Information
Title: Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Reference
Author: Jun-Hyoung Lee
Last updated on Oct. 15. 2023
CM3leon#

Fig. 305 CM3leon result#
복잡하게 구성된 객체(손, 텍스트)도 잘 생성한다.
Abstract & 1. Introduction#
CM3Leon
텍스트와 이미지 둘 다 잘 생성하는 능력을 가진 검색-증강, 토큰 기반, 디코더 전용 멀티 모달 모델이다.
CM3 멀티 모델 아키텍처를 사용하며 scaling up 및 다양한 구조적-스타일 데이터에 tunning 할 수 있는 능력을 가졌다.
Training
처음에는 멀티 모달 모델을 “텍스트 기반” language 모델에 맞도록 학습했다. (large scale의 검색 증강 pretraining 단계를 포함한다.)
데이터는 라이센스가 있는 Shutterstock의 large-scale로 학습한다.
그 후 supervised fine tuning (SFT) 단계로 진행했다.
입력과 출력 모두 이미지와 텍스트 토큰을 섞을 수 있다.
기존 이미지 생성 모델은 텍스트 프롬프트에 맞는 이미지만 잘 생성하는데,
CM3leon은 텍스트와 이미지 모두 잘 생성한다.
이미지 생성
고해상도 output을 생성할 수 있는 self-contained contrastive decoding 방법을 소개한다.
text guided iamge editing 부터 image controlled generation, segmentation까지 가능하다.
텍스트 생성
Shutterstock의 3억 개의 텍스트 토큰으로 학습했는데, image-to-text generation도 잘 수행한다.
학습 연산을 5배로 줄였다.
zero shot COCO로 FID를 측정한 결과 4.88 점으로, Google의 Parti 모델의 성능과 비슷한 수준을 달성했다.
2. Pretraining#
RA-CM3를 기반으로 T2I 도메인에서 토큰 기반 디코더 모델의 잠재력을 연구했다.
2.1 Data#
Image Tokenization#
Gafni의 image tokenizer를 사용했다.
이 tokenizer는 256x256 이미지를 8192개의 vocabulary에서 1024개의 토큰으로 인코딩을 진행한다.
텍스트에서는, Zhang의 커스텀 tokenizer(56320 vocabulary size)를 학습했다.
추가로, 새로운 스페셜한 토큰인 **
<break>**을 소개한다.
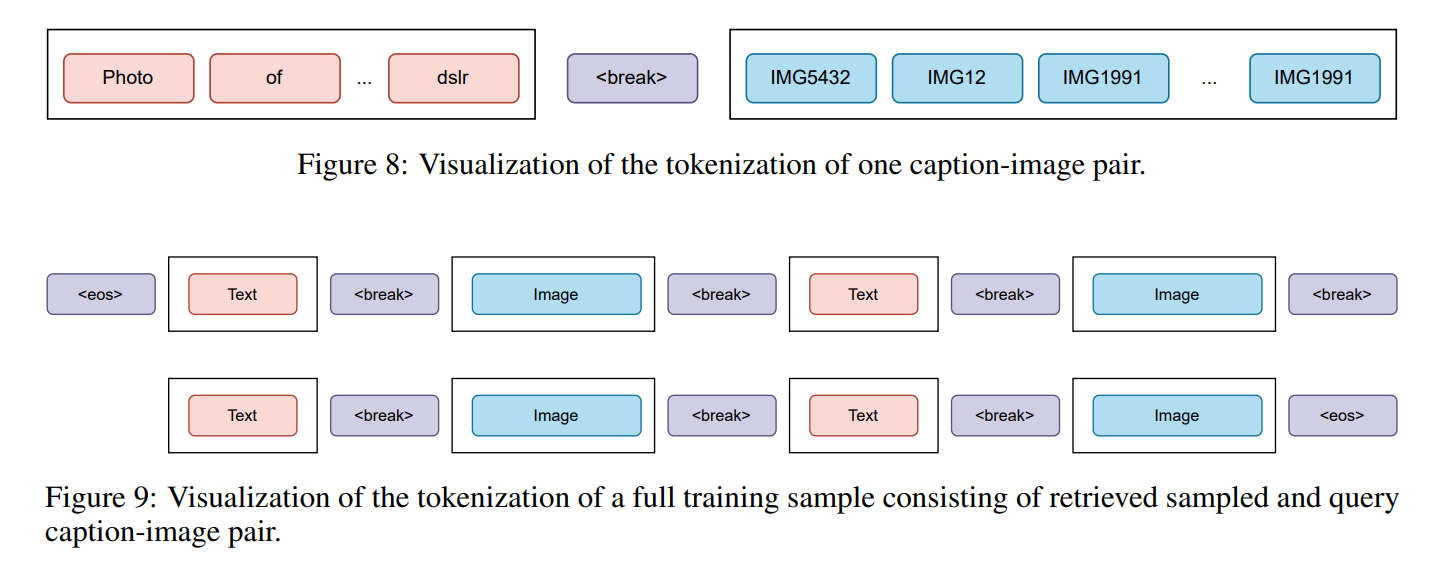
Fig. 306 Figure_8_9#
- 이는 modality간 transition을 하게 한다.
Retrieval Augmentation#
목적: 입력 sequence에 맞춰 관련성이 높고 다양한 멀티 모달 문서(from memory bank)를 검색하는 것이다.
dense retriever 와 retrieval strategy을 포함하고 있다.
dense retriever
쿼리 \(q\) (예: input sequence)와 memory bank \(\mathcal M\) 로부터 후보 문서 \(m\) 를 가지고 관련성 점수\(r(q, m)\) 를 return 해준다.
dense retriver 방법은 CLIP 기반인 bi-encoder 구조를 따랐다. (Karpukhin)
멀티 모달 문서를 text / image 파트로 분리하고, 각각 CLIP 인코더(ViT-B-32)를 통해 인코딩을 한다.
그 후 문서의 vector representation로써 두 개를 평균을 낸다.
최종 검색은 관련성 점수에 따라 정렬된 후보 문서 목록을 얻기 위해 Maximum Inner Product Search로 수행한다.
학습 때 generator를 위한 유용한 검색 문서를 추출하기 위해 세 가지 요소를 고려했다.
relevance
검색된 문서는 입력 sequence에 관련있어야 한다.
CLIP 기반 dense retriever 점수를 사용한다.
modality
이미지와 텍스트로 구성된 멀티 모달 문서로 검색 > 이미지 또는 텍스트로 검색하는 것이다.
diversity
다양성은 검색된 문서에서 중복성을 피하기 위한 필수적인 절차다.
단순하게 관련성 점수에 기반해 top K 문서만 가져온다면 중복이 발생할 수 있다.
또한 downstream pretraining 에 안좋은 영향을 끼칠 수 있다.
실제로, 관련성 점수가 0.9 이하로 검색된 문서로 사용했고,
query dropout(검색에 사용된 쿼리의 일부 20% 토큰을 삭제)를 적용했다.
따라서 다양성과 학습에 정규화를 시켰다.
이미지와 텍스트를 기반으로 각각 두 개의 문서를 검색한다.
학습에서는 데이터셋의 모든 캡션-이미지 쌍에 대해 검색된 샘플 3개를 무작위로 선택한다.
이는 사실상 사전 학습에서 사용할 수 있는 토큰 수의 4배이다.
2.2 Objective Function#
CM3 objective
input
"Image of a chameleon: [image]"을 변형시켜"Image of <mask>: [image] <infill> a chameleon”로 표현한다. :<mask>, <infill>이 추가되었고, 단어의 재배치가 진행됐다.
학습에는 일반적인 다음 토큰을 예측하는 loss를 사용했다.
그 결과 이미지, 텍스트 둘 다 생성하는 다용도 모델의 결과를 가져왔다.
caption-to-image generation에서는 CM3가 “Image of a chameleon:” 프롬프트로 부터 이미지를 생성하고,
image-to-caption generation에서는 CM3는
“Image of <mask>: [image] <infill>”프롬프트를 활용한다.
2.3 Model#
CM3Leon 모델은 디코더만 사용하는 transformer 아키텍쳐를 사용한다.
Zhang에 비해 bias term, dropout, layer norm의 학습 가능한 파라미터를 제거했다.
sequence length를 2048 → 4096까지 확장했다.
weight 초기화: 평균 0, 표준 편차 0.006 인 truncated(표준 편차 3으로 잘린) normal distribution 사용했다.
output layer: 0으로 초기화, 0에 가까운 표준 편차 0.0002로 positional embedding 초기화한다.
Metaseq로 학습됐다.
2.4 Training#
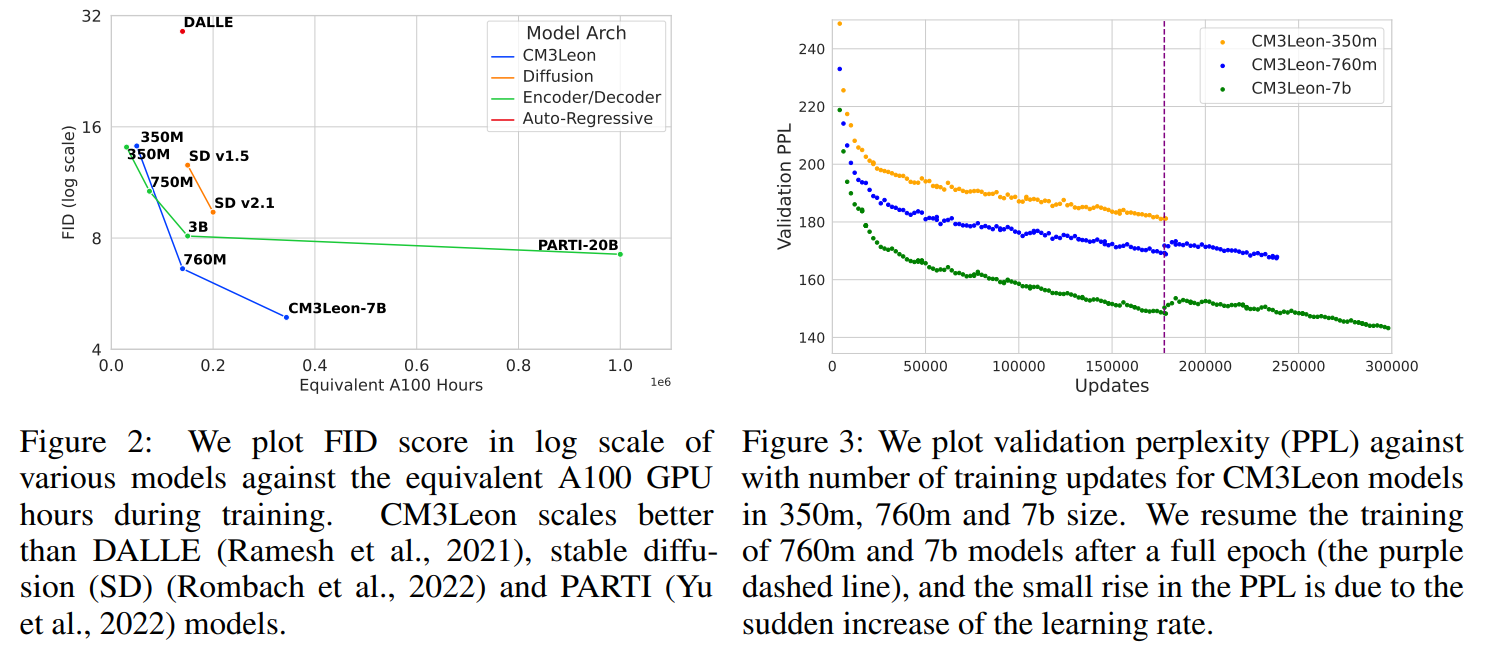
Fig. 307 Training result#
세 가지 모델 사이즈(350M, 760M, 7B)로 학습 진행했다. (→ 1.4T(Trillion), 1.9T, 2.4T tokens)
주요한 하이퍼 파라미터는 learning rate, batch size로 멀티모달 scaling 에 맞게 설정했다.
참고
Perplexity, PPL: 언어 모델의 평가 방법 중 하나이다. (헷갈리는 정도, 값이 낮을 수록 좋다.)
3. Text-To-Image Results#
3.1 Importance of Decoding Strategies#
autoregressive T2I 모델에서 decoding 알고리즘에 대해 상당한 연구가 진행되어 왔다.
그 중 DALL-E는 최종 아웃풋의 퀄리티가 향상되는 결과를 가져왔다.
DALL-E 는 temperature 샘플링과 512개 후보 프롬프트에 CLIP re-ranking 전략을 채택했다.
PARTI 와 Make-A-Scene 과 같은 모델은 토큰 기반의 classifier-free guidance로, re-ranking에 대해 오직 16 개의 샘플만 필요하게 됨으로써 후보의 수를 줄였다.
Temperatured Sampling#
autoregressive 모델에서 확률적 기술로 사용된다.
이 방법은 샘플링에서 softmax의 temperature를 수정해 예측 무작위성을 제어한다.
Classifier Free Guidance 적용했다.
TopP Sampling#
nucleus 샘플링으로도 불리고, 미리 정의한 임계값을 초과하는 누적 확률을 가진 가장 작은 상위 토큰 세트에서 샘플링을 포함한다.
Classifier Free Guidance 적용했다.
Classifier Free Guidance (CFG)#
CFG는 unconditional 샘플을 conditional 샘플에 맞도록 하는 것을 의미한다.
unconditional 샘플을 text를 CM3 목표의 마스크 토큰으로 대체한다.
이는 CM3 목표를 사용한 학습의 핵심 이점 중 하나이며, finetuning 없이, classifier 없는 guidance를 수행할 수 있다.
추론에서는 두 개의 토큰 stream을 생성한다.
입력 텍스트에 따라 달라지는 토큰 stream과
mask 토큰에 따라 condition된 unconditional 토큰 stream
Contrastive Decoding TopK (CD-K)#
CFG에서 logit의 뺄셈 연산이 텍스트에서 contrastive decoding 방법의 log probability를 뺄셈하는 연산과 비슷하다.
3.2 Quantitative Evaluation#

Fig. 308 Evaluation#
MS-COCO (30K) zero shot 예측, FID 측정했다.
CM3Leon-7B 모델이 FID 4.88 점으로 가장 좋다.
retrieval-augmented decoder-only 모델의 효율성이 좋다.
CM3Leon-7B 모델이 추론에서 1개/2개로 검색된 예제로 동작할 때 우수한 FID 점수를 기록했다.
이는 고품질 이미지를 생성하는 능력을 확장시키는 검색의 중요성을 보여준다.
4. Supervised Fine-Tuning#
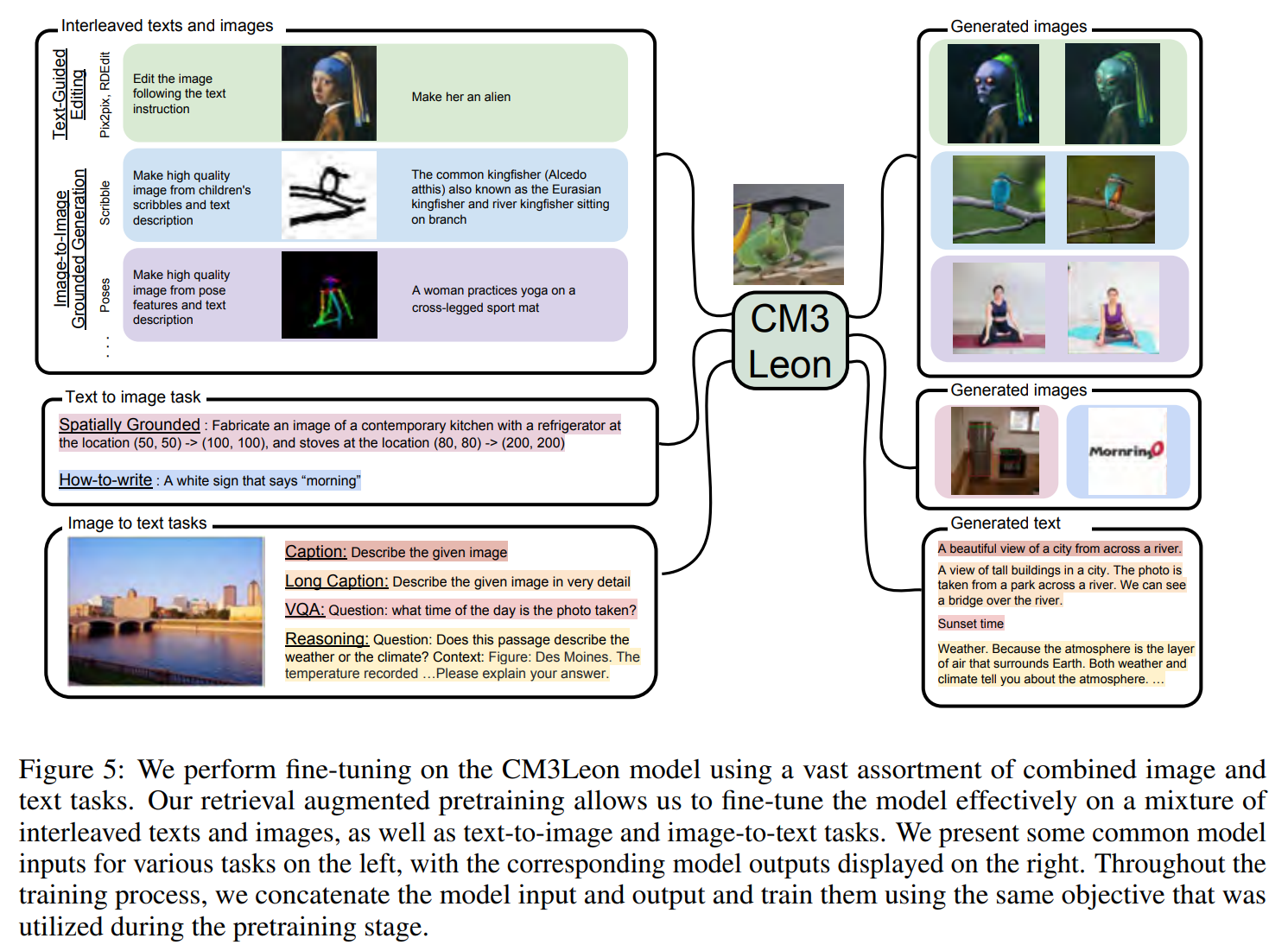
Fig. 309 Figure5#
Supervised fine-tuning (SFT)는 LLM에서 중요한 학습 단계이다.
명령어 또는 프롬프트를 잘 이해하는 것을 도와주며, zero shot task에서도 향상되는 결과를 얻었다.
명령어 튜닝이 다양한 task에 멀티모달 모델 성능을 눈에 띄게 증폭시키는 것을 발견했다.
CM3Leon을 이미지와 텍스트 task를 섞어 넓은 범위에서 fine tuning 했다.
finetuning 과정은 pretraining 단계를 따르며, task instruction과 출력을 결합해 동일한 CM3 objective를 사용한다.
4.1 Instructable Image Generation#

Fig. 310 Figure6#
Text-Guided Image Editing#
text instruction 에 기반한 initial image를 수정하는 task이다.
InstructPix2Pix 방법 사용했다.
예시: “하늘의 색을 파란색으로 변경해줘”와 같은 프롬프트로 이미지 편집이 가능하다.
이것은 CM3leon이 텍스트와 이미지를 동시에 이해하고 있어서 가능하다.
Image-to-Image Grounded Generation#
다양한 feature과 텍스트 프롬프트로 grounding image를 생산하는 task이다.
ControlNet 적용했다.
Spatially Grounded Image Generation#

Fig. 311 Figure6-1#
이미지 생성에 있어서 공간적 정보(위치)를 텍스트 프롬프트에 통합시킬 수 있도록 하는 task이다.
Image captioning & visual question answering task#

Fig. 312 Figure16#
Flamingo(1000억 토큰), OpenFlamingo(400억 토큰)에 비해 CM3leon(30억 토큰)은 적은 토큰임에도 불구하고, 동등한 성능을 달성했다.