_name="vae_skip") if return_lora_module_names: return vae, l_vae_target_modules else: return vae
Datasets
Unpaired datasets 에서 자주 사용되는 Horse \(\leftrightarrow\) Zebra, Yosemite Summer \(\leftrightarrow\) Winter, 그리고 고차원 이미지의 주행 데이터셋 BDD100k 의 day \(\leftrightarrow\) night, clear \(\leftrightarrow\) foggy 데이터셋으로 실험하였습니다.
Evaluation Protocol
Image translation task 에서 다음과 같은 2가지 요소를 만족시켜야 한다고 합니다.
(1) target domain 의 데이터셋 분포와의 일치: FID 로 측정
(2) input image 의 구조적인 정보 유지: DINO-Struct-Dist 로 측정
4.1. Comparison to Unpaired Methods#
기존에 GAN-based 그리고 Diffusion-based 모델들이 output realism 그리고 structure preservation 에 모두 좋은 성능을 내지는 못하는 것을 확인할 수 있습니다.

Fig. 549 Comparison to baselines on 256 × 256 datasets.#

Fig. 550 Comparison to baselines on driving datasets (512 × 512).#
아래 예시 사진들과 table 에서 보이듯이, CycleGAN-Turbo 모델이 CycleGAN 과 CUT 모델보다 더 낮은 FID, DINO Structure score 를 보여주는 것을 확인할 수 있습니다.
또한, diffusion 기반의 zero-shot image translation 모델: SDEdit, Plug-and Play, pix2pix-zero, CycleDiffusion, 그리고 DDIB 들이 realistic 한 이미지는 잘 생성하지만 원본 이미지의 structure 를 훼손시키는 경우가 있음을 확인할 수 있습니다. 이러한 현상은 multiple object 가 존재하는 주행 데이터셋에서 더 빈번하게 발생하고, 이는 Instructpix2pix 모델을 제외하고는 noise map 으로 inverting 하는 과정에서 원본 이미지에 대한 손실이 일어나기 때문이라고 주장합니다.
Comparison to GAN-based methods

Fig. 551 Comparison to GAN-based methods on 256 × 256 datasets.#

Fig. 552 Comparison to GAN-based methods on driving datasets (512 × 512).#
Comparison to Diffusion-based editing methods

Fig. 553 Comparison to Diffusion-based editing methods on driving datasets (512 × 512).#

Fig. 554 Comparison to Diffusion-based editing methods on driving datasets (512 × 512).#
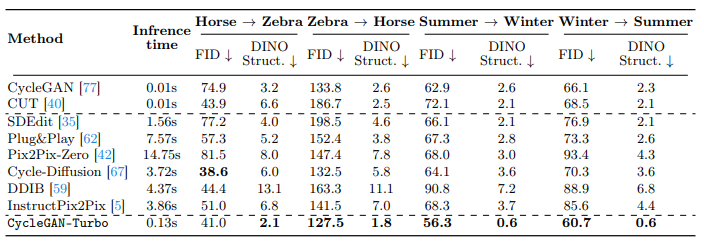
Fig. 555 Evaluation on standard CycleGAN datasets (256 × 256).#
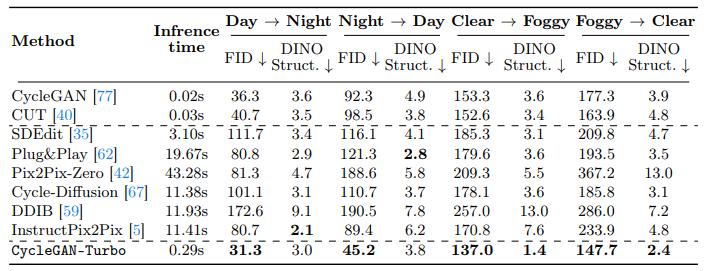
Fig. 556 Comparison on 512 × 512 driving datasets.#
4.2. Ablation Study#
Using pre-trained weights
랜덤한 가중치로 초기화하는 것보다 pre-trained 된 모델을 사용할 때, 모델 성능이 더 좋은 것을 확인할 수 있습니다.
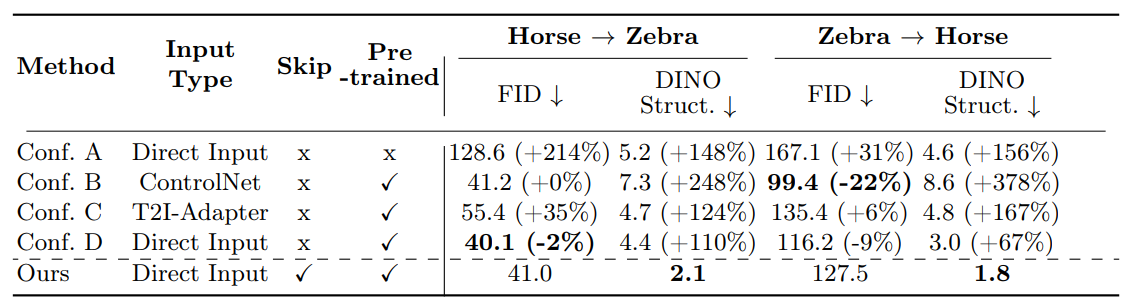
Fig. 557 Ablation with Horse to Zebra#
Different ways of adding conditioning inputs
ControlNet 이나 T2I-Adapter 를 사용하여 conditioning 할 때, 원본 이미지와의 structure 충돌이 일어나는 부분을 재차 확인할 수 있습니다.

Fig. 558 Ablating individual components#
Skip Connections and trainable encoder and decoder
Config D 와 비교하였을 때, FID 에 대한 성능이 미세하게 떨어지는 반면에 structure preservation 성능이 월등히 높음을 확인할 수 있습니다.
4.3. Extensions#
Paired translation
Pix2pix-Turbo 와 LCM-ControlNet, SD-Turbo ControlNet, 그리고 SD ControlNet 모델과 정성적인 평가를 진행하였습니다. Classifier-free guidance, negative prompt 없이 단일 step 만으로도 좋은 성능을 보여줌을 확인할 수 있습니다.

Fig. 559 Comparison on paired edge-to-image task (512 × 512).#
Generating diverse outputs

Fig. 560 Generating diverse outputs#
5. Discussions and Limitations#
해당 논문은 multi-step diffusion training 에 의존하지 않고, single-step 만으로 다양한 GAN 기반의 objective 와 융합해서 downstream task 에 적용할 수 있는 방식을 제안합니다. 하지만, 다음과 같은 3가지 한계점을 제시합니다: (1) SD-Turbo 는 classifier-free guidance 를 사용하지 않아, guidance control 에 대한 설정할 수 없습니다. (2) 해당 방식은 negative prompt 를 지원하지 않습니다. 그리고 마지막으로 (3) high capacity generator 기반의 cycle consistency loss 로 학습하는데 메모리에 대한 부담이 큽니다.