Information
Title: HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
Reference
Author: Hyoungseo Cho
Last updated on Oct. 10, 2023
HyperDreamBooth#
Introduction#
Personalization 는 Generative AI 분야에서 떠오르고 있는 주제입니다. 이는 high-fidelity와 identity를 유지한 상태로 다양한 맥락과 스타일을 생성할 수 있도록 합니다. 본 논문은 Dreambooth 를 기반으로 진행되었기 때문에 Dreambooth 논문을 먼저 읽어 보시기를 추천드립니다.
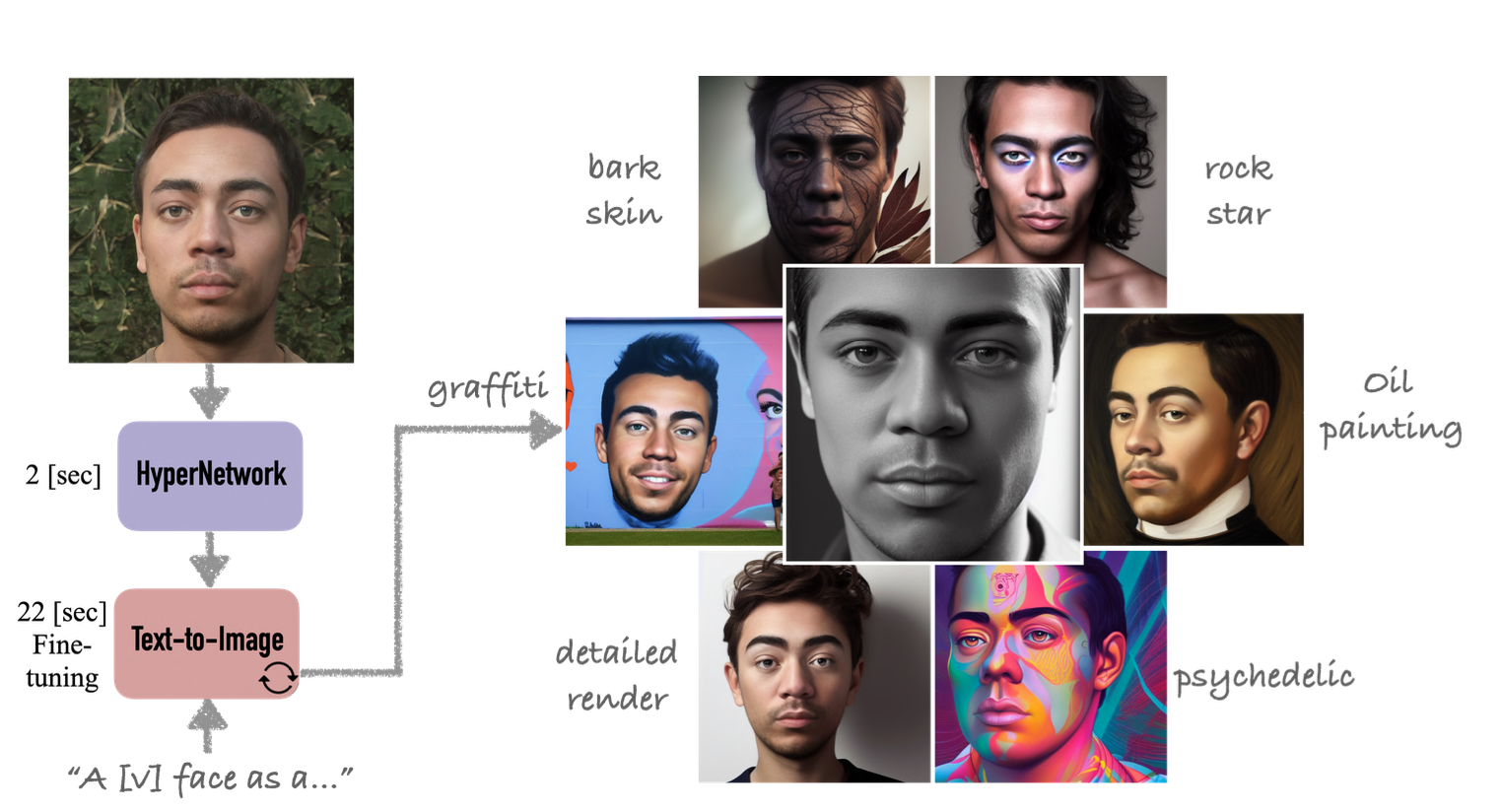
Fig. 294 HyperDreamBooth#
Contribution#
본 논문의 Contribution은 크게 3가지로 볼 수 있습니다. Lighweight DreamBooth (LiDB), New HyperNetwork architecture 그리고 rank-relaxed finetuning 입니다. 위 3가지 방법을 활용하여 기존 DreamBooth의 핵심 능력을 유지하면서 크기를 줄이고 속도를 높일 수 있었습니다.
Related Work#
Text-to-image Models
본 논문에서는 Stable Diffusion 모델을 활용하여 HyperDreamBooth를 구현했지만, 이 부분은 다른 텍스트-이미지 모델 (Imagen, DALL-E2 등) 도 적용이 가능합니다.
Personalization of Generative Models
Generative Adversarial Network 기반의 기술들은 fidelity가 떨어지거나 다양한 문맥을 제공하지 못하는 문제가 있습니다. 이에 따라 HyperNetwork를 도입한 연구를 진행했습니다.
T2I Personalization via Finetuning
다음으로, text-to-image personalization을 위한 Finetuning에 대한 연구가 있습니다. CustomDiffusion, SVDiff, LoRA, StyleDrop, DreamArtist 등의 예시가 있습니다. 하지만 이는 속도 측면에서 느리다는 단점을 가지고 있습니다.
이러한 관련 연구들을 볼 때, HyperDreamBooth는 속도와 효율성 측면에서 큰 발전을 이루었다고 볼 수 있습니다.
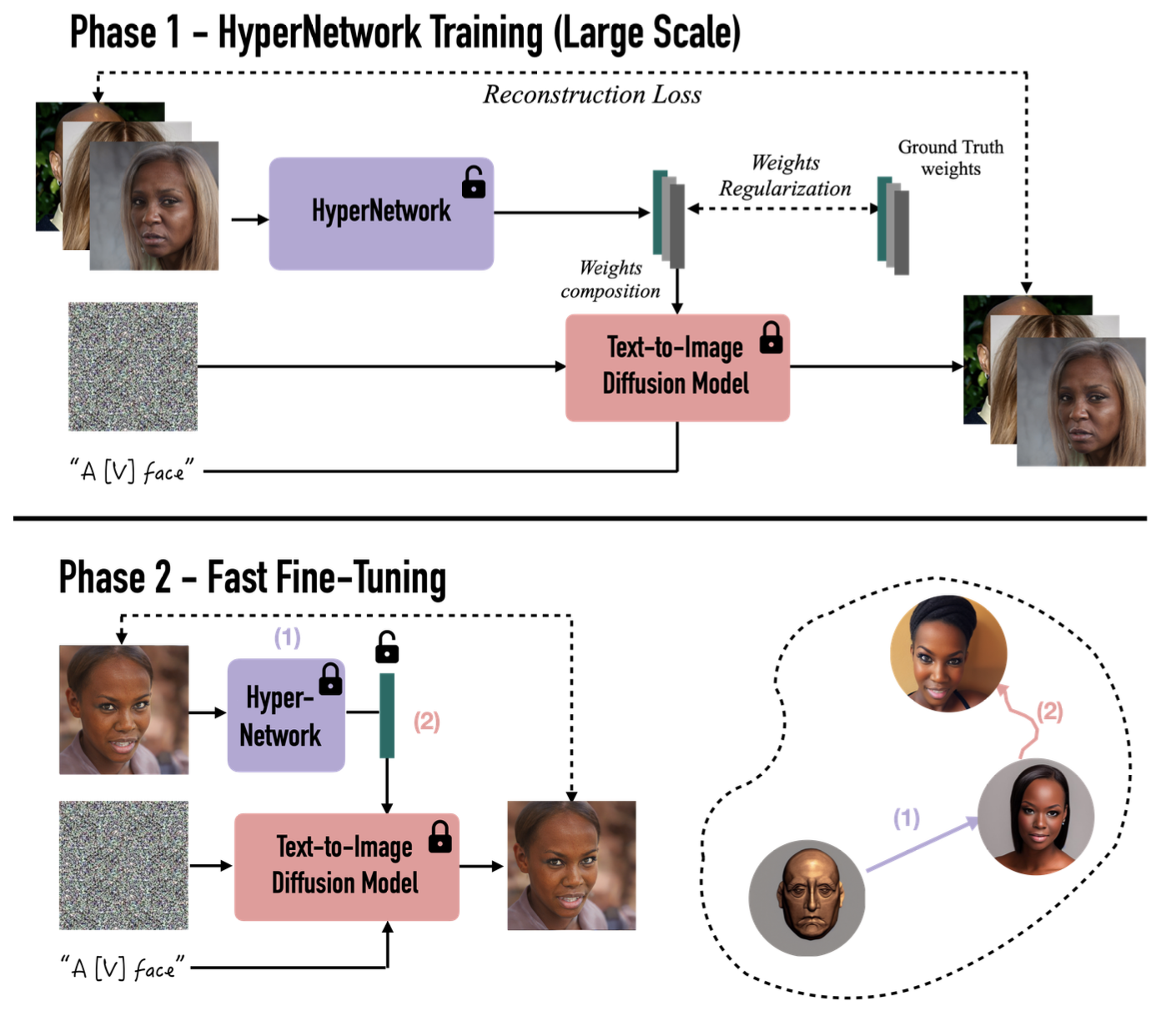
Fig. 295 HyperDreamBooth Training and Fast Fine-Tuning#
Prelimiaries#
Latent Diffusion Models (LDM)
본 논문에서는 Stable Diffusion 모델을 활용하여 HyperDreamBooth를 구현했지만, 이 부분은 다른 텍스트-이미지 모델 (Imagen, DALL-E2 등) 도 적용이 가능합니다.
DreamBooth
이전에 나온 DreamBooth는 특정 주제의 이미지를 생성하기 위해 T2I denoising 네트워크를 finetuning하는 전략을 활용했습니다. 이 방법은 HyperDreamBooth의 영감원 중 하나로 활용되었습니다.
Low Rank Adaptation (LoRA)
LoRA는 모델의 가중치를 낮은 랭크의 행렬로 근사화하여 모델의 크기와 복잡성을 줄이는 방법입니다. 본 논문에서는 이 LoRA 기술을 활용하여 더 빠르고 효율적인 personalization이 가능하도록 합니다.
Method#
위에서 살펴 본 Contribution의 내용을 자세히 살펴보도록 하겠습니다.
Lightweight DreamBooth (LiDB)#
HyperdreamBooth 의 핵심 기술 중 하나인 Lightweight DreamBooth, 줄여서 LiDB에 대해 설명드리겠습니다. LiDB는 rank-1 LoRA residuals의 가중치 공간을 더 세분화하는 것이 핵심 아이디어입니다. 분해 과정에서 rank-1 LoRA weight-space 내에서 random orthogonal basis를 활용하여 decompose 합니다.
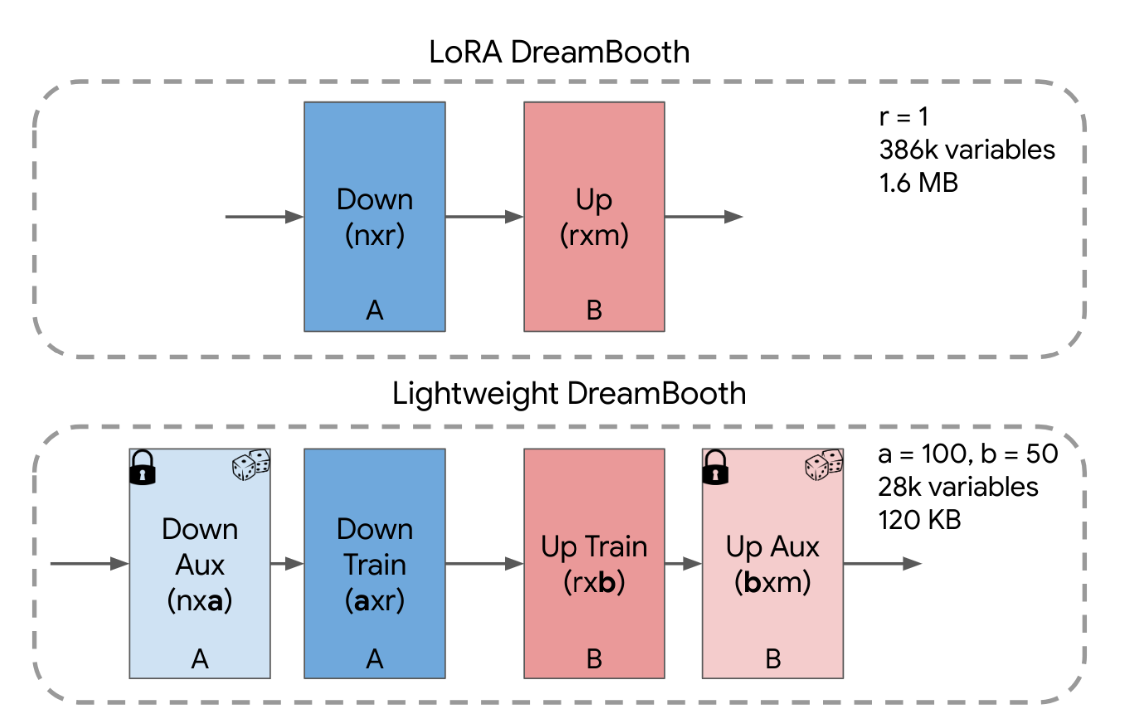
Fig. 296 Lightweight DreamBooth#
이 접근 방식은 LoRA의 A와 B 행렬을 각각 두 개의 행렬로 분해하는 것으로도 이해할 수 있습니다. 더 구체적으로 살펴보면, A 행렬은 \(A_{aux}\) 와 \(A_{train}\) 으로 분해되며, B 행렬은 \(B_{aux}\) 와 \(B_{train}\) 으로 분해할 수 있습니다. 여기서 \(aux\) 레이어는 행별로 직교하는 벡터로 무작위 초기화되고 freeze 되어 있으며, \(train\) 레이어는 학습되는 가중치입니다. 따라서 LiDB 선형 레이어의 weight-residual은 다음과 같이 표현할 수 있습니다.
여기서 \(aux\) 레이어는 experimentally fix 되었으며 이 과정을 통해 trainable parameter 개수는 약 30K개, 사이즈는 약 120KB로 경량화 할 수 있습니다. 이렇게 작은 크기와 변수만으로 fidelity, editability, style 그리고 diversity 등을 유지할 수 있다는 것이 포인트입니다.
HyperNetwork#
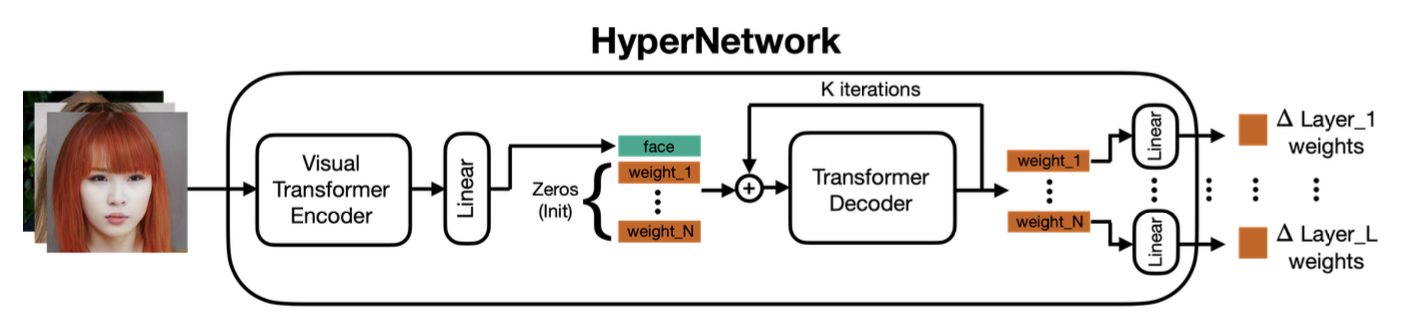
Fig. 297 HyperNetwork Architecture#
다음은 Hypernetwork 입니다. 본 논문에서는 사전에 훈련된 T2I 모델을 빠르게 personalization 하기 위해 HyperNetwork를 제안합니다. 여기서 \(\tilde{\theta}\) 는 모든 LiDB residual 행렬을 나타내며, 각 T2I 모델의 cross-attention 및 self-attention 레이어에 대한 \(A_{train}\) 및 \(B_{train}\) 입니다. 이 핵심 아이디어는 주어진 이미지 x를 입력으로 받고, 이 이미지를 사용하여 LiDB의 low-rank residual인 \(\hat{\theta}\) 을 예측하는 HyperNetwork \(H_{\eta}\) 를 돌입하는 것입니다.HyperNetwork는 도메인 특화 이미지 데이터셋에서 훈련되며, 일반적인 확산 노이즈 제거 손실과 가중치 공간 손실을 가지고 있습니다.
여기서 \(x\) 는 reference image를 의미합니다. HyperDreamBooth의 목표는 주어진 참조 이미지 x를 기반으로 해당 이미지와 유사한 새로운 이미지를 생성하는 것입니다. \(\theta\) 는 \(x\) 에 대한 pre-optimized 된 가중치 paramters입니다. 이러한 가중치는 HyperDreamBooth 모델을 personalization 하기 위해 이미지 \(x\) 와 관련된 텍스트와 함께 조정됩니다. \(D_{\theta}\) 는 diffusion model을 나타냅니다. 이 모델은 이미지 \(x + \epsilon\) 및 Supervisory Text Prompt \(c\) 로 조건이 설정된 상태에서 사용됩니다. 이 모델은 이미지 생성 및 개인화에 사용됩니다. \(\alpha\) 와 \(\beta\) 는 상대적인 loss의 가중치를 제어하기 위한 hyperparameters 입니다. 이러한 hyperparameters 는 각 loss 항목의 중요성을 조절하는 데 사용됩니다.
Supervisory Text Prompt
Supervisory Text Prompt는 이미지 생성을 지원하기 위한 텍스트 입력입니다. 주어진 텍스트 프롬프트는 이미지 생성에 대한 지시사항 또는 조건을 제공합니다. HyperDreamBooth에서는 “a [V] face” 와 같은 텍스트 프롬프트를 사용하여 개인화된 이미지를 생성합니다. [V] 는 드물지만 다양한 의미 수정을 삽입할 수 있는 역할을 합니다.
HyperNetwork Architecture
HyperNetwork는 HyperDreamBooth에서 사용되는 모델로, 개인화된 이미지 생성을 위한 가중치를 예측하는 역할을 합니다. HyperNetwork는 보통 다른 신경망 구조로 구성되며, 주어진 이미지를 입력으로 받아서 T2I 모델의 가중치를 예측합니다. 이러한 개인화된 이미지 생성을 위한 핵심 구성 요소 중 하나입니다. 여기서 예측한 가중치를 이후 Stable Diffusion 모델의 가중치에 더하여 개인화를 실행합니다.
Iterative Prediction
HyperDreamBooth에서 사용되는 HyperNetwork는 반복적 예측을 수행합니다. 이것은 HyperNetwork가 초기 예측을 한 후에도 추가 반복적인 예측 단계를 통해 결과를 개선하려고 시도하는 것을 의미합니다. 초기 HyperNetwork 예측은 방향성이 올바르고 대상과 얼굴과 유사한 semantic 특성을 생성하지만 미세만 세부 정보를 충분히 잡아내지 못할 수 있습니다. 따라서 반복적인 예측을 통해 초기 예측을 fine-tuning하고 더 나은 이미지를 생성합니다. 이 때에 image encoding은 단 한 번만 수행되며, 추출된 특징 f는 반복적인 예측 과정에서 사용됩니다.
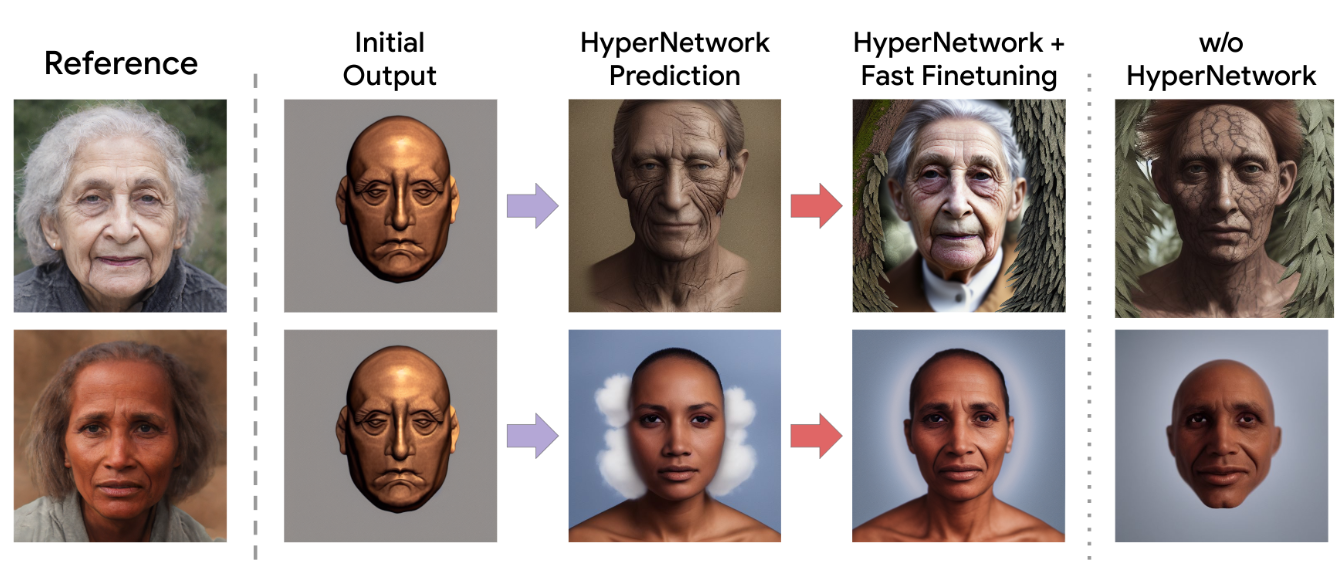
Fig. 298 HyperNetwork + Fast Finetuning#
Rank-Relaxed Fast Finetuning#
초기 HyperNetwork를 실행하고 나면 semantic 속성과 방향성에 대해서 올바르게 생성이 되지만 세부적인 detail은 잘 잡아내지 못합니다. 이를 위해 마지막으로 fast finetuning 단계를 제안합니다. 이 단계를 통해, DreamBooth보다 훨씬 빠르지만 강한 subject fidelity, editability 그리고 style diversity를 동일하게 유지할 수 있습니다. 먼저 HyperNetwork를 사용하여 개인화된 diffusion model 가중치를 예측합니다. 이후 diffusion model의 가중치를 초기화된 이미지 x와 함께 주어진 텍스트 지시어 c에 대한 diffusion noise loss \(L(x)\) 를 최소화하도록 조정합니다. 여기서 주요한 점은 rank-relaxed 의 개념입니다. 이것은 초기 모델의 rank(주로 1)를 완화하여 더 높은 rank로 LoRA 모델을 fine tuning 하는 것을 의미합니다. 구체적으로, HyperNetwork의 예측된 가중치 모델의 전체 가중치에 추가하고 더 높은 rank로 LoRA fine tuning을 수행합니다. 이를 통해 모델은 주체의 고주파수 세부 사항을 더 잘 근사화할 수 있으며 이로 인해 다른 낮은 rank로 제한된 업데이트보다 더 높은 주제 충실도를 달성할 수 있습니다. 이러한 rank-relaxed의 개념은 HyperDreamBooth를 다른 방식보다 더 우수하게 만드는 요인입니다. 여기서도 동일한 Supervisory Text Prompt “a [V] face” 를 사용하는데 이 프롬프트는 이미지 개인화를 지원하며 모델이 얼굴에 관련된 다양한 특성과 스타일을 캡처하는 데 도움이 됩니다. 그리고 HyperNetwork의 초기화된 가중치를 고려할 때, fast finetuning 단계를 40번의 반복으로 완료할 수 있습니다. 이는 DreamBooth 및 LoRA DreamBooth와 비교했을 때 25배 빠른 속도라는 것을 의미합니다.
Experiments#
본 HyperDreamBooth는 Stable Diffusion v1.5 을 활용하여 구현했습니다. 이 모델에서는 Stable Diffusion v1.5의 다양한 요소 중 하나인 diffusion UNet의 cross and self-attention 레이어에 대한 LoRA 가중치를 예측합니다. 또한 텍스트 정보를 활용하기 위해 CLIP 텍스트 인코더도 예측합니다. 이미지 생성 모델을 개인화하기 위해 시각화에 사용되는 모든 얼굴 이미지는 SFHQ(Synthetic Face Headquarters) 데이터셋을 활용했습니다. 모델을 훈련시키기 위해 CelebA-HQ 데이터셋에서 15,000개의 실제 얼굴 이미지가 활용되었습니다.

Fig. 299 Result Gallery#
왼쪽 위에서 오른쪽 아래로 “인스타그램 셀카 [V] 얼굴”, “Pixar 캐릭터 [V] 얼굴”, “bark skin의 [V] 얼굴”, “록 스타 [V] 얼굴”, 가장 오른쪽: “ 전문적인 [V] 얼굴 촬영” 프롬프트를 활용했습니다.

Fig. 300 Qualitative Comparison#
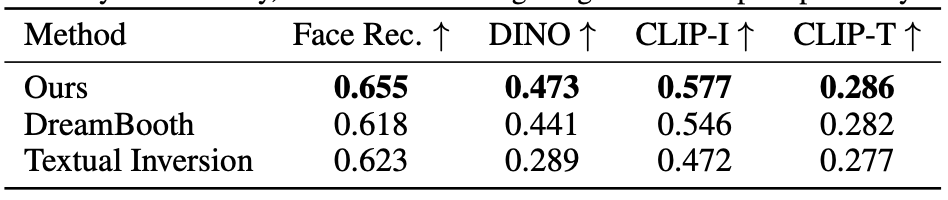
Fig. 301 Comparisons Table#
Comparisons#
Hyperdreambooth, DreamBooth 그리고 Textual Inversion의 무작위 생성된 샘플을 비교한 이미지와 표입니다. 정량적 평가를 위해 DINO와 같은 지표를 활용했습니다.
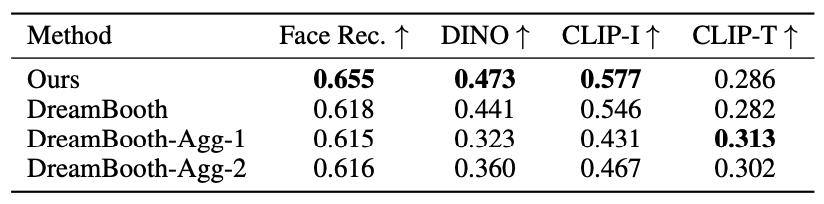
Fig. 302 Comparisons with DreamBooth#
위 표는 DreamBooth와 비교하는 부분입니다. DreamBooth의 hyperparameter를 다르게 조정하여 비교했습니다. 그 결과 학습률을 증가시키고 반복 횟수(iterations)를 감소시키면 결과의 저하가 있었습니다. DreamBooth-Agg-1은 400번의 반복을 시행하고, DreamBooth-Agg-2는 일반적인 Dreambooth의 1200번 대신 40번의 반복을 사용했습니다.
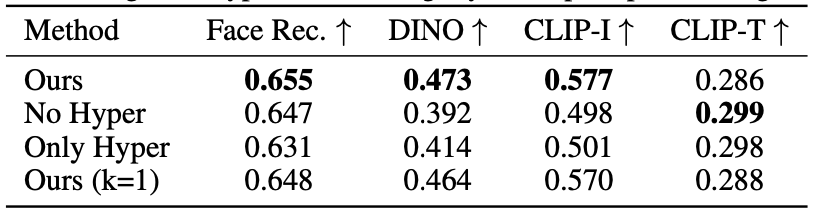
Fig. 303 HyperNetwork Ablation#
위 부분은 여러 가지 구성 요소로 나누어 실험한 표입니다. 실험 중에는 하이퍼네트워크를 사용하지 않는 경우, 하이퍼네트워크 예측만 사용하고 fast-finetuning을 사용하지 않은 경우, 반복 예측 없이 전체 방법을 1번만 사용한 경우를 비교합니다. 결과적으로 전체 방법이 모든 신뢰성 지표에서 가장 우수한 결과를 달성한다는 것을 보여주고 있습니다.
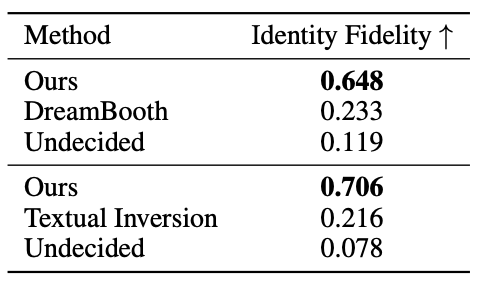
Fig. 304 User Study#
얼굴 인식 메트릭 이 특정 시나리오에서 상대적으로 약하다고 합니다. 얼굴 인식 네트워크가 실제 이미지에만 훈련되어 있고 다양한 스타일에서 동일한 사람을 인식하도록 훈련되어 있지 않기 때문이라고 주장하며 이를 보완하기 위해 user study를 진행했습니다. 여기서도 HyperDreamBooth, DreamBooth, Textual Inversion을 비교하고 사용자들의 평가를 받았습니다.
Follow-ups#
하지만 여전히 follow-ups가 존재합니다. 먼저 semantic directional error 라고 하는 초기 예측에서 잘못된 시맨틱 정보가 나올 수 있는 에러입니다. 잘못된 눈 색깔이나 헤어 타입, 성별 등이 나올 수 있습니다. 다음으로 incorrect subject detail capture 라는 오류가 있습니다. 다음은 underfitting 입니다. Fast finetuning 단계에서 identity는 지켜지더라도 유사하지 않은 샘플이 생성될 수 있습니다. 다음으로 HyperNetwork와 fast-finetuning 모두 일부 스타일에 대해 낮은 editability 가 나올 수 있습니다. 이러한 문제점은 빛, 포즈 등으로 인해 OOD인 샘플에서 나타날 수 있습니다.
Conclusion#
본 연구에서는 HyperDreamBooth라는 새로운 방법을 소개했습니다. 이 방법은 텍스트에서 이미지로 변환하는 diffusion model을 빠르고 가벼운 방식으로 개인화하는 것을 목표로 합니다. HyperDreamBooth는 HyperNetwork라는 구성 요소를 활용하여 diffusion model의 가벼운 파라미터인 LiDB(Lightweight DreamBooth)파라미터를 생성하며, 이어서 DreamBooth 및 기타 최적화 기반 개인화 작업에 비해 크기와 속도를 상당히 줄이면서 fast rank-relaxed fine tuning을 수행합니다. 이를 통해 모델의 무결성을 유지하면서 다양한 스타일과 의미적 수정이 적용된 다양한 고품질 이미지를 생성할 수 있음을 입증하였습니다.