Information
Title: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Reference
Author: Jun-Hyoung Lee
Last updated on May. 31. 2023
SDXL#
Abstract#
SDXL은 T2I latent diffusion 모델이다. Stable Diffusion과 비교하면, SDXL은 세 배 더 큰 규모의 UNet을 포함한다. 더 많은 attention 블록과 더 큰 cross attention context 가 SDXL에서 두 번째 text encoder로 사용되면서 모델 파라미터가 증가했다. 다수의 새로운 conditioning 방법과 다양한 비율에 맞도록 SDXL을 학습할 수 있도록 설계했다. 또한 후처리 방식의 image to image 기술을 사용해 SDXL의 생성 샘플의 시각적인 fidelity를 향상시킨 refinement model을 소개한다. SDXL은 대폭 향상된 성능을 보여준다.

Fig. 239 SDXL result#
Introduction#
세 가지 주요 기능이라 볼 수 있는데,
3배 더 큰 UNet backbone,
어떤 형태의 추가 감독(supervision)없는 간단하면서도 효과적인 추가의 conditioning 기술
noising-denoising 과정을 적용해 시각적 품질을 향상하는 latent를 생성할 수 있는 별개의 diffusion 기반 img-to-img refinement 모델을 포함한다.
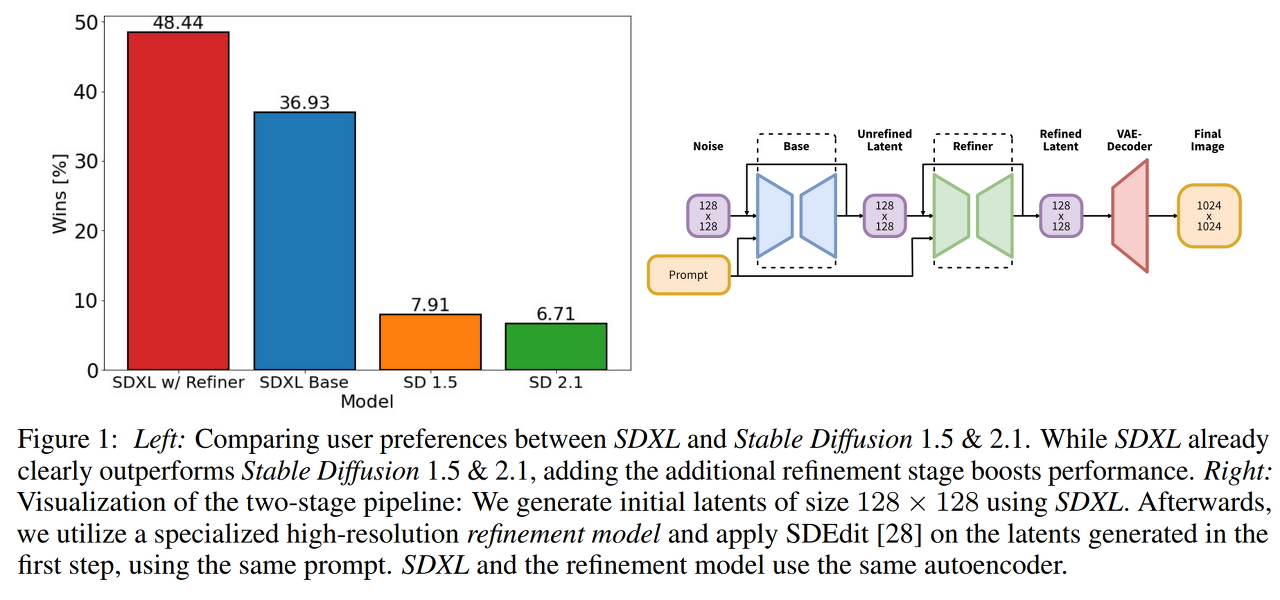
Fig. 240 Figure 1#
그림 1에서 왼쪽 그림을 보면 추가의 refinement 단계를 추가해 성능을 높인 SDXL이 기존 SD보다 성능이 우수한 것을 확인할 수 있다. 오른쪽 그림은 아키텍처를 시각화했는데, 128x128 크기의 latent를 생성한다. 그 후 고해상도 refinement 모델을 활용하고 동일한 프롬프트를 활용해 첫 번째 단계에서 생성된 latent를 SDEdit을 적용한다. SDXL과 refinement 모델은 동일한 autoencoder를 사용한다.

Fig. 241 Table 1#
SD와 다르게 UNet 내의 transformer 블록의 heterogeneous 분포를 사용했다는 점이다. 테이블 1을 참고하면 highest feature level에서 transformer 블럭을 사용했고, lower level에서는 2, 10 개의 블럭을 사용했고, UNet에서 lowest level(8x downsampling)을 제거했다. text conditioning을 위한 pretrained 된 text encoder를 사용했다. 특히, CLIP Vit-L과 함께 OpenCLIP ViT-bigG를 사용했고, 채널 축에 두 번째 text encoder의 output을 concat 했다. 게다가 text input으로 모델에 condition을 주기 위해 cross attention 레이어를 사용했으며, 또 OpenCLIP로부터 pooled text embedding을 모델에 condition으로 추가했다. 이러한 변화는 UNet의 파라미터 사이즈가 2.6B로 증가했다. text encoder는 817M 파라미터를 가지고 있다.
2.2 Micro-Conditioning#
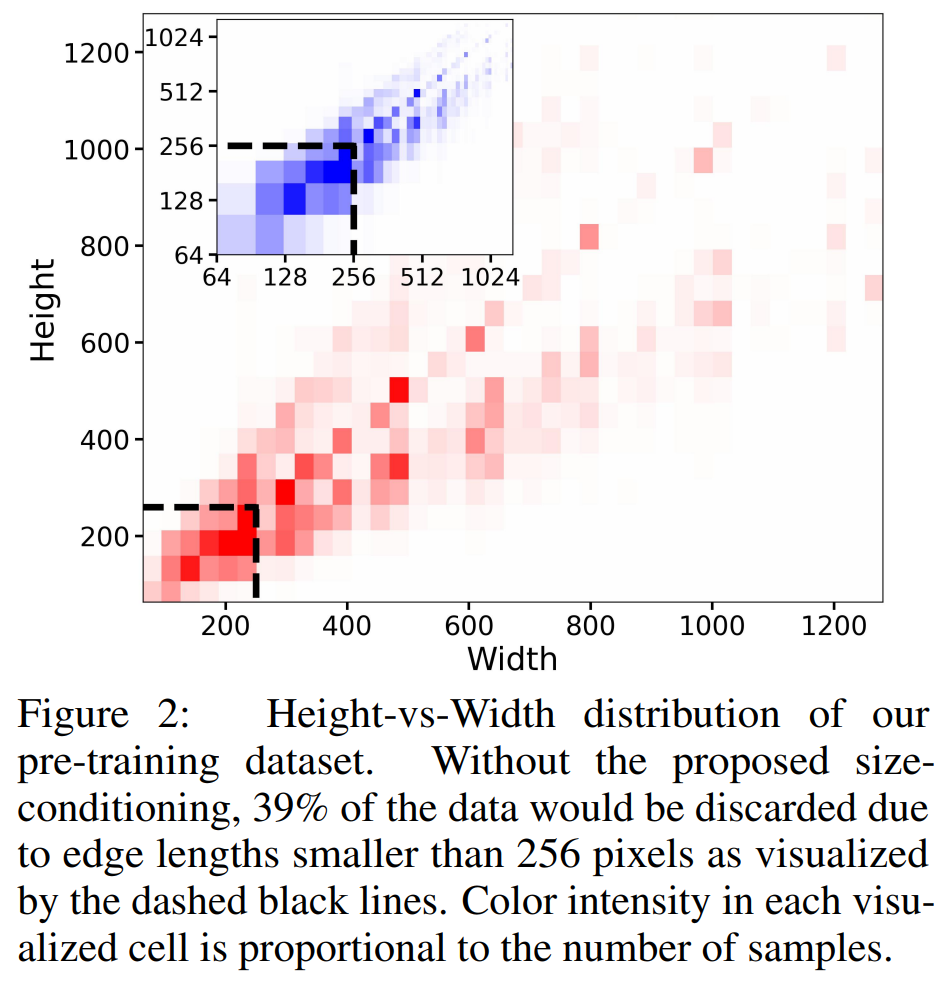
Fig. 242 Figure 2#
SD 1.4/1.5 같은 경우 512 픽셀 이하 크기의 이미지는 제외하고 학습을 시키거나, 너무 작은 이미지는 upscale하여 학습을 시켰다. 이는 학습할 때의 최소 크기가 정해지는 문제점이 발생한다. 따라서 성능을 저하시키거나, 일반화를 잘 못할 수 있다.
그림 2를 보면 SDXL의 데이터 셋의 분포를 시각화해주는 그림이다. 제안된 size-conditiong 없이, 256x256 픽셀 크기 미만의 데이터가 39%나 달한다. upscale 하게 된다면 최종 결과물이 blur 한 결과를 가져와 좋지 않은 아티팩트가 생긴다.
대신, 저자들은 원래의 이미지 해상도에서 UNet 모델에 condition을 주었다. 특히 어떠한 rescaling 전의 원래의 크기인 \(c_\text{size}=(h_\text{original}, w_\text{original})\)를 제공해 추가의 condition을 줄 수 있게 했다. UNet의 denoising 할 때의 condition으로 추가된다.
Inference 때, 사용자가 size-conditioning을 통해 해상도를 정할 수 있다. 모델은 conditioning 크기를 해상도에 의존적인 이미지 feature과 연관시키도록 하는 방법을 학습했다.

Fig. 243 Figure 3#
또 ImageNet으로 평가를 진행해 size-conditiong에 대한 우수성을 입증했다.
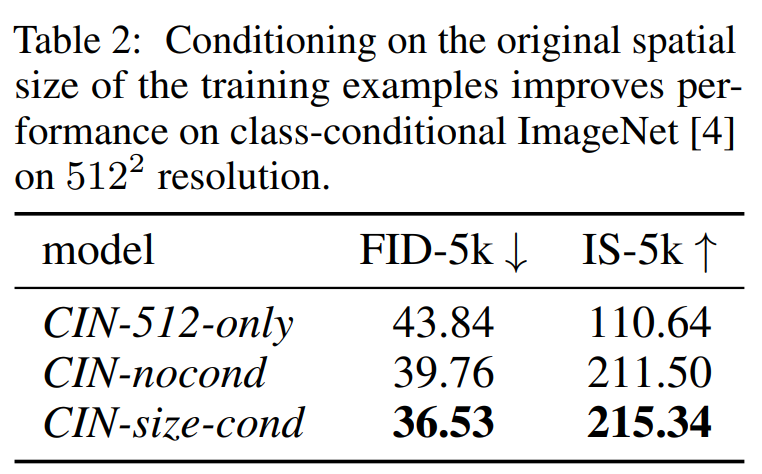
Fig. 244 Table 2#
CIN-512-only 는 512 미만의 이미지를 제외하고 학습을 시켰고(70k 장), CIN-nocond 는 모든 ImageNet 이미지를 사용했으며, CIN-size-cond 는 추가 size-condition을 사용했다. 표 2에서 보다시피 CIN-size-cond 모델이 FID, IS 모두 높은 성능을 보였다.
Conditioning the Model on Cropping Parameters#

Fig. 245 Figure 4#
그림 4에서 SD 같은 경우 고양이 머리가 잘려진 결과를 얻었다. 이러한 이유는 학습할 때, random cropping으로 인해 생성되었기 때문이다.
이러한 문제를 해결하기 위해, 간단한 효과적인 방법을 제안한다. 데이터를 loading 할 때, 균등하게 \(c_\text{top}\)과 \(c_\text{left}\) (높이 및 너비 축을 따라 왼쪽 상단 모서리에서 잘린 픽셀의 양을 지정하는 정수)를 샘플링한다. 그 후 Fourier feature 임베딩을 통해 conditioning 파라미터로써 모델에 입력한다. 위에서 언급한 size conditioning과 비슷하다. concat 된 임베딩 \(c_\text{crop}\)은 추가의 conditioning 파라미터로 사용된다.
저자들은 LDM 뿐만 아니라 어떠한 DM에서도 사용될 수 있다고 강조한다. crop 및 size-conditioning은 쉽게 결합될 수 있다. 이러한 경우, crop 및 size-conditioning을 feature 임베딩을 채널 축에 concat 하고 UNet의 타임스텝 임베딩에 추가한다.
2.3 Multi-Aspect Training#
일반적인 T2I 모델에서 결과물의 크기는 512x512, 1024x1024 로 얻을 수 있는데, 이는 현실 세계에서 부자연스럽다. 이유는 현실 세계에서는 다양한 크기, 비율을 가진 이미지가 많고, 풍경 같은 경우 16:9 비율의 크기를 지니고 있다.
따라서, 다양한 비율을 동시에 다룰수 있도록 모델을 파인튜닝했다. 픽셀수를 1024x1024 만큼 수를 최대한 유지하면서 다양한 비율의 데이터를 사용했고, 64의 배수를 지니도록 했다.
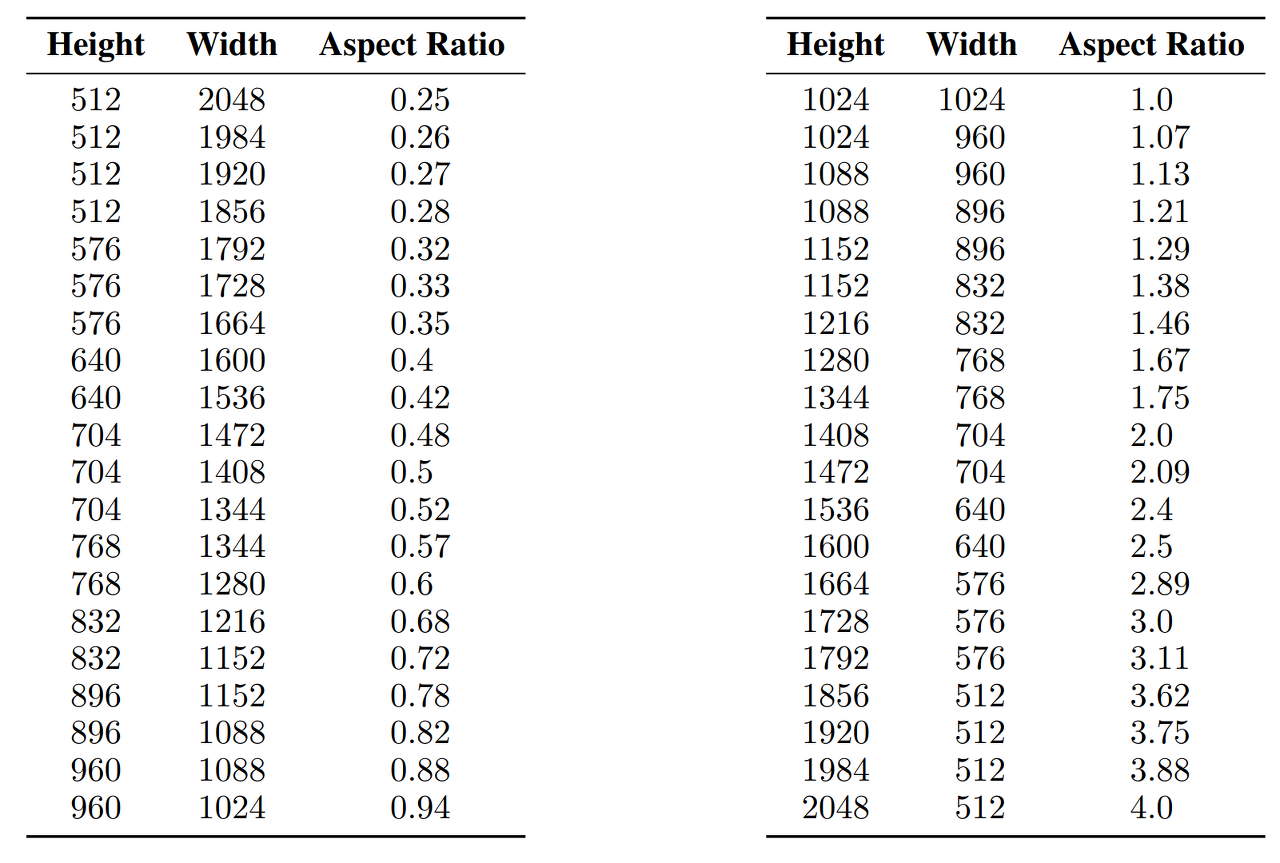
Fig. 246 Multi aspect ratio#
최적화 동안, 학습 배치는 동일한 버킷(같은 비율의 이미지들?)의 이미지로 구성되며, 각 훈련 스텝마다 버킷 크기를 번갈아 가며 사용했다. 추가적으로, 모델은 버킷 크기(혹은 타겟 크기)를 conditioning으로 주었으며, 위에서 언급한 size, crop conditioning과 유사하게 Fourier 공간에 임베딩되는 \(c_\text{ar}=(h_\text{tgt}, w_\text{tgt})\) 형태로 표현된다.
실제로, 모델이 고정된 비율및 해상도의 데이터로 pretraining이 마친 후 파인튜닝 단계에서는 다양한 비율의 데이터로 학습했고, 채널 축으로 concat 하는 2.2절에서 소개한 conditioning 기술과 함께 결합했다. 이를 아래의 그림 16에서 코드로 확인할 수 있다.
2.4 Improved Autoencoder#
SD는 LDM 중 하나이고, autoencoder의 latent space를 학습한다. semantic composition은 LDM으로부터 표현되지만 저자들은 local, high frequency 디테일한 부분을 향상하고자 autoencoder를 향상했다. 끝으로, 원래의 SD를 사용한 autoencoder 아키텍처에서 더 큰 배치사이즈(256 vs 9)로 학습했고 추가로 exponential moving average를 사용한 가중치를 사용했다. 결과 autoencoder의 성능이 reconstruction 메트릭에 좋은 결과를 가져왔다.
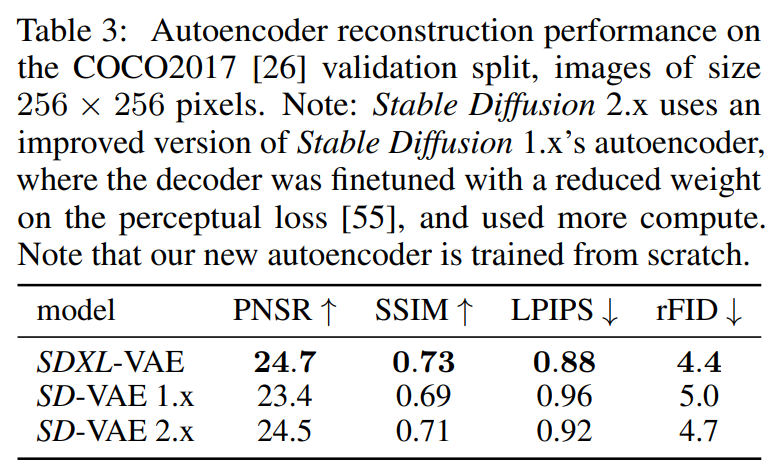
Fig. 247 Table 3#
2.5 Putting Everything Together#
학습 파라미터를 정리해주는 절입니다. diffusion time step은 1000 step을 사용했다. 우선, base model를 내부 데이터 셋으로 그림 2에 나와있는 높이-너비 분포에 맞게 학습을 시켰다. 600,000 step을 사용했으며, 256x256 사이즈로, 배치는 2048로, size & crop conditioning을 사용했다. 그 후 512x512 이미지를 추가로 200,000 최적화 step으로 학습시켰고, 마침내 offset 노이즈 [11, 25] 0.05 수준과 함께 다중 비율 학습을 활용하여 ~ 1024x1024 영역의 다양한 비율로 모델을 학습했다.
Refinement Stage#

Fig. 248 Figure 6#
경험적으로, 그림 6처럼 특정 부분 퀄리티가 낮은 샘플의 결과를 찾았다. 왼쪽 그림이 refinement stage 적용 전, 오른쪽 그림이 refinement stage를 적용한 그림이다.
이를 해결하기 위해, 고품질, 고해상도 데이터에 특화된 latent space 내에서 별도의 LDM을 학습했다. 기본 모델의 샘플에 대해 SDEdit에서 도입한 노이즈 제거 과정을 사용했다. eDiff-I 방법을 따랐으며, 이를 첫 200 노이즈 스케일에 refinement 모델을 사용했다. inference에서, base SDXL에서 latent를 추출하고 바로 diffuse와 denoise를 refinement 모델에 넣었다. 이 스텝은 선택이지만 배경 및 사람 얼굴과 같은 디테일에서 향상된 결과(그림 6, 13)를 얻을 수 있었다.

Fig. 249 Figure 13#