Information
Title: Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting (CVPR 2023)
Reference
Author: Sangwoo Jo
Last updated on Sep. 06, 2023
Imagen Editor#
이번 시간에는 Google Research 에서 소개하는 Imagen 모델 기반의 text-guided image inpainting 모델 Imagen Editor 와 text-guided impainting 의 평가기법 EditBench 에 대해 알아볼 예정입니다.
Text-guided image inpainting 에서 기존에는 mask 영역을 random 하게 지정하여 학습을 진행했습니다. 이는 입력된 text prompt 와 무관한 영역을 masking 하게 됨으로써 모델이 prompt 를 참조하지 않고 오로지 image content 만으로 학습하게 되는 현상이 발생합니다. Imagen Editor 는 이를 해결하기 위해 Object Masking 기법을 소개합니다. Prompt 에 해당하는 객체 전체를 masking 함으로써 모델이 text prompt 를 더 참조할 수 있도록 유도하는 것이 목표입니다. SSD MobileNet v2 모델을 Object Detector 로 사용함으로써 모델 성능이 크게 개선되는 부분을 확인할 수 있었다고 합니다.

Fig. 223 Effect of Object Masking#
Imagen Editor 에서 또 다른 특징은 Imagen 모델 기반의 cascaded diffusion model architecture 를 지니고 있다는 점입니다. 이때, SR3, Palette, GLIDE 와 유사하게 이미지와 mask 가 Encoder 를 거친 후, diffusion latent 와 concatenate 하면서 conditioning input 으로 들어가게 되며, 모두 1024x1024 해상도를 가진다고 합니다. 따라서, base diffusion 64x64 모델 그리고 64x64 → 256x256 super resolution 모델에 입력 시, downsampling 작업 후 모델 input 으로 입력합니다. 또한, conditioning 이미지와 mask 없을 시 Imagen 모델을 사용하는 것과 동일한 효과를 내기 위해, 새로 추가되는 input channel weights 는 0으로 초기화해서 학습을 진행했다고 소개합니다.
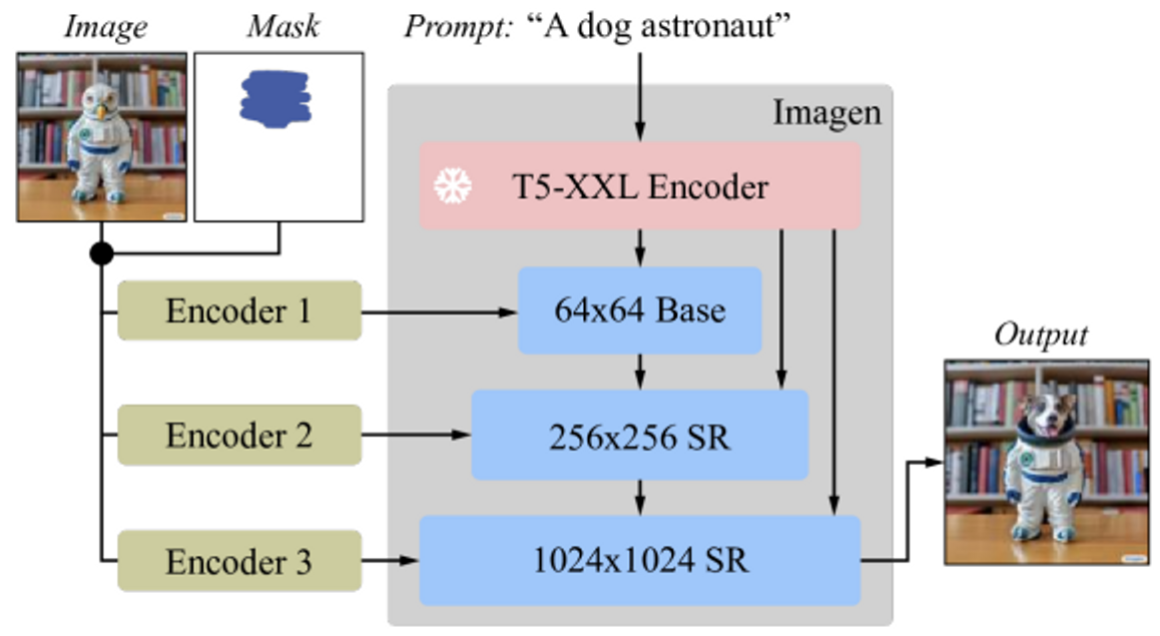
Fig. 224 Imagen Editor Architecture#
Imagen 에서 소개되었던 Classifier-Free Guidance 를 동일하게 사용하고, 이때 guidance weight 를 1부터 30 까지 범위 내에서 변화시키는 oscillating guidance 기법을 적용함으로써 생성된 이미지 퀄리티 및 text-image alignment 가 상승되는 효과를 볼 수 있었다고 합니다.
논문에서는 Imagen Editor 와 같은 text-guided image inpainting 모델들을 평가할 수 있는 새로운 benchmark EditBench 를 제시합니다. 240개의 (image, mask) 쌍으로 데이터셋이 구축되어있고, 각 쌍마다 3가지의 prompt 로 생성된 이미지로 사람이 모델 성능을 측정하게 됩니다. Automatic Evaluation Metric 으로는 CLIPScore, 그리고 CLIP-R-Prec 를 사용했습니다.
EditBench 이미지 데이터셋의 절반은 open source 로 공개된 computer vision 데이터셋으로부터 수집되었고, 나머지 절반은 text-to-image 모델로 생성해서 구축했습니다. 이때, attribute-object-scene 의 요소들을 모두 갖추도록 이미지들을 수집 및 생성했습니다.
Attributes (material, color, shape, size, count)
Objects (common, rare, text rendering)
Scenes (indoor, outdoor, realistic, paintings)
예를 들어서, ‘a=metal|o=cat|s=outdoor’ 요소들을 포함하는 문구를 ‘a metal cat standing in the middle of a farm field’ 처럼 생성하는 것입니다. 앞써 언급한 3가지 prompt 는 해당사진처럼 Mask-Simple, Mask-Rich, 그리고 Full 로 정의합니다.
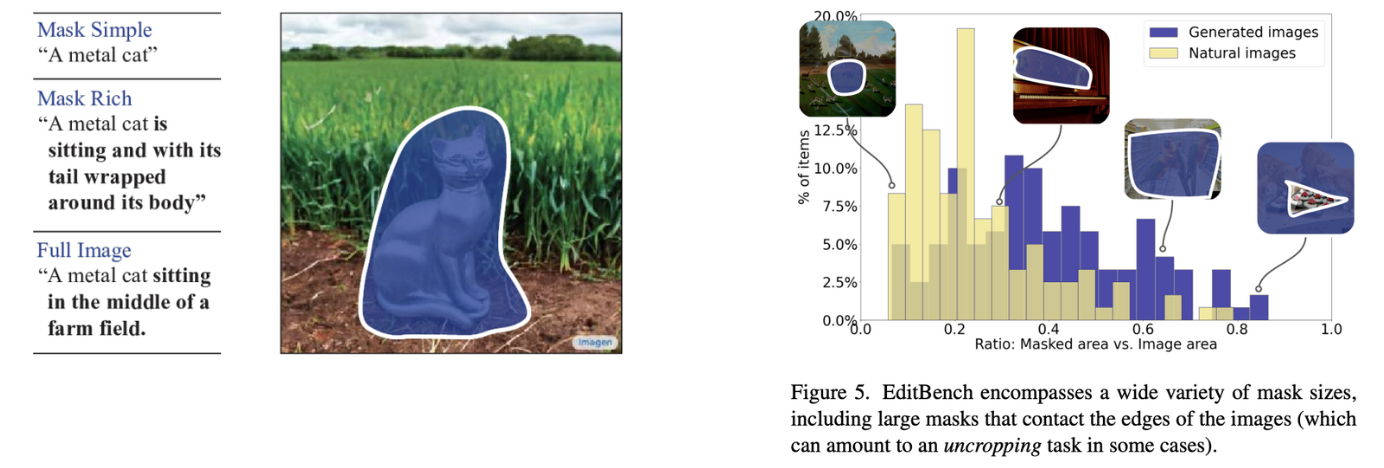
Fig. 225 EditBench example#
데이터셋 구축시, mask 크기도 다양하게 설정하여 mask 크기에 따른 모델 성능도 확인할 수 있었습니다. 성능을 측정해본 결과, Object masking 으로 학습한 모델이 random masking 으로 학습한 모델보다 small/medium masks 에서 성능적으로 월등히 좋다는 것을 확인할 수 있습니다.
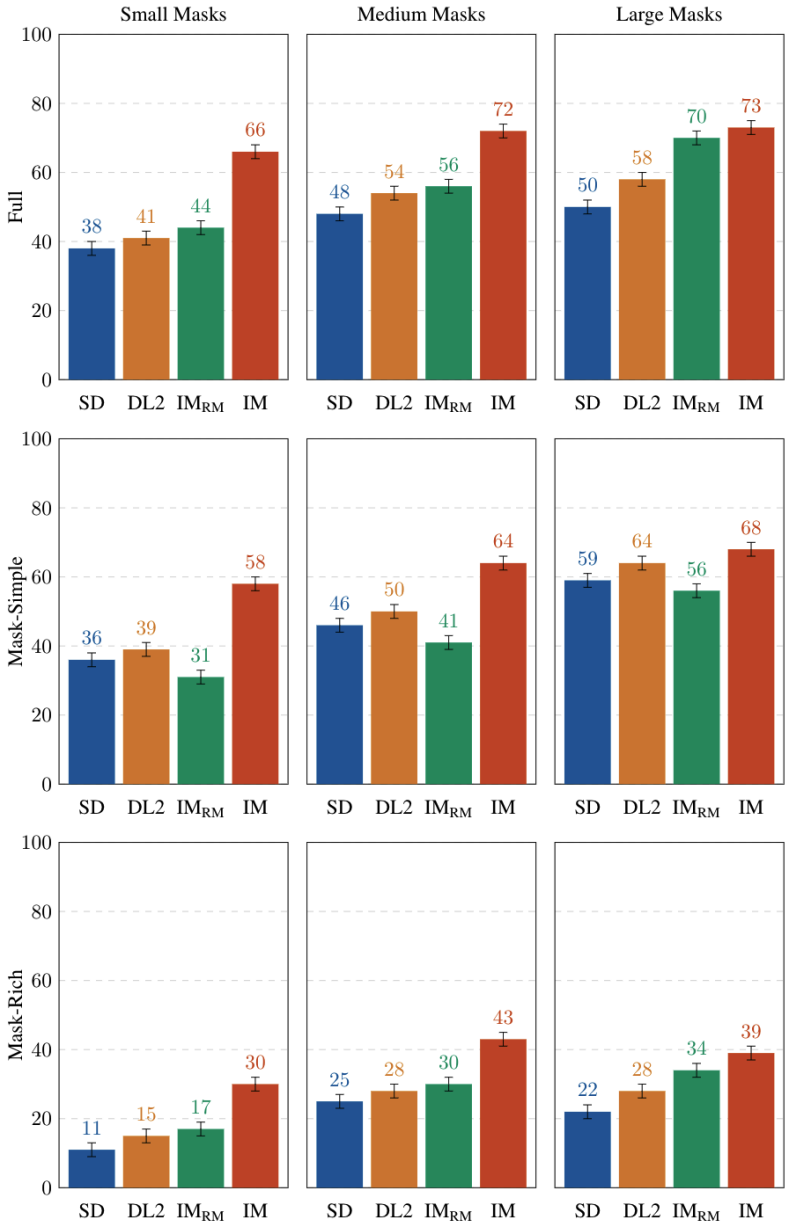
Fig. 226 Human Evaluations on EditBench#
또한, object-rendering 에 비해 text-rendering 성능이 저하되는 부분을 확인할 수 있고, material/color/size 속성보다 count/size 속성에 더 취약한 부분도 확인할 수 있었습니다.
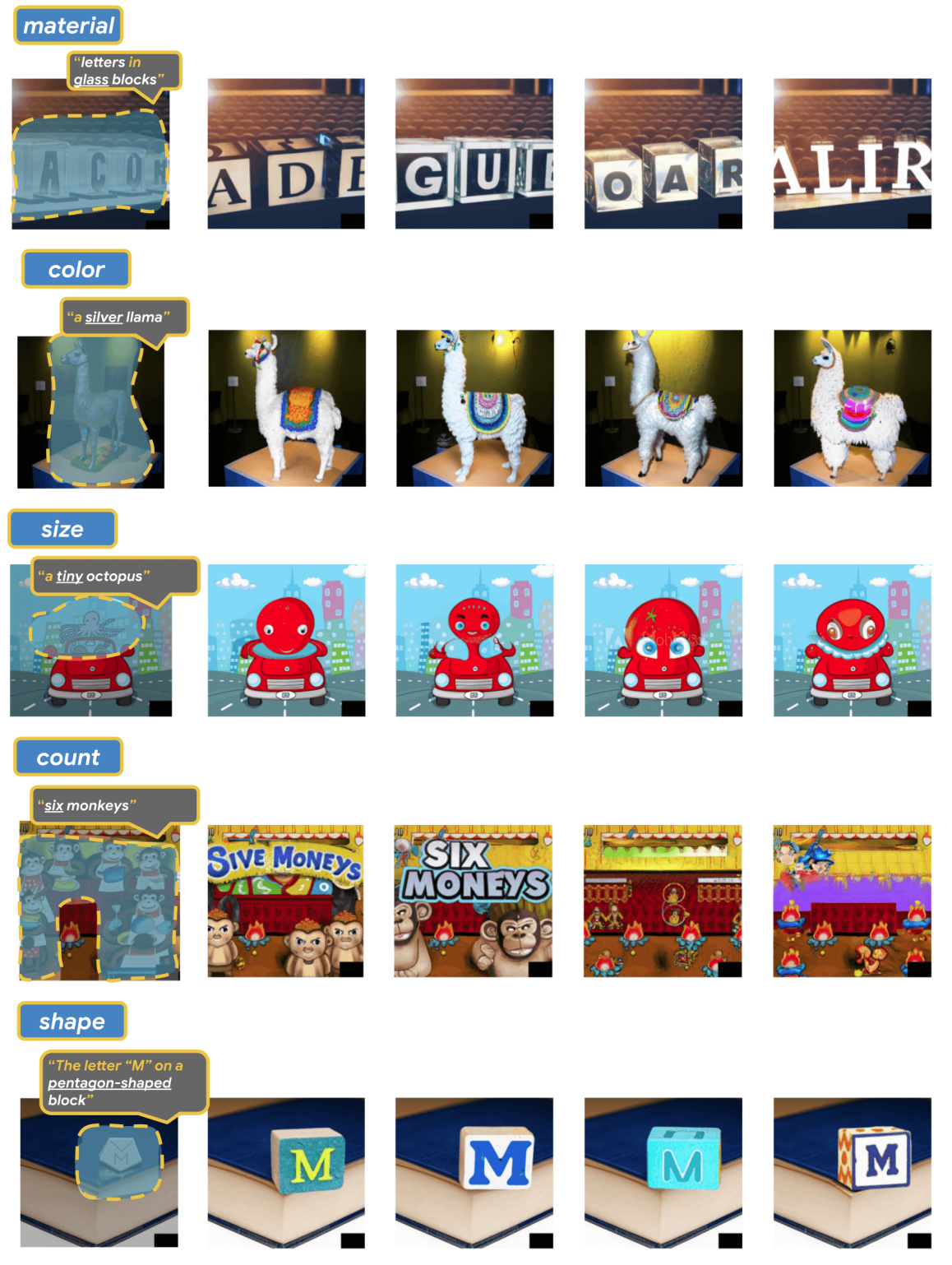
Fig. 227 Imagen Editor failure cases by attribute#
마지막으로, 동일한 prompt 에 대해 Stable Diffusion, DALL-E2, Imagen Editor 모델로 inpainting 한 결과를 비교한 예시 사진입니다.

Fig. 228 Example model outputs for Mask-Simple vs MaskRich prompts#