Information
Title: High-Resolution Image Synthesis with Latent Diffusion Models (CVPR 2022)
Reference
Code: CompVis/latent-diffusion
Author: Namkyeong Cho
Last updated on May. 31, 2023
Introduction#
latent diffusion model이 어떻게 학습하는지 rate-distortion trade-off로 분석할 수 있다.
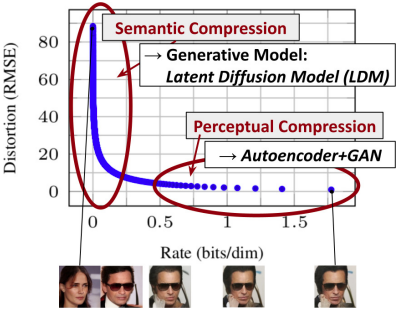
Fig. 148 Analysis of Latent Diffusion Model with rate-distortion trade-off#
학습 단계는 크게 2단계로 나눌 수 있다.
Perceptual Compression
Autoencoder를 학습하는 단계
perceptual : 인간의 인지와 관련된 것. 예를 들면 고양이 하면 고양이 귀, 꼬리 등 우리가 인지한 객체.
압축 과정에서 일정 부분을 넘어가면 비트를 많이 써도 사람이 인지할 수 없는 것에 대해 사용됨. (Rate가 0.5 이후 넘어가는 것을 보면 다른 것이 인지 안됨)
비트를 많이 씀 : 1비트(흑,백)로 표현하는 것을 8비트 등으로 표현 ⇒ 다양한 색상을 사용하여 색, 텍스쳐 등을 다양하게 표현할 수 있음. 이는 파라미터 수의 증가 등 모델 사이즈의 증가로 볼 수 있음.
Autoencoder를 통해 이미지 차원을 압축하여 사용할 비트를 줄임으로써 불필요한(사람이 인지할 수 없는) 것을 학습하지 않도록 함.
Semantic Compression
Diffusion model을 학습하는 단계로 이미지의 의미와 문맥을 이해하고 이를 바탕으로 압축하는 것을 말함. 예를 들어, 이미지 속의 개가 어디에 위치하는지, 배경이 무엇인지, 어떤 상황인지 등을 학습함.
Latent Diffusion Model#
오늘 알아볼 모델은 Latent Diffusion Model이다. 기존에 다뤘던 Diffusion Model과 유사하게 동작하는 생성 모델이다. 이 논문에서는 컴퓨터 자원의 소모를 줄이면서 Diffusion Model과 유사한 성능을 얻는것이 그 목표이다.
Latent Diffusion Model은 전반적으로 아래와 같은 구조를 가진다.
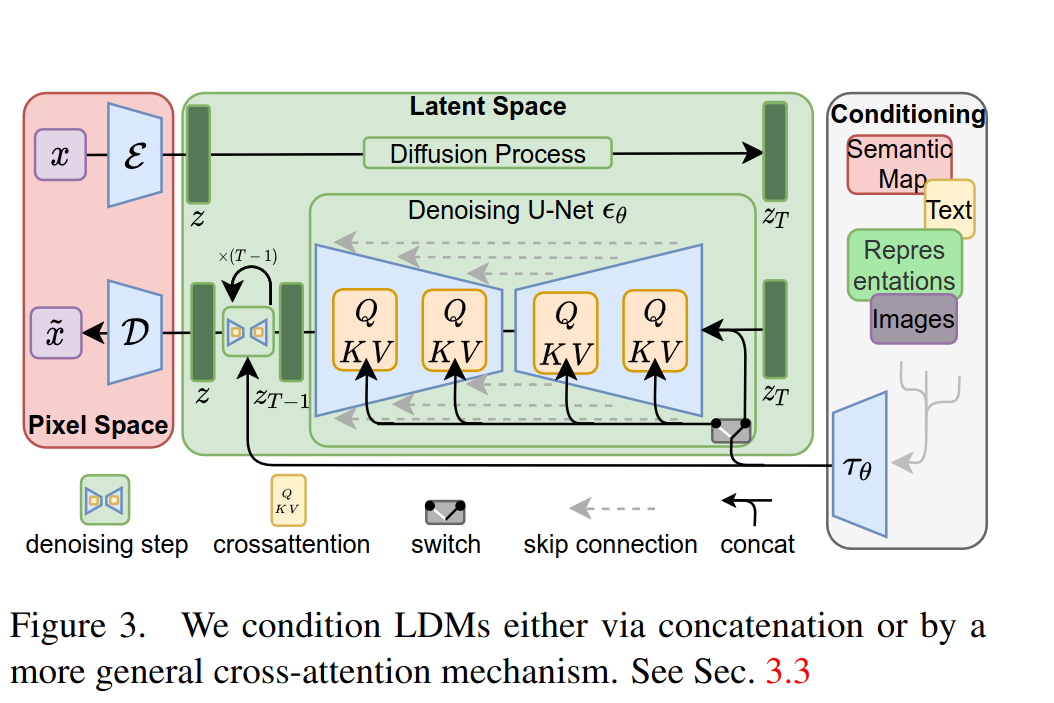
Fig. 149 Structure of Latent Diffusion Model#
\(x \in \mathbb{R}^{H\times W \times 3}\)이 input으로 주어졌을때 이를 encoder \(\mathcal{E}\)를 통해서 \(z=\mathcal{E}(x) \in \mathbb{R}^{h\times w\times c }\)로 인코딩 하고 \(\hat{x}=\mathcal{D}(z)\) 로 디코딩을 한다. 이 논문에서 \(f=H/h=W/w=2^m\), \(m\in \mathbb{N}\)이 되도록 여러 \(m\)에 대해서 테스트를 진행하였다. 또한 Latent space에서 분산이 커지지 않도록 KL divergence와 vector quantization(VQ)을 활용하였다. 이미지외 텍스트나, sematic map과 같이 추가적인 정보는 \(\tau_\theta\)를 통해서 전달을 하였고,
로 정의되고 \(\phi_i(z_i)\)는 \(U\)-Net 중간의 representation, \(W^{i}_V, W^{i}_K, W^{i}_Q\)는 학습 가능한 projection matrix이다. \(Q, K, V\) 는 attention의 query, key, value에 해당하며
로 연산이 진행된다. 학습을 위한 loss 함수는 다음과 같이 표현된다.
여기서 주목할만한 부분은 기존 Diffusion Model에서
와 같은 loss function으로 학습을 진행시키는데 \(x_t\)를 \(z_t\)로 바꾸면서 연산의 양을 줄였다는 점이다.
위의 “Introduction”과 연관지으면 다음과 같이 생각 해볼 수 있다.
encoder \(\varepsilon\), decoder \(D\) 로 구성된 perceptual compression model(학습된)를 바탕으로 효율적인, 낮은 차원의 latent space(high-frequency, imperceptible detail이 제거된)를 가지게 됨
고차원 공간과 비교했을 때 이 latent space는 likelihood-based generative model에 더 적합함
데이터에 중요한 semantic bit에 집중할 수 있고 더 낮은 차원에서 효율적으로 학습 가능
Experiments#
4.1. On Perceptual Compression Tradeoffs#
different downsampling factor \(f \in \{1,2,4,8,16,32\}\) 에 대한 분석
latent space 차원 개수에 따른 차이 분석
LDM-1 : pixel-based DMs
computational resource : single NVIDIA A100 1대로 함
전체 같은 parameter 개수와 step을 기준으로 함
위의 표는 autoencoder 차원에 따른 hyperparameter, loss에 따른 실험 결과를 보임
위의 그래프는 모델이 수렴하는데 소요되는 step을 분석함
\(f\) 값이 너무 크면 약간의 학습 후 fidelty(학습 데이터와 실제 데이터의 유사도)가 정체된 것을 볼 수 있음
이는 아래 사진의 결과와 perceptual과 bit ratio 부분을 생각해보면 대부분의 perceptual compression은 diffusion에 있으며 encoder와 decoder 부분에서 압축이 지나치게 되어 정보 손실이 발생하여 달성할 수 있는 품질이 제한됨
위의 그래프는 CelebA-HQ와 ImageNet에서 학습된 모델을 DDIM sampler를 사용하여 다양한 step의 denoising에 대한 샘플링 속도 측면에서 FID 점수와 비교함
ImageNet이 CelebA-HQ 대비 더 복잡한 dataset임
point가 총 5개인데 오른쪽부터 왼쪽으로 step 수가 {10,20,50,100,200}을 의미함
LDM-{4-8}이 outperform을 발휘함
LDM-1은 낮은 FID를 가지고 sampling 속도도 느림
4.2. Image Generation with Latent Diffusion#
256x256 image의 unconditional model을 CelebA-HQ, FFHQ, LSUN-Churches, Bedrooms로 학습하고 sample quality, data manifold의 coverage(FID, Precision-and-Recall) 평가
CelebA-HQ
제안한 모델이 최고 성능
LSGM : encoder, decoder를 UNet과 동시에 학습시킨 결과
LSUN-Bedrooms : ADM보다 절반의 parameter와 짧은 train 시간으로 유사한 score(?)를 얻음
제안한 방법인 LDM은 GAN-based methods을 지속적으로 개선해 adversarial 방식에 비해 mode-covering likelihood-based training의 이점을 Precision과 Recall을 통해 볼 수 있음. (아래 그림은 정성적 결과)
4.3. Conditional Latent Diffusion#
4.3.1 Transformer Encoders for LDMs#
text-to-image modeling : 1.45B parameter KL-regularized LDM
LAION-400M으로 language prompt 수행
BERT-tokenizer
\(\tau_{\theta}\) : transformer

Fig. 150 text to image on LAION#
아래 사진은 Layout이 주어졌을 때, 이를 기반으로 image를 생성하는 layout-to-image의 샘플 결과임

Fig. 151 layout-to-image#
class-conditional ImageNet model 결과
4.3.2 Convolutional Sampling Beyond 256x256#
spatially aligned conditioning information(semantic map 등)을 input에 연결했을 때 image-to-image translation model 목적 수행 가능
semantic synthesis, super-resolution, inpainting에 실험
semantic synthesis
dataset : semantic map을 가진 landscape image
semantic map의 downsampled version을 \(f=4\) 인 model의 input으로 사용(VQ-reg)
input resolution : 256x256(crop from 384x384)
아래 실험은 input 크기 대비 더 큰 image 생성 가능한 것을 보여줌
4.4. Super-Resolution with Latent Diffusion#
OpenImages로 사전학습된 \(f=4\) autoencoding model(VQ-reg) 사용
low-resolution data가 input으로 들어감
4.5. Inpainting with Latent Diffusion#
원본 이미지에서 원하는 물체를 제거한 뒤 이미지가 잘 복구된 것을 볼 수 있음