Information
Title: LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models
Reference
Paper: [https://arxiv.org/pdf/2305.13655]
Project Page: https://llm-grounded-diffusion.github.io/
Author: Sehwan Park
Last updated on May. 24, 2024
LLM Grounded Diffusion#
Abstract#
최근의 text-to-image generation 모델을 큰 발전을 이루었다. 하지만 이러한 모델들은 여전히 numeracy와 spatial reasoning을 요구하는 복잡한 프롬프트를 잘 반영하지 못하고 이미지를 생성하는 문제들이 있다. 그래서 본 논문에서는 LLM과 레이아웃 기반 이미지 생성모델을 활용하여 Diffusion model에서 프롬프트 이해 능력을 향상시키는 방법을 제안한다.
Introduction#
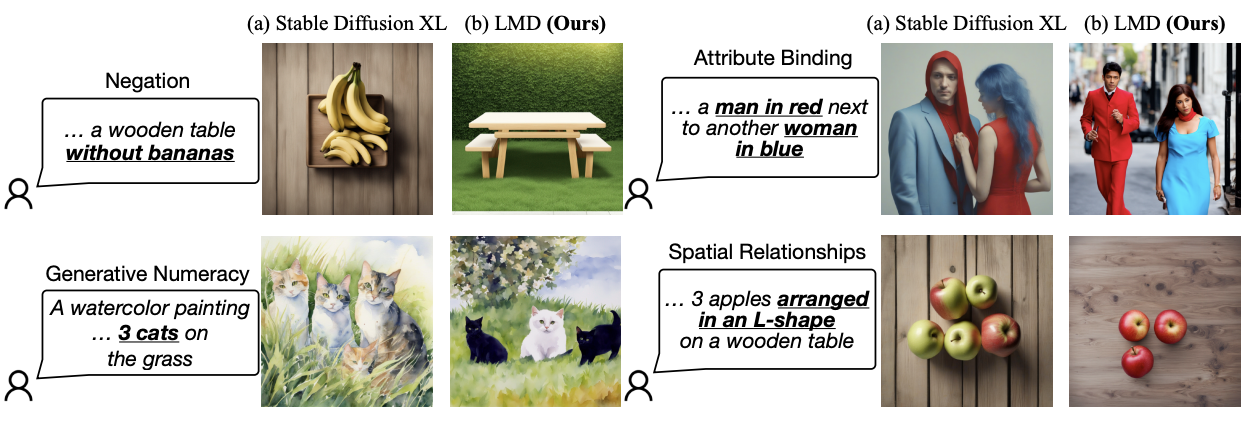
Fig. 516 Limitation in Diffusion Model#
Diffusion model의 등장과 발전에 따라 T2I(Text to Image) generation 모델은 크게 발전되어왔다. 최근의 SDXL 모델을 보면 상당한 quality의 이미지를 생성하는 것을 볼 수 있다. 그럼에도 불구하고, diffusion model은 복잡한 프롬프트를 잘 반영해서 이미지를 생성하는 것에 취약한 점을 보인다. 위의 figure를 보면 크게 Negation, Generative Numeracy, Attribute Binding, Spatial Relationships에서 큰 문제점을 보임을 알 수 있다.
가장 단순히 위의 문제를 해결하는 방법은 복잡한 프롬프트가 포함된 대규모의 multi-modal dataset을 가지고 모델을 훈련하는 방법이다. 하지만 이러한 방법은 시간과 리소스 측면에서 좋지못한 면이 있으며, 좋은 quality의 multi-modal dataset을 대규모로 확보하는 것 조차 쉽지 않은 일이다.
이러한 문제를 피하면서 위의 figure의 대표적인 문제점을 해결하기 위해 본 논문에서는 LLM 및 Layout to Image Generation 모델을 활용하여 training-free 방법으로 접근한다.
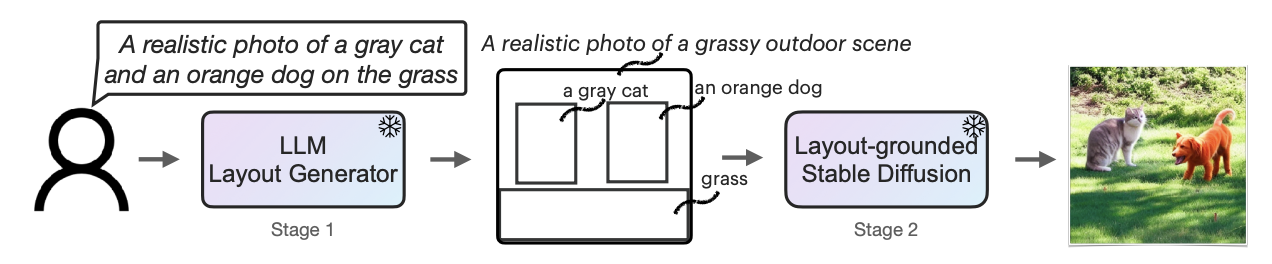
Fig. 517 Overview of LLM-Grounded Diffusion#
Stage1
주어진 prompt에 대해서 LLM을 활용하여 표현되어야 할 foreground object에 대한 layout을 생성한다. prompt로 부터 foreground object들을 해당 attribute과 함께 parsing을 하고 reasoning을 통해 올바른 bounding box coordinate을 얻는 것이 목표인 단계이다. LLM의 In-Context Learning(7-shot)을 활용하여 LLM을 Layout Generator로써 활용한다.
Stage2
Stage1으로 부터 각각의 foreground object에 대한 caption과 bounding box coordinate을 기반으로 실제 해당 bounding box에 해당 caption이 생성되도록 하는 단계이다. 이 과정에서 training-free 방법을 적용하기 위해 Stable Diffusion의 inference과정에서 attention map을 manipulate 하는 방법을 통해 Layout to image generation을 가능케한다.
본 논문의 main contribution은 다음과 같다.
We propose a training-free two-stage generation pipeline that introduces LLMs to improve the prompt understanding ability of text-to-image diffusion models.
We introduce layout-grounded Stable Diffusion, a novel controller that steers an off-the-shelf diffusion model to generate images grounded on instance-level box layouts from the LLM.
LMD enables instruction-based scene specification and allows broader language support in the prompts.
We propose a benchmark to assess the prompt understanding ability of a text-to-image model and demonstrate the superior performance of LMD over recent baselines.
LLM-grounded Diffusion#
LLM-based Layout Generation
이 단계는 위의 stage1과 같은 단계로써 LLM을 통해 prompt로 부터 각 foreground object의 caption과 bounding box의 coordinate을 얻는 단계이다.

Fig. 518 Overview Prompt#
우선 이 단계에서의 prompt는 다음과 같이 구성되어 있다. prompt의 가장 윗단인 Instruction을 보면 LLM에게 정보를 주는 말들로 이루어져 있으며 Task specification과 supporting details로 이루어져 있음을 알 수 있다. LLM에게 직접적으로 해야할 일들과 정보를 주는 prompt라고 볼 수 있다.

Fig. 519 In-context Examples#
Overview Prompt의 In-context Examples에 관련된 부분이다. 이 부분을 통해 input prompt로 부터 원하는 형태로 output값을 얻을 수 있다. LLM을 직접 학습시키지 않고 few shot example을 통해 LLM으로 부터 원하는 결과를 이끌어내는 방법을 취한 부분이다. Gpt 3.5같은 경우에는 7-shot을 사용했고, Gpt4 같은 경우는 1-shot만으로도 충분히 원하는 형태로 결과를 얻을 수 있었다고 한다. 결과는 Objects 부분에 나와있다. Foreground Object에 대한 caption값과 해당 bounding box의 coordinate값으로 이루어져 있음을 알 수 있다.
Layout-grounded Stable Diffusion
이 단계에서는 LLM이 생성한 레이아웃을 기반으로 이미지 생성을 하기 위해 컨트롤러를 도입한다. 이전의 training-free 방법을 택했던 work들의 경우, regional denoising 혹은 inference과정에서의 단순한 attention manipulation을 통해 semantic guidance를 적용하지만, 이러한 방법들은 의미 있는 영역 내 객체의 수(generative numeracy)를 제어하는 능력이 부족하다. 이는 다른 인스턴스들간의 구별이 latent space나 attention map에서 어렵기 때문에 발생하며, 이는 인스턴스 수준의 control을 힘들게 하는 요인이다. 반면, LMD(LLM-grounded Diffusion)는 각 개별 경계 상자에 대해 마스킹된 잠재 변수를 먼저 생성하고, 이러한 마스킹된 잠재 변수를 prior로 사용하여 전체 이미지 생성을 안내함으로써 인스턴스 수준의 control이 가능토록 한다. 이를통해 각 객체 인스턴스의 정확한 배치와 속성 결합을 허용한다.

Fig. 520 Overall image generation with masked latents as priors#
Stage2는 크게 step1,2로 나눠진다. step1의 경우에는 stage1에서 구한 각각의 box들에 대해서 box내의 object들에 대한 latent map을 구하는 과정이다. stage2는 stage1에서 구한 각 box에 대한 latent map을 compose하여 전체적인 image를 생성하는 과정이다.
step1
예를 들어, 위의 그림처럼 gray cat에 관한 bounding box가 stage1을 통해 구해졌다면, box안에 gray cat이 그려지도록 유도를 할 수 있을 것이다. 그러는 과정에서 저 box에 gray cat이 생성되도록 하는 마치 Ground Truth latent map을 얻을 수 있게 된다. 모든 object들에 대해 이러한 방법으로 denoising 과정에서 모든 step의 latent map을 구하는 것이다. 모든 단일 box에 대해 그 box에 해당 caption object가 생성되도록 하는 GT latent map을 구하는 게 step1의 과정이라고 생각하면 된다. 사실 상 LMD의 핵심은 step1에서 진행된다고 볼 수 있다.
크게 보자면, 각 foreground object에 대해서 \(Z_T\) 부터 \(Z_0\)까지 denoising을 거치면서 모든 step t에 대한 latent map을 구하면 된다. 이 때, 가장 중요한 것은 foreground object가 실제 box안에서 잘 생성되도록 하는것이 선행이 되어야 한다. 이를 유도하기 위해 저자들은 각 denoising step마다 box내부에 해당 foreground object가 생성되도록 attention manipulation을 진행한다.
\[ A_{uv}^{(i)} = Softmax(q_u^TK_v) \]식(1)과 같이 pixel값들과 prompt내에서의 text token 간의 cross-attention map을 나타낼 수 있다. u는 이미지 내의 모든 각 pixel들을 의미하고 v는 각 text token을 의미한다.
구성되는 프롬프트에 대해 예시를 들어 정리하자면, 전체 프롬프트가 “A realistic photo of a gray cat and an orange dog on the grass” 였다고 하자. 그러면 각 foreground object에 대해서 프롬프트를 따로 생성한다. “[background prompt] with [box caption]” (e.g., “a realistic image of an indoor scene with a gray cat”) 형태로 각 foreground object에 대한 프롬프트를 구성한다.
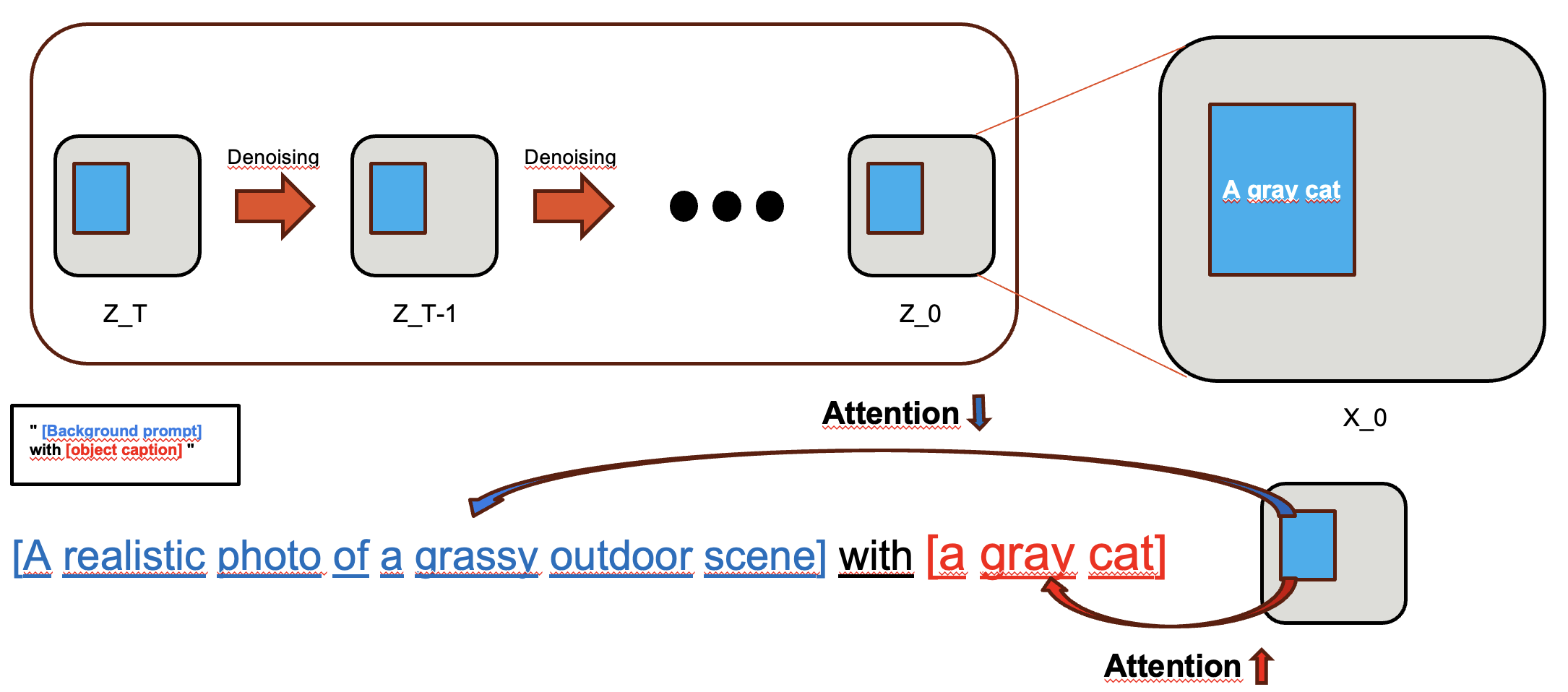
Fig. 521 Overview of attention manipulation#
Object와 Bounding box를 align하기 위해서는 위의 그림에서 보이듯이 box 내부 pixel의 object에 관한 token과의 attention은 증가되고 다른 token과의 attention은 감소되면 된다. 위의 그림을 예시로 보면 “a gray cat”이라는 token과는 box내부 pixel들이 attention이 증가하고, 다른 token과는 attention이 감소하도록 유도되면 된다. 이 방법을 유도 하기 위해 본 논문의 저자들은 energy function을 사용한다.
\[ E(A_i, i, v) = -\text{Topk}_u (A_{uv} \cdot b^{(i)}) + \omega \text{Topk}_u (A_{uv} \cdot (1 - b^{(i)})) \]식(2)의 Energy function을 보면 foreground object i에 대한 token v가 정해져 있을 때, box 내부 pixel이 token v와의 attention값이 크고 box 외부 pixel이 token v와의 attention값이 작으면 Energy function값이 최소가 됨을 알 수 있다. 정리하자면 위의 Energy function값이 최대한 작아지면 box 내부의 pixel들의 object token에 대한 attention이 증가되고, box와 foreground object간의 align이 잘 이루어지게 되는 것이다.
\[ z^{(i)}_t \leftarrow z^{(i)}_t - \eta \nabla z^{(i)}_t \sum_{v \in V_i} E(A^{(i)}, i, v) \]\[ z^{(i)}_{t-1} \leftarrow \text{Denoise}(z^{(i)}_t) \]Energy function이 최소가 되도록 하기 위해 본 논문은 식(3)과 같은 optimize과정을 거친다. 방법은 단순하다. Gradient Descent를 생각해보면 parameter로 loss function을 표현하고 loss function이 최소가 되도록 parameter들을 optimize하면서 유도한다. 이 방법 역시 같다. Energy function을 최소로 만드는 것이 목표이기에 이는 loss function과 같은 역할을 하게 된다. 그리고 Energy function의 식들은 \(z_t\)에 대해 표현이 가능하기에, Energy function을 통해 z_t를 optimize하여 Energy function이 최소화가 되도록 유도한다. Energy function 최소화는 각 denoising timestep마다 5회 반복되며, denoising 단계가 다섯 번 진행될 때마다 선형적으로 감소하여 반복 횟수가 1회로 줄어든다. 또한, 30step 후에는 guidance를 수행하지 않는다.
guidance가 진행되면서 denoising이 다 끝나고 나면 모든 step에 대한 latent map을 얻을 수 있게 되고, attention map을 얻을 수 있게 된다. 이 때 attention map을 SAM을 통해 segment를 진행하거나 threshold값을 설정하여 Foreground mask를 구하게 된다. 이후에 구한 모든 time step에 대한 latent map에 Foreground Mask와 pixel wise곱을 해주어서 masked latent를 구하게 된다.
step2
step2에서는 step1에서 구한 각 foreground object들을 compose하여 처음에 주어진 prompt에 대한 이미지를 잘 생성하는 것이 목표인 단계이다. 기존 work에 의하면 diffusion model은 denoising의 초기 단계에서 semantic한 정보들을 생성하며, 이후 단계에서부터 fine-detail한 부분을 생성한다. 이 점을 이용해서 compose를 하는 step2에서는 단순히 latent map을 compose한다음 denoising을 진행하는 것이 아니라, step의 절반 지점까지는 latent map을 compose하면서 step1과 마찬가지로 optimize를 진행하며 foreground object들이 실제로 원하는 위치에 생성되도록 유도를 하게 된다. 이후부터는 fine-detail한 부분을 생성하여 자연스러운 이미지를 만들기 위해 compose나 optimize를 하지 않고 이미지를 생성하게 된다. Compose관련 식과 optimize를 위한 step2에서의 Energy function은 아래와 같다.
\[ z^{(\text{comp})}_t \leftarrow \text{LatentCompose}(z^{(\text{comp})}_t, \hat{z}^{(i)}_t, m^{(i)}) \quad \forall i \]\[ E^{(\text{comp})}(A^{(\text{comp})}, A^{(i)}, i, v) = E(A^{(\text{comp})}, i, v) + \lambda \sum_{u \in V'_i} \left| A^{(\text{comp})}_{uv} - A^{(i)}_{uv} \right| \]최종적으로 denoising이 다 진행된 이후, decoder를 통해 latent space에서 pixel space로 변환되어 최종 이미지가 생성된다.
Evaluation#
Evaluation 같은 경우는 Qualitive한 결과와 Quantitive한 결과로 나누어서 보여준다. Introduction에서 소개한 기존 T2I model의 문제점 4가지를 잘 해결하고자 하는 것이 이 work의 목표이었기에 4가지 항목에 대해 평가를 진행한다. 데이터 같은 경우는 Negation, Attribute Binding, Generative Numeracy, Spatial Relationships를 각각 평가하기 위한 100개씩의 데이터를 수집해서 진행을 하였다고 한다. Evaluation metric이 존재하진 않고 Quantitive한 결과를 위해서 OWL-VIT detector를 활용하여 object들에 대한 bounding box값을 얻은 후에, 생성된 이미지가 prompt에 잘 맞게 생성되어있는지를 확인하였다고 한다. 추가적으로 Ablation study에 대한 다양한 결과들도 포함되어 있다.
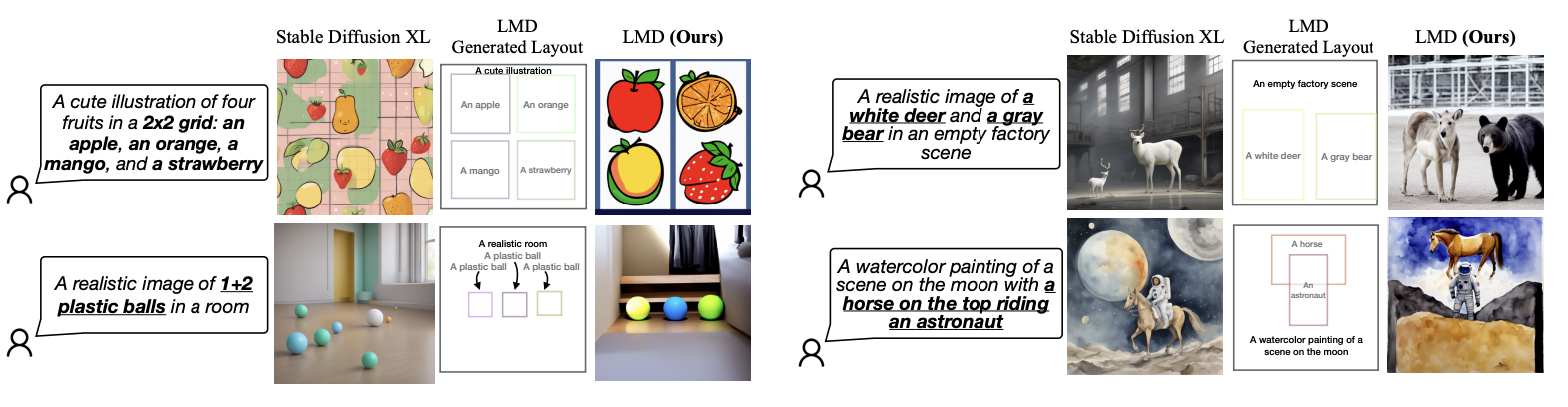
Fig. 522 Qualititive Results1 of LMD#
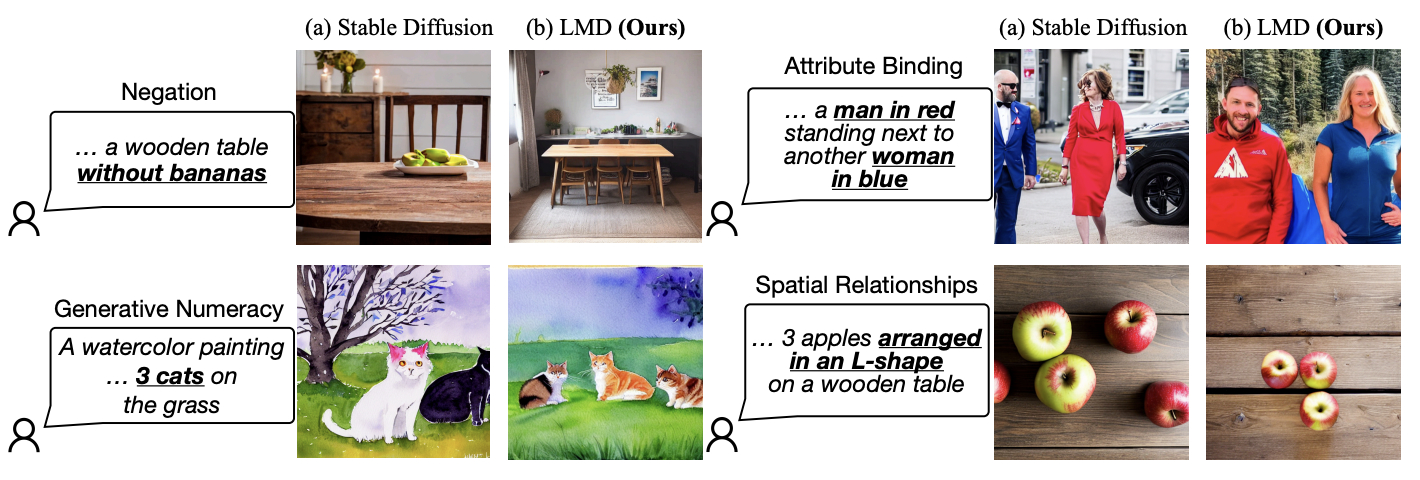
Fig. 523 Qualititive Results2 of LMD#
기존 Stable Diffusion XL 모델과 비교하여 LMD가 얼마나 prompt에 잘 대응하는 이미지를 생성하는지를 보여주는 결과이다. Introduction에서 언급했듯이 기존 SDXL모델은 이미지의 전반적인 부분은 잘 생성하지만 numarcy, spatial relationship, attribute matching등을 잘 만족시키지 못하는 경우가 발생한다. 하지만 LMD는 이러한 문제점들을 잘 해결하고 있는 것으로 보인다.
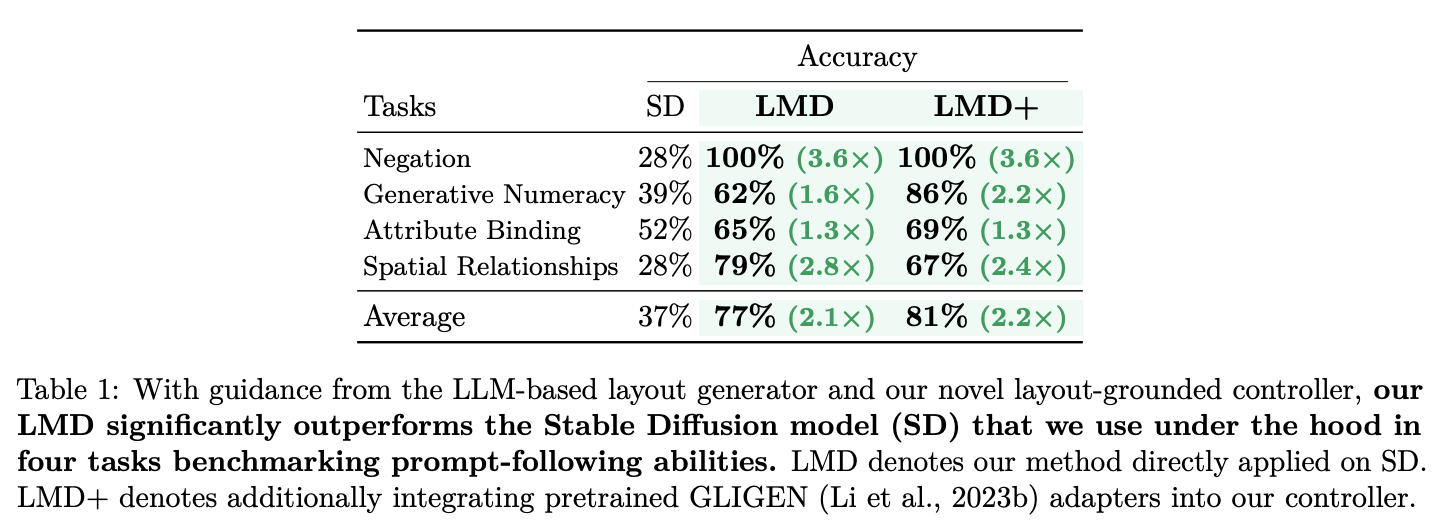
Fig. 524 Quantitive Results of LMD & LMD+#
위의 result는 기존 Stable Diffusion과 이 논문에서 제시하는 LMD 방법 그리고 기존 layout to image generation model인 GLIGEN의 adapter를 가져와서 통합한 방법인 LMD+ 세가지를 비교한다. LMD & LMD+ 모두 기존 SD에 비해 월등한 결과를 보임을 알 수 있다.

Fig. 525 Ablation of LMD & LMD+#
Ablation study의 결과를 보면, 앞선 결과와 마찬가지로 LMD가 훨씬 더 좋은 성능임을 알 수 있다. LMD의 Baseline model로 SDv1.5, SDv2.1을 각각 써본 결과 둘의 차이는 거의 없었다고 한다. 또한 Foreground mask를 구하기 위해 SAM을 사용했을 경우와 SAM을 사용하지 않고 Threshold를 사용해서 구한 결과도 보여주었는데 이는 LMD일때와 LMD+일때가 서로 다른 결과를 보인다. LMD에서는 attention기반의 guidance가 layout box와 관련하여 공간적으로 정확하지 않기 때문에, SAM은 객체를 커버하는 올바른 마스크를 얻는 데 도움을 준다. 따라서 SAM을 제거하면 LMD에서 약간의 성능 저하가 발생하게 된다. 반면에 LMD+에서는 기존 잘 훈련된 GLIGEN 모델을 가져와 이용하기 때문에 대부분의 경우 SAM이 필요하지 않게된다. 오히려, SAM은 때때로 배경을 포함하는 영역을 선택하여 혼란을 일으키고 성능을 저하시키게 되어 SAM을 제거하면 LMD+에서는 결과가 오히려 개선되는 효과가 있었다고 한다.
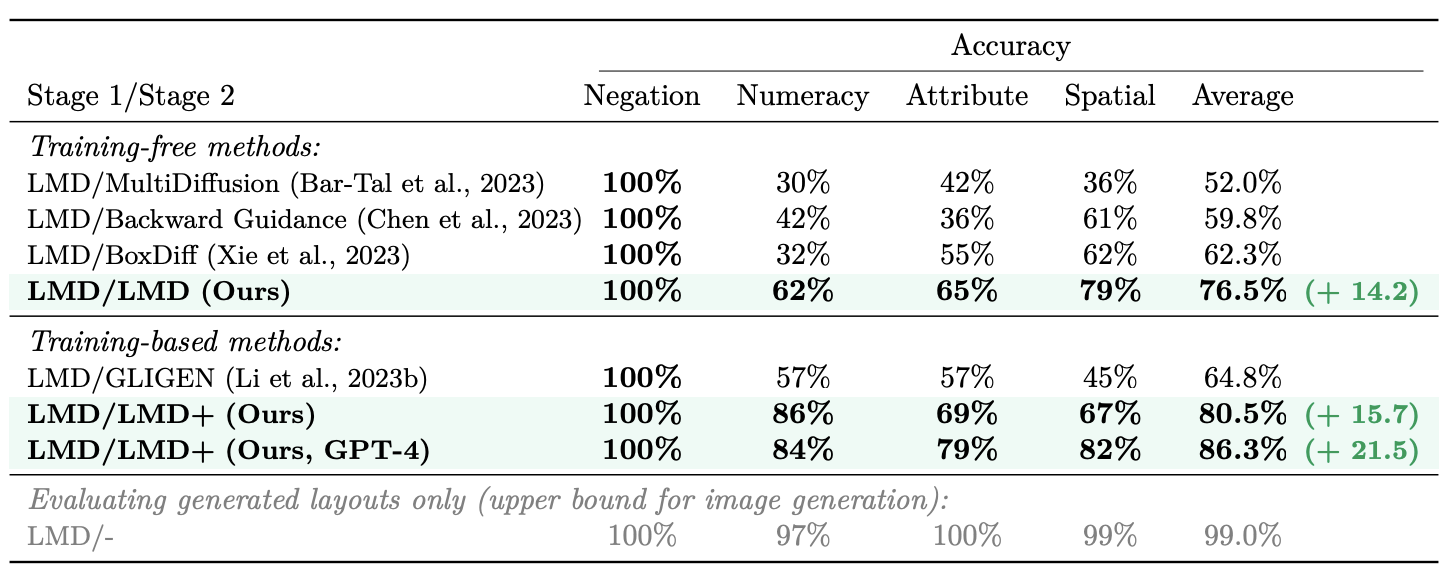
Fig. 526 Ablations on layout-to-image methods as stage 2 with LMD’s LLM layout generator as stage 1#
위의 결과는 Stage1과 Stage2에 어떤 방법을 가져왔느냐에 따른 전체적인 Quantative한 결과를 보여준다. 우선 Stage1 즉, object에 대한 개별 bounding box를 생성하는 부분에 대해서는 이 논문의 LMD기법을 다 사용을 하였다. 생성된 box를 기반으로 이미지를 생성하는 Stage 2에 대해서 training-free 방법 즉, guidance를 주는 방법을 사용한 경우와 기존 pretrain된 layout to image generation model, 여기에 LMD기법을 추가적으로 더한 방법인 training-based 방법을 나누어서 비교한다. 우선 training-free 방법의 경우, 다른 guidance 기법에 비해 이 논문에서 제시한 stage2의 방법이 훨씬 더 뛰어난 성능을 보임을 알 수 있다. training-based 방법의 경우, 기존 layout to image generation model인 GLIGEN을 그대로 가져온 경우, GLIGEN에 이 논문의 stage2 기법을 적용한 LMD+, LMD+ 에서 GPT3.5대신 GPT4를 사용한 경우로 나누어서 비교를 한다. 사실상 LMD+가 가장 좋은 성능을 보임을 알 수 있다. GPT 버전을 GPT4로 바꾼 경우는 Numeracy에서는 성능이 살짝 감소하지만, 다른 부분에 대해서는 성능이 좀 더 많이 증가한 모습을 확인할 수 있다.

Fig. 527 Ablations on GPT version + Compare with SD#
GPT같은 경우 GPT3.5-turbo를 사용한 경우와 GPT4를 사용한 경우를 나누어서 실험을 진행하였다. GPT4의 경우 1-shot으로 진행을 해도 layout을 잘 만드는 모습을 보였고, GPT3.5의 경우 7shots으로 진행을 해야 완벽하게 layout을 생성하는 결과를 보임을 알 수 있다.
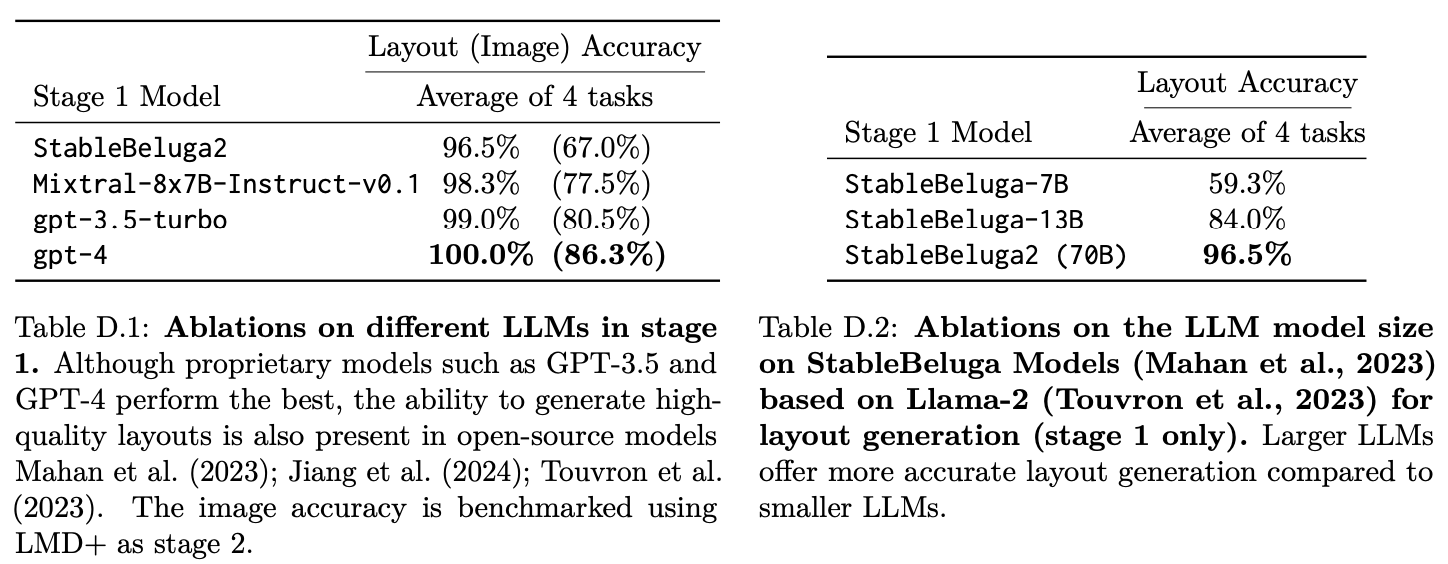
Fig. 528 Ablations on different LLM and same LLM with different size#
서로 다른 LLM을 사용해서 진행을 해본 결과, 다른 open-source model에 비해 gpt4가 확실히 좋은 성능을 보였음을 알 수 있다. 또한 똑같은 open-source model을 다른 크기로 적용해본결과 더 큰 규모의 model이 더 좋은 성능을 보임을 알 수 있다.
Summary#
LMD는 text-to-image generation diffusion model이 prompt를 더 잘 반영해서 이미지를 생성할 수 있도록 한 방법이다. 추가적인 Training을 하지 않고 prompt를 더 잘이해할 수 있도록 기존 Text to Image에서 intermediate representation인 layout을 활용한 방법이 특징이라고 할 수 있다. 두 가지 stage로 나눠 LLM-based text-grounded layout generation과 layout-grounded image generation을 통해 문제를 해결하고자 한 논문이다.