Information
Title: LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Reference
Code: Official
Author: Donghyun Han
Last updated on Oct. 02, 2024
LCM-LoRA#
Proposal#
Latent Consistency Models(LCMs)에 Low Rank Adaptation (LoRA)을 적용하였다.
LoRA를 이용하여 Stable Diffusion에 대한 추가적인 학습 없이도 fine-tuning 가능. (Accelerate 효과 극대화)
이전의 다양한 PF-ODE (Probability-Flow ODE) solver를 사용한 방법론들보다 더 generalized 된 성능
1. Introduction#
기존 연구의 한계점#
Latent Diffusion Models(LDMs)은 image generation 분야에서 좋은 성능을 보이고 있다. 그러나 아직까지는 느린 reverse process 때문에 사용자가 직접 사용하기에는 무리가 있다. 따라서 LDMs을 가속화(Accelerate)하기 위한 기법들이 제안되어 왔는데 크게 2가지로 나눌 수 있다:
DDIM, DPM-Solver, DPM-Solver++ 등 ODE-Solver 기반 방법론.
LDM을 경량화 하기 위한 Distillation 기반 방법론.
ODE-Solver 방법론은 sampling step을 줄일 수 있지만 Classifier-free Guidance(CFG) 등을 사용할 때 Computation 적으로 Overhead가 있을 수 있다. Distillation 방법론 또한 Distillation 시 Computation적으로 Overhead가 있어 한계가 있다. ex)Guided Distill : 2 stage의 distillation 방식 + high resolution image 생성 한계
LCMs 기반 연구#
이에 반해 Consistency Models(CMs)에서 영감을 받은 Latent Consistency Models(LCMs)은 매우 좋은 대안이다. backward process를 augmented Probability Flow ODE(PF-ODE) problem으로 접근하여 반복적인 step을 획기적으로 줄일 수 있었다. LCMs은 1~4 step만으로도 높은 퀄리티의 고해상도 이미지를 생성해낼 수 있으며 큰 리소스가 필요하지 않다.
그러나 LCMs을 기반으로 하는 방법론은 새로운 데이터셋에 대해 finetuning이 필요하거나 pretrained LDMs을 필요로 하는 한계가 존재한다.
따라서 본 연구는 추가 학습없이 Stable Diffusion(SD)이나 SD-LoRA 등에 plug-in 해서 사용할 수 있는 LCM-LoRA를 제안한다. LCM-LoRA는 새로운 종류의 neural network 기반 PF-ODE Solver이며, 강력한 일반화 성능을 보여준다.
2. Related Work#
Consistency Models#
CMs은 sampling step을 획기적으로 줄이면서도 Quality를 유지할 수 있는 방법론이다.
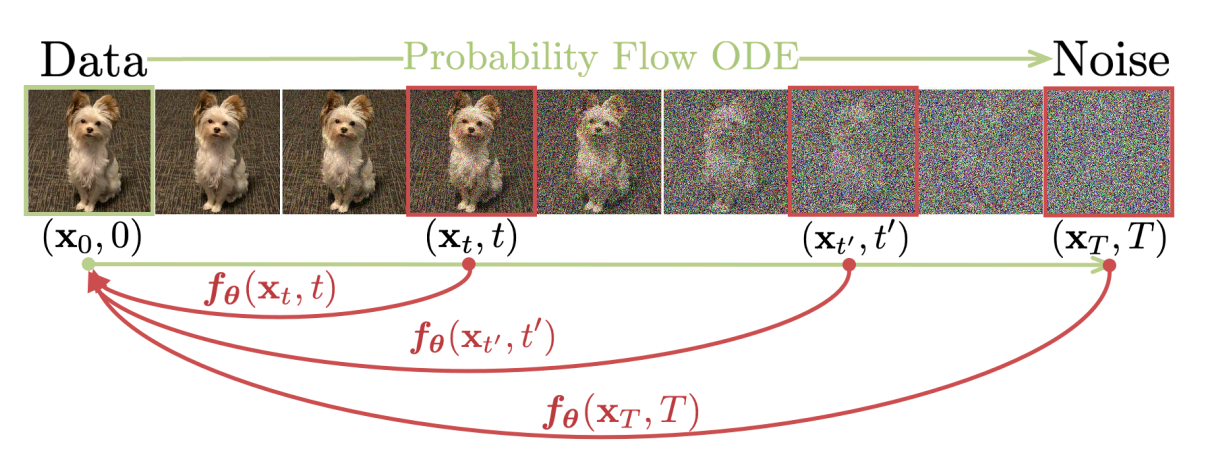
Fig. 561 Consistency Models#
CMs의 핵심은 PF-ODE의 궤적의 points가 solution에 mapping 되는 function \((f: (x_t,t) \mapsto x_\epsilon)\)을 추정하는 것이다. 쉽게 말해 어떤 step의 noise image 던지 \(x_0\) (정확히는 \(x_\epsilon\))의 결과가 나오는 function을 추정한다. 또한 각 timestep에 관한function의 결과값은 self-consistency를 만족해야 한다.
\(\epsilon\)은 매우작은 양수 값이다. 이때 \(f_\theta(x,\epsilon)=x\)를 만족하는 model \(f_\theta\)는 다음과 같이 정의한다:
\(c_{skip}(\epsilon)=1\), \(c_{out}(\epsilon)=0\) 이기 때문에 \(f_\theta(x,\epsilon)=x\)를 만족한다. 위 수식은 미분 가능함을 증명하기 위한 수식이다. \(F_\theta\)는 심층신경망을 의미한다.
CMs은 scratch부터 학습하는 방식과 Distillation 방식으로 나뉘는데 보편적으로 Distillation이 사용된다. Distillation 방식은 지수평균이동(Exponential Moving Average, EMA)를 통해 self-consistency를 학습할 수 있다:
\(\theta^-\)는 \(\theta\)에 대한 EMA를 의미하며 \(d(\cdot, \cdot)\)은 두 sample 사이의 거리를 측정하는 지표이다. \(\hat{x}^{\phi}_{t_n}\)는 \(x_{t_{n+1}}\)에 대한 \(x_{t_n}\)을 추정한 값으로 다음과 같다:
\(\Phi\)는 numerical PF-ODE를 의미한다. (보통 DDIM을 사용하는 것 같다) 즉 \(x_{t_n}\)을 PF-ODE로 예측한 값을 입력으로 하는 예측값과 \(x_{t_{n+1}}\)을 입력으로 하는 예측값이 같도록 self-consistency를 비교하는 것이 핵심이다.
Latent Consistency Models#
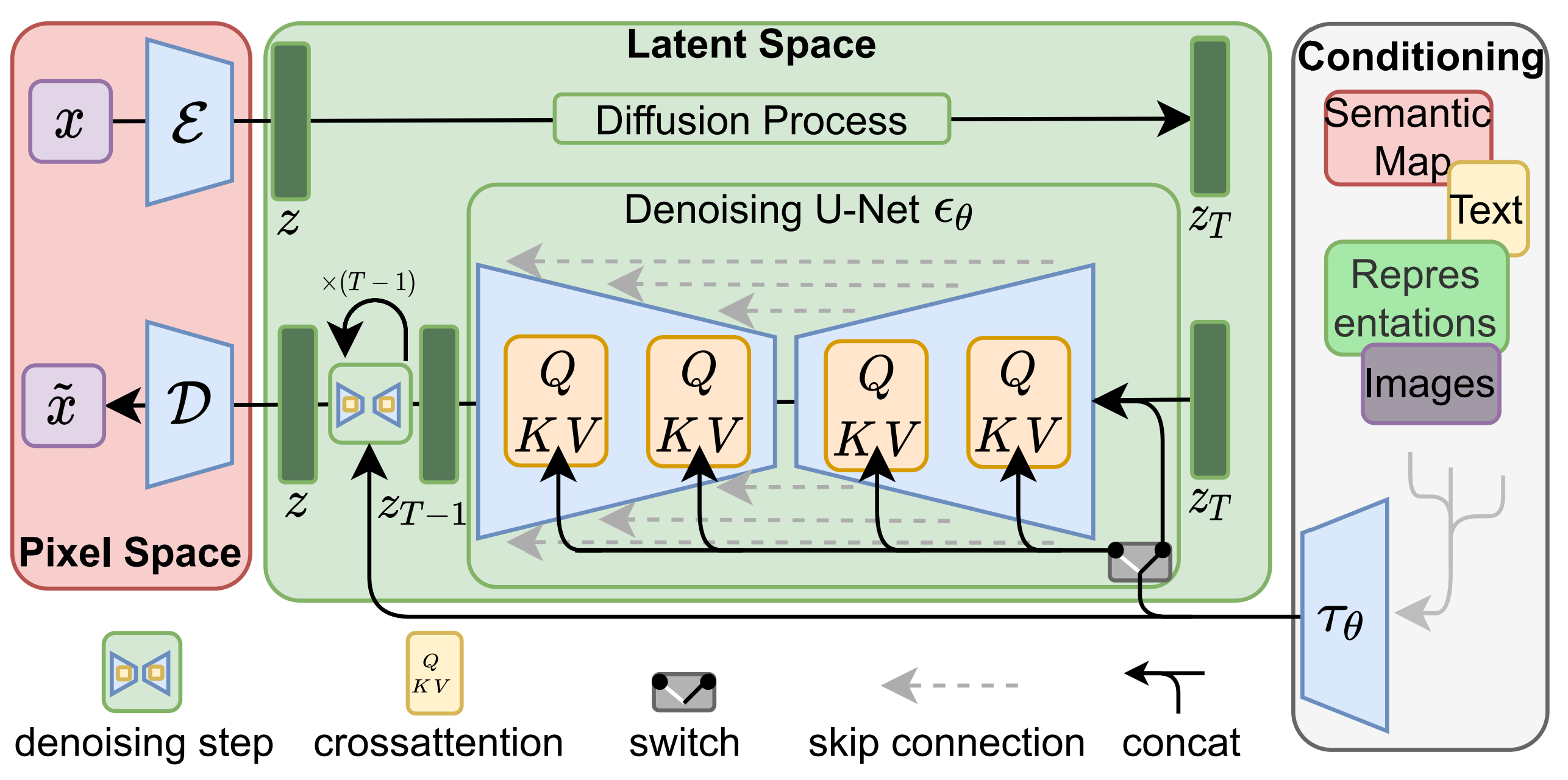
Fig. 562 Latent Diffusion Models#
LCMs은 CMs에 condition을 추가해주고 \(F_\theta(x,t)\)를 \(\epsilon-Prediction\)의 수식으로 치환한다. (\(\mu\)나 \(v\) prediction을 사용해도 됨.) 추가로 LDMs 기반이기 때문에 latent \(z\)에 대한 수식으로 변경해준다.
\(n\)은 timestep이지만 기존\(t\)와는 다른 timestep \([t,T]\)에 대한 하위 간격이다. \((t_1=\epsilon<t_2<...<t_N=T)\)
CMs과 차이점#
LDMs 기반 모델이다.
LCMs는 CMs와 다르게 Classifier-free Guidance(CFG)를 포함한 Distillation도 정의되어있다.(\(\tilde{\epsilon}_\theta\))
LCMs는 \(t_n\)과 \(t_{n+1}\)의 차이가 너무 적어 학습의 수렴이 늦어지게 된다 가정하고 \(t_n\)과 \(t_{n+k}\)의 consistency를 비교하는 Skipping timestep 방법을 제시했다. (k는 trade-off를 가지며 최적의 값은 20으로 지정.)
Latent Consistency Finetuning: 새로운 데이터셋에 대해 distillation할 때 LDMs를 학습 할 필요 없이 LCMs의 Consistency Distillation만 학습하여 사용할 수 있다.
(자세한 내용은 LCMs review를 참고)
Parameter-Efficient Fine-Tuning#
Parameter-Efficient Fine-Tuning(PEFT)이란 파라미터를 효율적으로 사용하면서 fine-tuning 할수 있는 연구를 의미한다. Knowledge Distillation, Pruning, Quantization 등이 있다.
본 연구에서는 PERF 기법 중 RoLA를 사용했다.
Low Rank Adaptation#
기존에 pre-trained 된 가중치 \(\Phi_0\)에 대하여 새로운 task에 fine-tuning하는 모델 \(P_\Phi(y|x)\)는 다음과 같이 가중치가 업데이트 된다. (\(\Phi_0+\Delta\Phi\))
LLM이나 Stable Diffusion과 같은 대규모 모델은 새로운 task로 fine-tuning 시 매우 큰 차원의 모델 파라미터를 다시 학습하기 때문에 매우 큰 Cost가 생긴다. (시간적, 자원적) 이때 weight의 차원은 줄이면서 변화량을 기록하는 또다른 weight를 만들어 더 효율적으로 계산하는 방식은 다음과 같이 나타낼 수 있다: (파라미터 \(\Theta\)에 대해 \(\Delta\Phi=\Delta\Phi(\Theta), |\Theta|<<|\Phi_0|\))
즉 기존의 잘 학습된 weight는 그대로 두고 low rank로 decomposition 된 weight만 optimization 하는 방법론을 Low Rank Adaptation(LoRA)라고 한다.
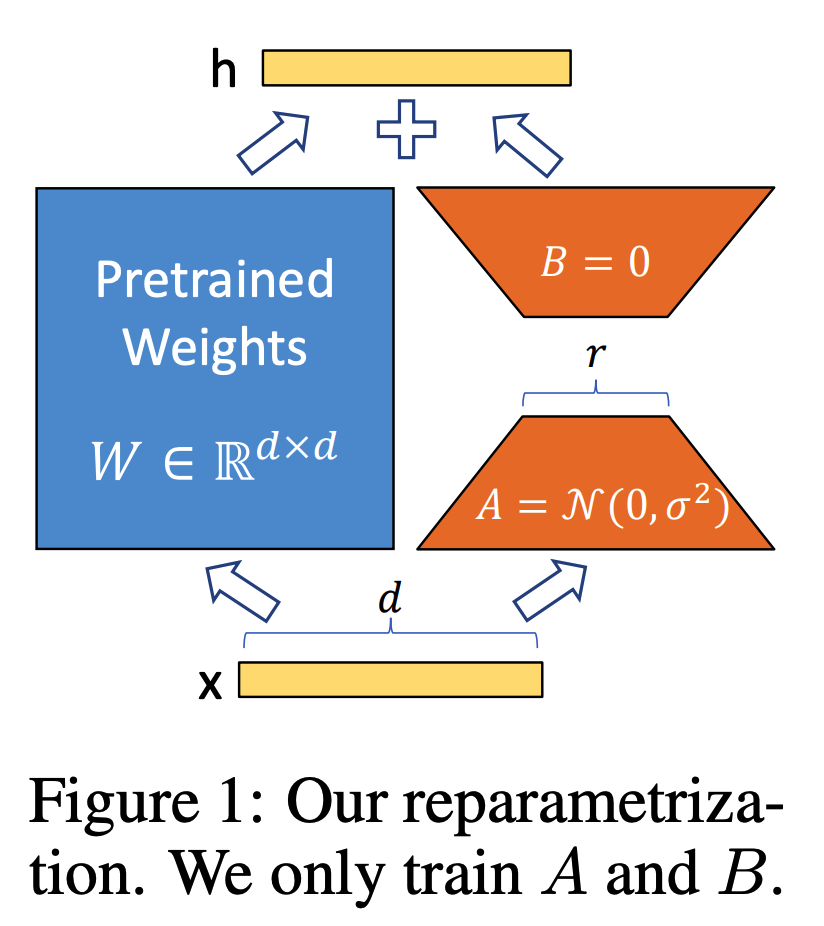
Fig. 563 Low Rank Adaptation#
위의 그림과 같이 원본 모델 weight는 freeze, LoRA는 rank를 r로 낮추어 finetuning한다. 이때 LoRA의 A는 random Gauissian으로, B는 zero로 weight initializing 한다.
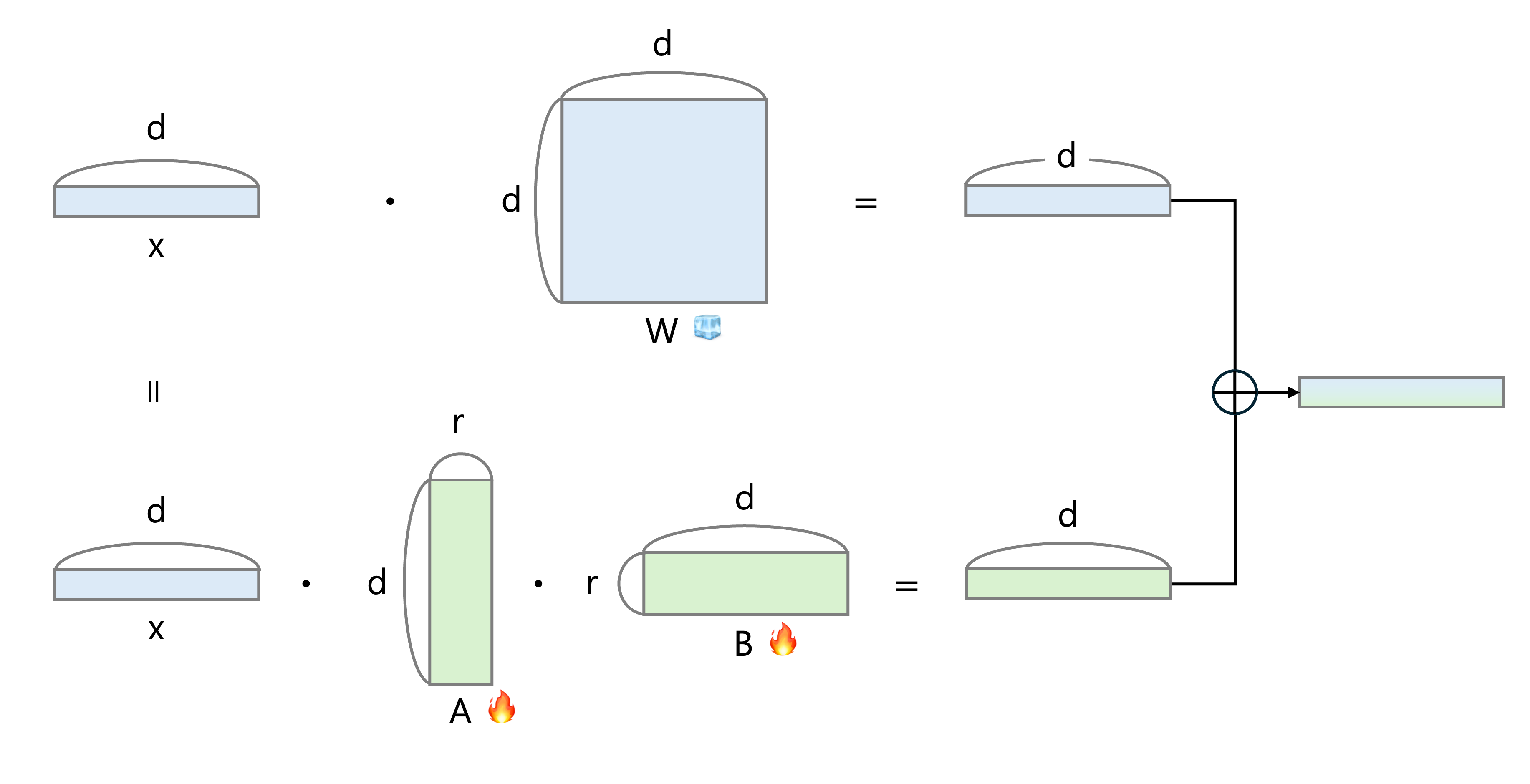
Fig. 564 Low Rank Adaptation matrix#
위 그림처럼 기존에는 d x d의 매우 큰 weight를 finetuning 해야 했지만, LoRA는 r만큼 압축된 weight matrix만 finetuning 하면 되기 때문에 훨씬 효율적이고 때에 따라 Fully fine-tuning 하는 방법들보다 더 좋은 성능을 보여주기도 한다. (그림은 이곳을 참고하였습니다.)
원본 논문의 LoRA는 LLM을 target으로 만들어졌기 때문에 Transformer의 query, key, value에 대한 parameter로 사용하였지만 Diffusion이나 다른 모델의 finetuning시에도 간단하게 사용 가능하다.
Task Arithmetic in Pretrained Models#
task Arithmetic은 특정 task에서 학습된 Model의 가중치를 task vector라 보고 각 task vector를 조합하여 새로운 task vector를 생성하는 방법론이다.
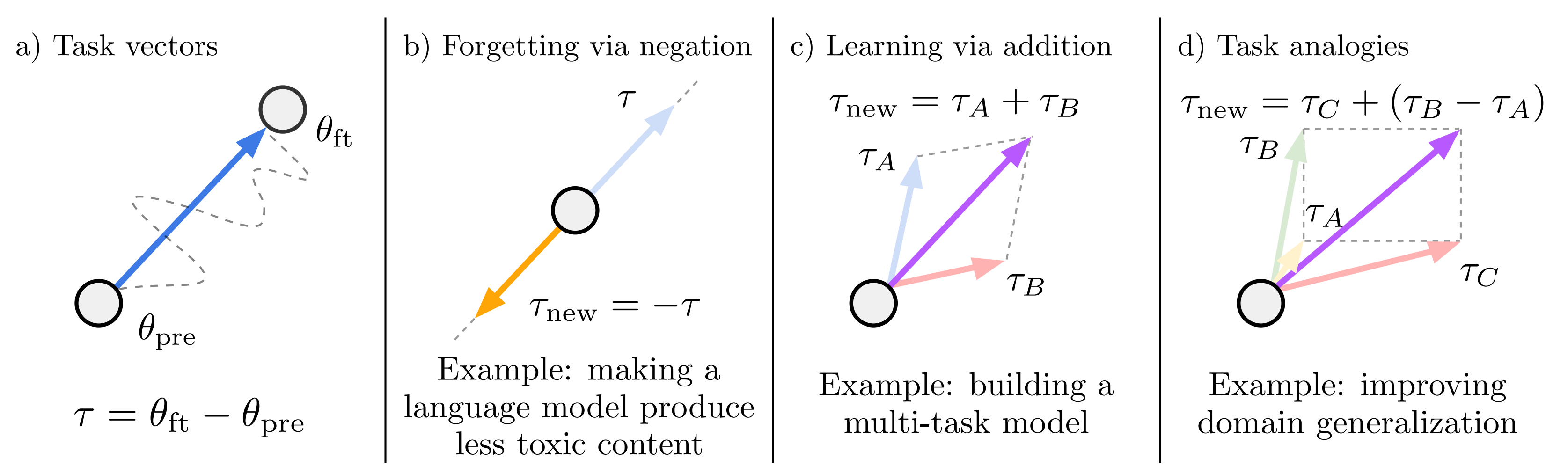
Fig. 565 Task Arithmetic#
pre-trained parameter를 \(\theta_{pre}\), fine-tuning parameter를 \(\theta_{ft}\)라고 할때 task vector \(\tau\)는 \(\theta_{ft}-\theta_{pre}\)로 정의할 수 있다. 이를 다양하게 조합하고 특히 d)처럼 task 간 analogy를 고려하여 연산하는 경우 새로운 task에 대한 성능을 높일 수 있다.
3. LCM-LoRA#
3.1 LoRA Distillation for LCM#
LCMs의 Latent Consistency Distillation에 대한 pseudo code는 다음과 같다:

Fig. 566 Latent Consistency Distillation#
논문의 저자는 LCMs의 Distillation은 LDMs에 관한 일종의 fine-tuning으로 보고 LoRA를 적용하는 방법을 제안하였다. pre-trained 된 weight matrix \(W_0\)에 대하여 기울기 업데이트는 \(W_0+\Delta W=W_0+BA, W_0\in \mathbb{R}^{d\times k}, B\in \mathbb{R}^{d\times r}, A\in \mathbb{R}^{r\times k}\) 로 표현할 수 있으며 rank \(r \leq \min{(d,k)}\) 로 작은 값을 갖는다. \(W_0\)의 weight는 고정되며 input \(x\) 에 대한 forward pass는 다음과 같다:
위와같이 LCMs에 LoRA를 적용할 경우 학습 parameter를 크게 줄일 수 있어 효율적이다.

Fig. 567 compare trainable parameter#
따라서 LCM-loRA는 기존 LCMs 보다 더 큰 모델의 훈련과 실사용이 가능하다. LCMs의 경우 SD-V1.5나 SD-V2.1의 base Stable Diffusion을 사용했지만, LCM-LoRA는 SDXL과 SSD-1B(Segmind)을 확장하여 사용하였다. large Model에서도 LCD을 적용했을 때 잘 적응하는 모습을 볼 수 있었다.

Fig. 568 1024 x 1024 resolution image results with CFG scale w=7.5#
3.2 LCM-LoRA as Universal Acceleration Module#
LCM-LoRA는 sampling step을 줄이는 distillation에 LoRA를 적용하였다. LoRA는 이외에도 custionized datasets에 대해 fine-tuning할 때 주로 쓰이는데 이같은 style에 대한 LoRA와 LCM-LoRA가 추가 학습없이 바로 합쳐져 사용할 수 있음을 발견했다. 저자는 이 발견이 task arithmetic에 대한 관점으로 해석할 수 있다고 주장하였다.
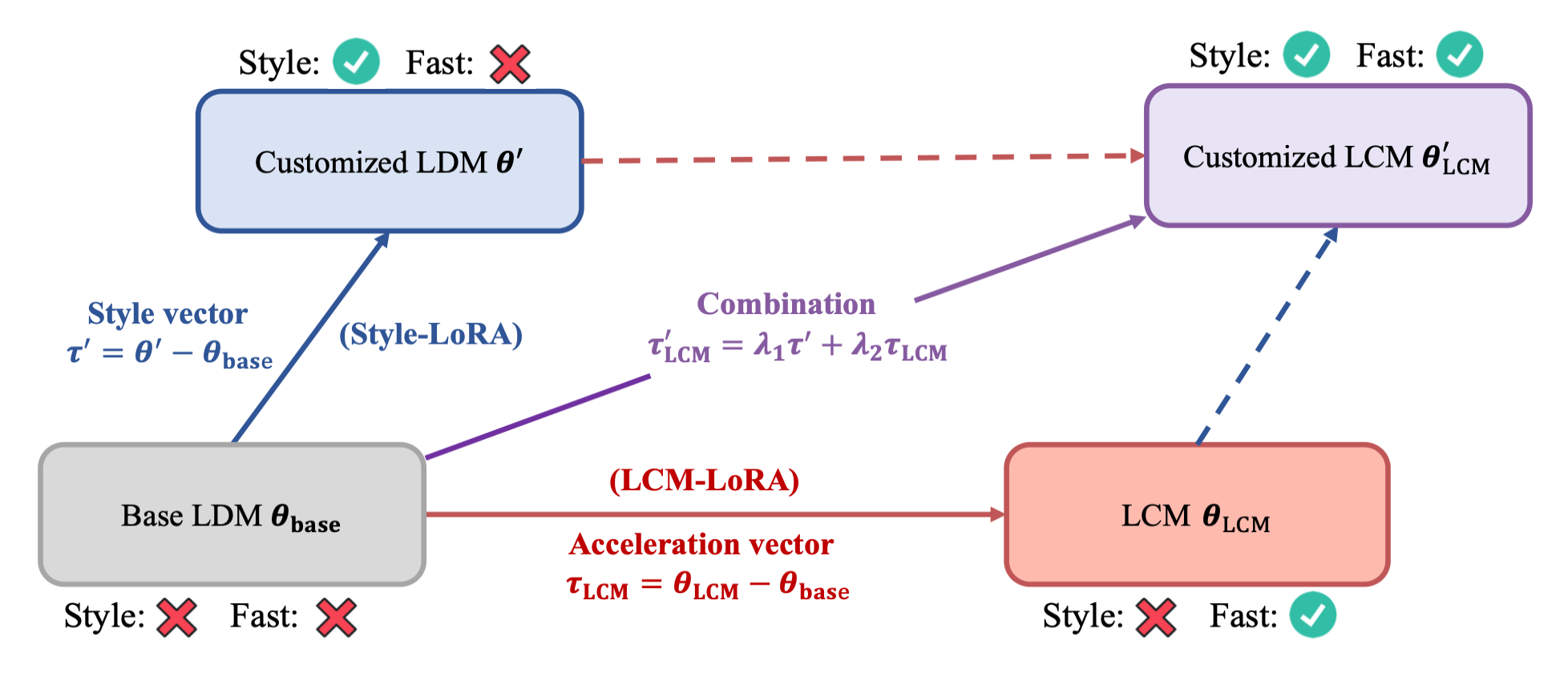
Fig. 569 Style LoRA with LCM-LoRA#
LCM-LoRA의 fine-tuned parameter를 \(\tau_{LCM}\)이라 할 때, \(\tau_{LCM}\)은 acceleration vector라 할수 있다. 그리고 custom dataset에서 학습한 LoRA의 fine-tuned parameter를 \(\tau'\)이라 할 때, \(\tau'\)은 style vector라 할 수 있다. LCMs를 통해 custom dataset에 대한 image를 생성할 때, 파라미터는 다음과 같이 조합된다:
파라미터는 단순한 선형 결합을 통해 이루어지며 \(\lambda_1\)과 \(\lambda_2\)는 하이퍼파라미터다. 추가적인 학습없이 다음과 같은 결과를 얻을 수 있었다:
Fig. 570 fine-tuning with LCM-LoRA#
4. Conclusion#
training-free acceleration module인 LCM-LoRA를 제안.
PF-ODE를 예측하며 Stable Diffusion 및 SD LoRA에 fast inference, minimal step을 제공함.
강력한 일반화 성능 증명.