Information
Title: AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning (ICLR 2024)
Reference
Code: guoyww/AnimateDiff
Project Page : https://animatediff.github.io
Author: Kyeongmin Yu
Last updated on June. 11, 2024
AnimateDiff#
📌 논문의 의의
In this paper, we present AnimateDiff, a practical framework for animating personalized T2I models without requiring model-specific tuning.
AnimateDiff = public personalized T2I models + domain adapter & plug-and-play Motion Module + MotionLoRA
0. Abstract#
T2I diffusion model과 DreamBooth나 LoRA와 같은 개인화 기술이 발전함에 따라 사람들은 적절한 비용을 지불하여 고화질의 원하는 이미지를 얻을 수 있게 되었다. 하지만, 기존 고화질 이미지 생성 모델(personalized T2I)에 움직임을 추가하거나 애니메이션을 생성하도록 하는 것은 여전히 어렵다. 본 논문에서는 추가적인 훈련(model-specific tuning)없이 기존 고화질 이미지 생성모델에 움직임을 추가하는 실용적인 프레임 워크를 제안한다. 본 논문에서 제안하는 프레임 워크의 핵심은 plug-and-play motion module을 활용하는 것으로 이 motion module을 한번 학습하면, 어떤 이미지 생성 모델과도 융합할 수 있다. 본 논문에서 제안하는 학습 방법을 이용하면 motion module은 real-world 비디오로 부터 효과적으로 motion prior를 학습할 수 있다. 한번 학습된 motion module은 이미지 생성 모델에 덧붙여 애니메이션 생성 모델로 사용할 수 있다. 또한 AnimateDiff를 위한 간단한 파인튜닝 방식인 MotionLoRA를 제안한다. 이는 사전 학습된 motion module이 저비용으로 새로운 움직임 패턴을 학습할 수 있게 해준다. (ex. 촬영 기법) AnimateDiff와 MotionLoRA를 공개된 이미지 생성 모델에 부착하여 실험했으며 이를 통해 본 논문의 방식이 이미지 퀄리티와 다양한 움직임을 보전하면서도 자연스러운 애니메이션 클립을 생성할 수 있음을 보였다.
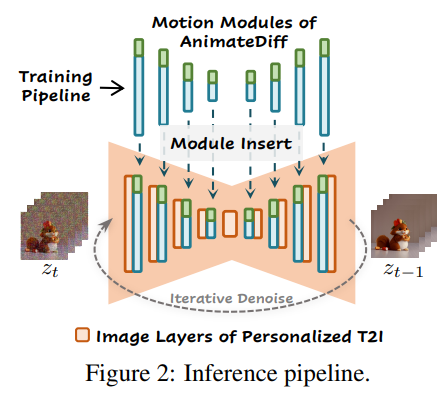
Fig. 614 inference pipeline#
Core Framework
public T2I models
personalized T2Is from the same base T2I (SD1.5)
can download finetuned T2I from civitai or hugging face
domain adapter
LoRA기반 domain adapter를 base T2I 모델에 더해 video dataset을 학습할때 발생할수 있는 domain gap을 줄였다.
여기서 말하는 domain gap이란 video의 각 프레임을 나누어 이미지로 봤을때 발생할 수 있는 motion blur, compression artifacts, watermarks등을 말한다.
training strategy of a plug-and-play motion module
learns transferable motion priors from real-world videothrough proposed training strategy
한번 학습하고 나면 다른 T2I모델과 결합해 animation generator로 사용할 수 있다.
MotionLoRA
adapt the pre-trained motion module to specific motion patterns
1. Introduction#
텍스트 프롬프트를 입력하여 이미지를 생성하는 디퓨전 모델(T2I diffusion models)의 발전으로 많은 예술가와 아마추어들이 시각 컨텐츠를 보다 쉽게 생성할 수 있게 되었다. 기존 T2I 모델의 생성능력(creativity)를 자극하기 위해 DreamBooth와 LoRA와 같은 가벼운 개인화 방식들이 제안되었다. 이러한 방식들은 작은 데이터셋과 적당한 하드웨어에서도 customized finetuning을 할 수 있게 해준다. 그로인해 사용자들이 적은 비용으로도 base T2I model을 새로운 domain에 적용하거나 시각적 퀄리티를 높일 수 있게 되었다. 그 결과 AI 아티스트와 아마추어 커뮤니티 에서 상당량의 personalized models을 Civitai나 Hugging Face와 같은 플랫폼에 개시했다. 이러한 모델들이 상당히 좋은 수준의 이미지를 생성할 수 있지만, 정적인 이미지만 생성할 수 있다는 한계가 있다. 반면, 애니메이션을 생성하는 기술이 영화나 카툰과 같은 실산업에서 더 요구된다. 본 연구에서는 고화질 T2I 모델을 파인튜닝 없이 곧바로 애니메이션 생성 모델로 변환하는 것을 목표로 한다. 파인 튜닝을 위한 데이터 수집과 컴퓨팅 자원의 필요는 아마추어 사용자에게 걸림돌이 된다.
본 논문에서는 AnimateDiff를 제안하는데 이는 personalized T2I model의 능력을 보전하면서 애니메이션을 생성하는 문제를 해결할 수 있는 효과적인 파이프라인이다. AnimateDiff의 핵심은 비디오 데이터셋(WebVid-10M)으로부터 타당한 motion 정보를 plug-and-play motion module이 학습하는 것이다. motion module의 학습은 세가지 단계로 구성된다.
domain adapter 파인튜닝
visual distribution of the target video dataset(이미지 품질차이, 동영상 워터마크, 압축으로 인한 artifacts)에 대한 부분은 이 모듈이 학습함으로써 이후 motion관련 모듈들이 motion에만 집중할 수 있도록 한다.
새로운 motion module
비디오를 입력받을수 있게 inflate시킨 base T2I 모델에 domain adapter를 더한 모델에 모션 모델링을 위한 모션 모듈을 추가한다. 이 모듈을 학습할때는 domain adapter와 base model을 freeze한다. 이렇게 하면 motion module이 움직임에 대한 부분을 전반적으로 학습하여 모듈별 학습이 가능해진다. (다른 그림체를 원할경우 base T2I+domain adapter를 바꾸면 됨)
(optional) MotionLoRA 학습
MotionLoRA의 경우 특정 motion을 적은 수의 reference videos와 학습횟수로 학습하는 것을 목표로하는 모듈이다. 이름과 같이 Low-Rank Adaptation (LoRA) (Hu et al., 2021)를 이용하는데 새로운 motion pattern을 적은수(50개)의 reference video만으로 학습시킬수 있다. 또한 차지하는 메모리도 적어 추가학습이나 모델을 공유,배포하는데에도 유리하다.
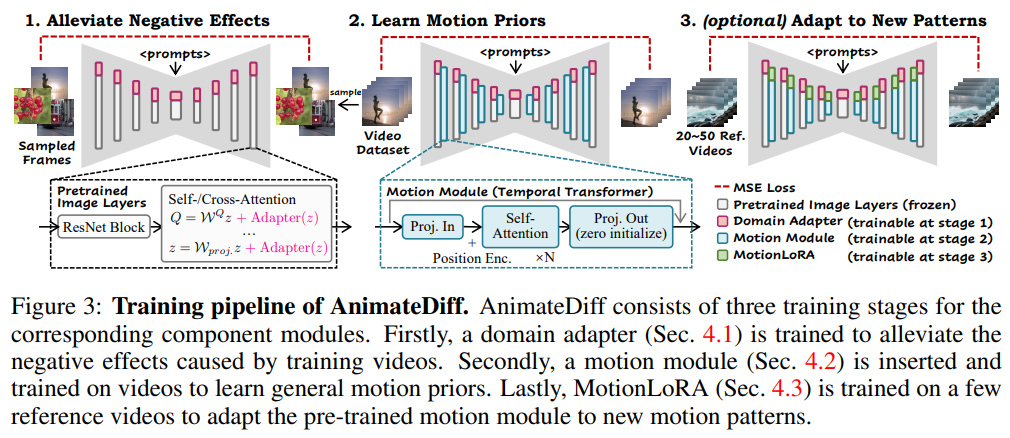
Fig. 615 training pipeline#
2. Related Work#
2.1 Text-to-image diffusion models#
Diffusion models
GLIDE (Nichol et al., 2021) 는 text condition을 통해 이미지를 생성하는 방법을 소개하고, classifier guidance를 조절하여 더 나은 이미지 결과물을 얻는 방법을 설명했다.
Guided Language to Image Diffusion for Generation and Editing
DALL-E2 (Ramesh et al., 2022)는 CLIP을 이용하여 text-image 일관성을 향상시켰다.
Imagen (Saharia et al., 2022)은 LLM과 cascade 구조를 이용하여 photorealistic한 결과물을 얻고자 했다.
**Stable Diffusion (Rombach et al., 2022)**은 auto-encoder의 latent space에서 diffusion 과정을 수행함으로써 효율을 높였다. (3.1 참고)
eDiff-I (Balaji et al., 2022) 디퓨전 모델들을 앙상블 학습시켜 generation(denoising) 단계별로 적절한 디퓨전 모델로 denoise를 수행하고자 했다.
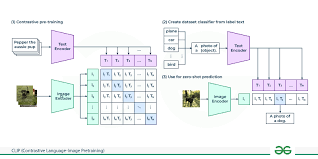
Fig. 616 CLIP:Contrastive language-image pre-training#
Fig. 617 Imagen#
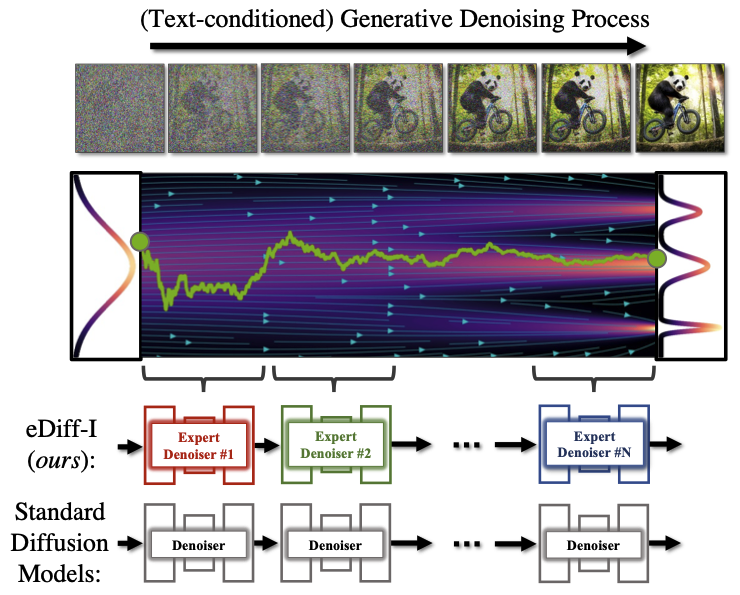
Fig. 618 eDiff-I#
2.2 Personalizing T2I models#
사전학습된 T2I 모델을 활용하기 위해 효율적인 개인화(personalization)방법에 대한 연구가 뜨겁다. 여기서 개인화란 reference images를 통해 (새로운) concepts나 style을 사전학습된 모델에 추가하는 것을 말한다. (손을 잘그리는 모델, 눈을 잘그리는 모델, 특정 그림체를 학습한 모델 등) 이를 위한 가장 단순한 방법은 전체 모델을 fine-tuning 시키는 것이다. 이를 통해 전체적인 퀄리티가 높아질 수도 있지만, 기존 학습데이터를 잊는 catastrophic forgetting이 발생할 수도 있다는 문제가 있다. 이러한 문제는 특히 reference image 데이터가 적을때 발생한다.
DreamBooth (Ruiz et al., 2023) 은 매우 적은 이미지를 사용하면서도 preservation loss를 추가하여 전체 모델을 fine-tuning 시켰다.
Textural Inversion (Gal et al., 2022) 은 새로운 concept 마다 token embedding을 최적화 하였다.
Low-Rank Adaptation (LoRA) (Hu et al., 2021) 은 LoRA layer를 추가하여 이에 대해서만 fine-tuning을 수행했다. (Sec 3.2 참고)
그외의 encoder-based approaches (Gal et al., 2023; Jia et al., 2023)
2.3 Animating personalized T2Is#
personalized T2I를 애니메이션화 시키는 연구가 많지는 않지만 아래의 연구들과 관련있다.
Text2Cinemagraph (Mahapatra et al., 2023) 는 flow prediction을 통해 cinematography를 생성하고자 했다.
Align-Your-Latent (Blattmann et al., 2023) 는 general video generator내의 frozen image layers가 personalizing이 가능함을 확인했다.
video generation models ← 결과 비교시 사용
Tune-a-Video (Wu et al., 2023) ****는 단일 비디오로 적은 수의 파라미터만 파인튜닝하는 방식을 제안했다. (SD+temporal attn 구조를 가지고 있음)
Text2Video-Zero (Khachatryan et al., 2023) 는 사전학습한 T2I모델을 활용하여 추가적인 학습과정 없이 애니메이션화 할 수 있는 방법을 제안했다. 이는 사전에 정의된 affine matrix를 사용하여 latent wrapping을 하는 방식이다.
pretrained T2I + temporal structures 관련 연구들이 많다.
(Esser et al., 2023; Zhou et al., 2022a; Singer et al., 2022; Ho et al., 2022b,a; Ruan et al., 2023; Luo et al., 2023; Yin et al., 2023b,a; Wang et al., 2023b; Hong et al., 2022; Luo et al., 2023)
3. Preliminary#
3.1 Stable Diffusion#
Stable Diffusion (Rombach et al., 2022), the base T2I model used in our work
open-sourced, well-developed community, many high-quality personalized T2I models for eval
사전 학습된 encoder(\(\mathcal E\))와 decoder(\(\mathcal D\))를 이용하여 latent space상에서 diffusion process를 수행
인코딩된 이미지 \(z_0=\mathcal E(x_0)\) 의 경우 아래의 forward diffusion 과정을 통해 \(z_t\) 변환됨
Forward diffusion for \(t=1,2,…,T\)
\[ z_t=\sqrt{\bar \alpha_t}z_0+\sqrt{1-\bar\alpha}\epsilon,\space \epsilon \sim \mathcal N(0,I) \tag{1} \]pre-defined \(\barα_t\) determines the noise strength at step \(t\)
The denoising network \(ϵ_θ(·)\) learns to reverse this process by predicting the added noise, encouraged by an MSE loss
MSE loss
\[ \mathcal L=\Bbb E_{\mathcal E(x_0),y,\epsilon \sim \mathcal N(0,I),t}\big [\| \epsilon-\epsilon_\theta(z_t,t,\tau_\theta(y))\|_2^2\big] \tag{2} \]\(y\) is the text prompt corresponding to \(x_0\)
\(τ_θ(·)\) is a text encoder mapping the prompt to a vector sequence.
In SD, \(ϵ_θ(·)\) is implemented as a UNet (down4, middle, up4 blocks; ResNet, spatial self-attn, cross-attn)
3.2 Low-Rank Adaptation(LoRA)#
Low-Rank Adaptation(LoRA) (Hu et al., 2021), which helps understand the domain adapter (Sec. 4.1) and MotionLoRA (Sec. 4.3) in AnimateDiff
language model에서 처음 등장한 개념으로 거대 모델의 fine-tuning을 빠르게 수행하기 위해 제안된 개념이다.
LoRA는 모델의 전체 파라미터를 fine-tuning하지 않고, rank-decomposition 행렬 쌍을 추가하여 새롭게 추가된 weight만 최적화 시키는 것이다.
기존 파라미터는 고정함으로써 finetuning시 발생할 수 있는 catastrophic forgetting(Kirkpatrick et al., 2017)을 예방할 수 있다.
The new model weight with LoRA
\[ \mathcal W'=\mathcal W+\vartriangle\mathcal W=\mathcal W+AB^T \tag{3} \]\(A ∈ R ^{m×r}\) , \(B ∈ R ^{n×r}\) are a pair of rank-decomposition matrices, \(r\) is a hyper-parameter, which is referred to as the rank of LoRA layers
attention layer에서만 사용할수 있는 것은 아니지만 실제로는 주로 attention layer에서 사용된다. LoRA를 통해 fine-tuning시 cost 와 storage 절약할 수 있다.
4. AnimateDiff#
➕ Architecture Overall
본 논문에서 제안하는 모델의 핵심은 비디오 데이터를 통해 transferable model prior를 학습하는 것이다. 이렇게 학습한 motion module을 personalized T2I 모델에 곧바로 적용할 수 있다.
왼쪽 그림의 하늘색 모델이 motion module이고, 초록색 영역이 optional MotionLoRA이다. AnimateDiff를 T2I모델에 삽입하여 animation generator로 사용할 수 있다.
이를 위한 AnimateDiff에는 학습해야 하는 3개의 모듈이 있다.
domain adapter - base T2I pre-training data와 our video training data간의 간극을 줄여주기 위한 것으로 학습과정에만 사용된다.
motion module
- motion prior를 학습하기 위한 모듈MotionLoRA(optional)
- pretrained motion module을 새로운 움직임 패턴(카메라 워크)으로 조정하기 위한것
Fig. 619 inference pipeline#
➕ Training Steps
본 논문에서 제안하는 각 모듈은 따로따로 학습시키며 각각을 학습시킬때 나머지 영역은 freeze 시킨다. 학습시 사용하는 objective function은 SD과 거의 같다.
Training step 1. Domain Adapter
Training step 2. Motion Module
Training step 3. Optional motionLoRA
Fig. 620 training pipeline#
4.1 Alleviate Negative Effects from Training Data with Domain Adapter#
비디오 데이터셋은 이미지 데이터셋에 비해 수집하기 어렵다. 동영상 데이터셋 WebVid (Bain et al., 2021)과 이미지 데이터셋 LAION-Aestetic (Schuhmann et al., 2022)를 비교해보면, 품질차이도 큼을 알 수 있다.
각 비디오 프레임을 개별 이미지로 다루게 되면 motion blur, compression artifacts, watermark등을 포함하고 있을 수도 있다. 따라서 T2I 모델을 훈련할 때 사용한 이미지 데이터셋에 비해 motion prior를 학습하기 위해 사용한 동영상 데이터 셋의 품질은 무시할 수 없을 만큼의 차이가 있다. 이 때문에 직접적으로 비디오 데이터셋을 이용하여 애니메이션 생성 모델을 학습할 경우, 생성한 애니메이션의 품질이 제한 될 수 있다.
동영상 데이터의 낮은 품질로 인해 해당 특성을 motion module이 학습하는 것을 피하고 base T2I의 지식을 보전하기 위해, 네트워크를 분리하여 각 도메인(영상/이미지)의 정보에 맞게 피팅하는 방식(domain adapter)을 제안한다. inference 시에는 domain adapter를 제거하였으며 앞서 언급한 domain gap에 의한 부정적 영향을 제거하는데 효과적이라는 것을 보여준다. domain adapter layer는 LoRA를 활용했으며, self-, cross-attention layer들을 base T2I model에 Fig. 3과 같이 추가하였다. 아래 query projection을 예로 살펴보면,
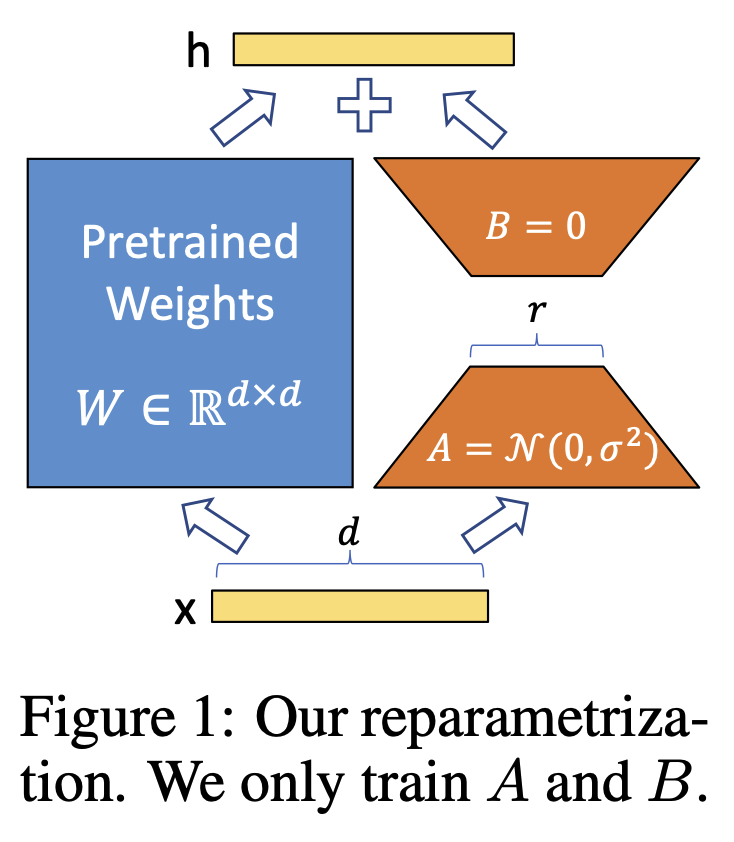
Fig. 621 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS#
\(Q\) 는 query, \(z\) 는 internal feature, \(\alpha\) 는 상수로 inference time에 domain adapter의 영향력을 조절한다. (기본값은 1 / domain adapter의 효과를 완전히 제거하고 싶다면 \(\alpha\)를 0으로) 나머지 모델의 파라미터는 freeze하고 domain adapter의 파라미터들만 비디오 데이터셋으로 부터 랜덤하게 샘플한 static frame들을 이용하여 최적화했다. 이때 objective function은 Eq. (2)를 사용했다. (아직까지는 이미지 생성 모델)
4.2 Learn Motion Priors with Motion Module#
motion dynamics를 사전학습된 T2I 모델과 공유하는 dimension상의 시간축으로 모델링 하기 위해 2가지 단계가 필요하다.
2d diffusion model을 3d 비디오 데이터에 맞게 확장시켜야 한다. (Network Inflation)
시간축상으로 효율적인 정보의 흐름을 만들기 위해 sub-module이 필요하다. (Sub-module Design)
Network Inflation
사전학습된 T2I 모델의 이미지 레이어는 고품질의 그림 사전지식(content prior)을 포착할수 있다. 이 지식을 활용(유지)하기 위해서 동일 모델로 video를 다루고자 할 때는 기존 이미지 레이어는 독립적으로 내버려두고, network를 확장시키는 방향이 선호된다. 이를 위해 기존 연구 (Ho et al., 2022b; Wu et al., 2023; Blattmann et al., 2023)를 참고하여, 5d tensor \(x\in \Bbb R^{b\times c \times f\times h\times w}\) 를 입력으로 받도록 모델을 수정했다. \(b\)는 batch, \(f\)는 frame을 뜻한다. 내부 feature map이 이미지 레이어를 지나갈때는 시간 축을 의미하는 \(f\)는 \(b\)축으로 reshaping을 통해 무시한다.
(5d tensor → 4d tensor \(x \in \Bbb R^{bf\times c \times h\times w}\) → (기존 이미지 레이머) → 4d tensor → 5d tensor)
이를 통해 각 프레임을 개별 이미지 처럼 독립적으로 처리할 수 있다. 반면에 새롭게 추가된 motion module은 공간축(\(h,w\))을 reshaping하여 무시한다. (5d tensor → 3d tensor \(x \in \Bbb R^{bhw\times c \times f}\) → (motion module) → 3d tensor → 5d tensor)
Module Design
최근 비디오 생성 연구들은 temporal modeling의 다양한 방식을 탐구하고 있다. AnimateDiff에서는 Transformer 구조를 차용하여 시간축상에서 동작하도록 작은 수정을 거쳐 motion module을 design했다. (이하 temporal Transformer) 실험을 통해 해당 구조가 motion prior를 모델링하는데 적합하다는 것을 발견했다. Fig.3을 보면 temporal Transformer가 시간축에서 동작하는 여러 self-attn block으로 이루어진것을 볼수 있다. 또한 sinusoidal position encoding을 통해 애니메이션상의 각 프레임의 시간적 위치정보를 나타내고자 했다. 앞서 언급한 대로 motion module의 입력크기는 feature map을 reshaping하여 조절하였다. (\(x \in \Bbb R^{bhw\times c \times f}\)) feature map을 시간축으로 다시 펼치고자 할때는 다음과 같은 길이 \(f\), 크기 \(z_1, ...,z_f;z_i \in \Bbb R^{(b\times h\times w)\times c}\)의 vector sequence로 다룰수 있다. 해당 크기의 벡터가 self-attn block을 통과하면 다음과 같다.
\(Q=W^Qz, K=W^Kz, V=W^Vz\) 이며, 각각 분리된 세 projection을 의미한다. attention mechanism을 통해 현 프레임의 생성에 다른 프레임으로 부터 추출된 정보를 반영하는 것이 가능하다. 결과적으로 각 프레임을 개별적으로 생성하는 것이 아닌, T2I 모델을 확장하여 motion module을 추가한 AnimateDiff가 시간에 따른 visual content의 변화를 잘 포착하기 위해 학습하여 motion dynamics를 이용해 animation clip을 제작하도록 한다. self-attn block전에 sinusoidal position encoding을 잊어서는 안된다. 하지만 motion module 자체가 frame의 순서를 알고 있는 것은 아니다.
추가적인 모듈을 넣음으로 인해 발생할수 있는 문제들을 피하기 위해 temporal Transformer의 레이어의 파라미터는 0으로 초기화 하였으며 residual connection을 추가하여 훈련 시작시에 motion module이 identity mapping으로 동작하도록 했다.
4.3 Adapt to New Motion Patterns with MotionLoRA#
전반적인 motion 지식을 motion module이 사전학습하더라도 새로운 동작 패턴에 대한 적용에 대한 문제는 발생한다. ex. zooming, panning, rolling.
높은 사전학습을 위한 비용을 감당할 수 없어 motion module을 특정 액션에 맞춰 튜닝하고자 하는 사용자를 위해 적은 참고 비디오(reference video)나 적은 훈련 횟수로도 효율적으로 모델을 적용할 수 있도록 하는 것이 중요하다. 이를 위해 AnimateDiff에 MotionLoRA를 마지막으로 적용했다. Motion Module의 구조와 제한된 참고 비디오를 고려하여, self-attn layers에 LoRA layers를 inflated model에 추가하여 motion personalization을 위한 효율적인 파인튜닝 방법을 제안한다.
몇 종의 촬영 방식으로 실험을 진행하였으며 rule-based augmentation을 통해 reference videos를 얻었다. 예를 들어 zooming 비디오를 얻기 위해 시간에 따라 비디오 프레임을 점차 줄이거나(zoom-in) 늘려가며(zoom-out) augmentation을 진행했다. AnimateDiff의 MotionLoRA는 20~50개 정도의 적은 참고 비디오, 2000번의 훈련횟수로 파인튜닝했을때도 괜찮은 결과를 보였다. low-rank property로 인해 MotionLoRA 또한 composition capability를 가지고 있다. 학습된 MotionLoRA 모델 각각이 inference time상의 motion effect를 융합하기위해 협력(combine)할 수 있음을 말한다.
4.4 AnimateDiff in Practice#
Training#
Fig. 3을 보면 AnimateDiff에는 학습 가능한 모듈이 3개 있다. 각 모듈의 objective는 약간씩 다르다. domain adapter는 SD의 MSE loss인 Eq. 2 objective function을 통해 학습한다. 애니메이션을 만드는 역할을 하는 motion module과 motion LoRA의 경우 video data에 대한 차원을 더 많이 수용하기 위해 약간 수정된 objective를 사용한다. video data batch ( \(x_0^{1:f}\in \Bbb R^{b\times c \times f \times h \times w}\))는 사전학습된 SD의 auto-encoder를 사용해 각 프레임 별로 latent code \(z_0^{1:f}\)로 인코딩된다. 이 latent code는 Eq. 1 과 같이 정의된 diffusion schedule에 따라 노이즈가 추가(forward process)된다.
모델의 입력은 노이즈가 추가된 latent codes와 이 쌍이되는 text prompts이며, 모델은 forward process에서 추가된 노이즈를 예측한다. AnimateDiff의 motion module을 위한 최종 training objective는 아래와 같다.
각 모듈들(domain adapter, motion module, MotionLoRA)을 학습할때, 학습 타겟을 제외한 영역은 freeze 시킨뒤 학습했다.
Inference#
inference시에는 personalized T2I model는 앞서 설명한대로 inflate되며 motion module과 (optional) MotionLoRA를 더해 애니메이션을 생성한다.
domain adapter의 경우 inference시 그냥 배제하지 않고 personalized T2I model에 injection하였으며 domain adapter의 영향력은 Eq. 4의 \(\alpha\)를 이용해 조절했다. Sec 5.3의 Ablation study에서 \(\alpha\)의 값에 따른 결과의 차이를 확인할 수 있다. 마지막으로 animation frames은 reverse diffusion process와 이를 통해 얻은 latent codes를 디코딩 함으로써 얻을수 있다.
5. Experiments#
SD 1.5에 AnimateDiff를 적용하여 실험을 진행했다. 또한 motion module을 학습할때는 WebVid 10M 데이터셋을 사용하였다. (자세한 사항은 supplementary material 확인해주세요)
5.1 Qualitative Results#

Fig. 622 qualitative results#
5.2 Quantitative Comparison#
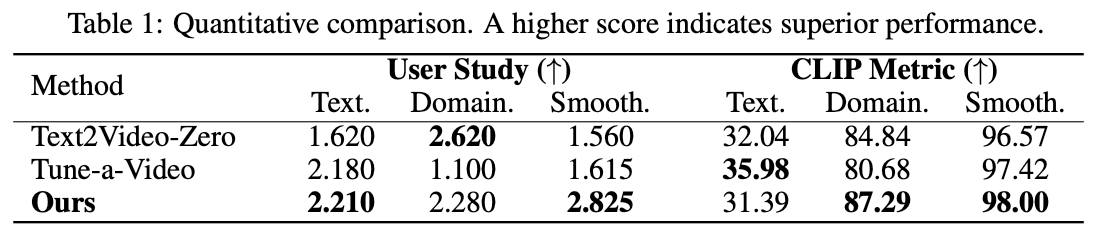
Fig. 623 quantitative results#
User Study
text, domain, smooth 3개 지표에 대한 개별 등수를 조사했다. Average User Ranking(AUR) 방법을 사용하여 높은 점수를 가지면 높은 품질을 의미하는 preference metric을 사용했다.
CLIP metric
related paper에서 언급했던 이미지와 텍스트쌍을 동시에 학습한 CLIP 모델을 활용한 평가지표이다. 사전학습된 CLIP 모델을 사용하여 generated frames와 reference 사이 CLIP score를 계산한 것이다.
+) CLIP score는 CLIP encoder를 통과한 벡터들 사이 코사인 유사도를 계산하는 방식
Text
각 프레임 임베딩과 주어진 텍스트 임베딩 사이 코사인 유사도
Domain
원본 애니메이션이 없으므로 reference image와 생성된 영상 사이 CLIP score를 구함.
Smooth
연속된 프레임 쌍의 이미지 임베딩의 코사인 유사도
5.3 Ablation Study#
Domain Adapter#

Fig. 624 scaler를 0으로 하면 domain adapter에 의한 효과를 제거한 것과 같다. 위의 그림은 모델이 생성한 animation clip의 첫번째 프레임이다.#
domain adapter에 의한 효과를 제거했을때 전체적인 이미지 퀄리티가 높아 보이는데, 이는 domain adapter가 video dataset의 특성이라고 할 수 있는 watermark나 모션 블러 등을 학습했기 때문이다. 즉, domain adapter가 전체 학습과정에 도움이 되었음을 보여준다.
Motion module design#
AnimateDiff의 temporal Transformer구조와 전체 convolution인 구조의 모델과 비교했다. 두 방식 모두 비디오 생성 분야에서 자주 사용된다.
temporal Transformer의 temporal attention부분을 1D temporal convolution으로 교체하여 두 모델의 파라미터가 유사하게 놓여있음을 확인했다. convolution motion module은 모든 프레임을 동일하게 놓았지만 Transformer 구조와 비교하여 움직임을 제대로 반영하지 못했다.
Efficiency of MotionLoRA#
parameter efficiency와 data efficiency 측면에서 MotionLoRA의 효율성을 시험해보았다. 이를 위해 parameter 개수와 data 개수를 조절해가며 여러 MotionLoRA를 학습시켰다.

Fig. 625 Efficiency of MotionLoRA#
Parameter efficiency
효율적인 모델학습을 위해도 모델의 배포를 위해서도 중요한 부분이다.
AnimateDiff는 비교적 파라미터 개수가 적들때에도 괜찮은 애니메이션을 만들수 있다. 그림의 실험에서는 zoom-in 카메라 움직임을 새롭게 학습하는 능력을 본것이다.
Data efficiency
특정 motion pattern을 위한 reference video 데이터를 수집하기 어렵기 때문에 모델을 실제로 적용하기 위해 중요한 부분이다.
데이터의 개수가 적을때에도 학습하고자 하는 움직임은 학습할 수 있었으나 데이터의 개수가 극도로 적을 경우(N=5) 생성된 애니메이션 품질의 급격한 저하가 있었다.
5.4 Controllable Generation#

Fig. 626 Controllability of AnimateDiff#
visual content와 motion prior의 개별 학습을 통해 AnimateDiff가 existing content를 조절할 수 있도록 했다. 이 특성을 확인하기 위해 AnimateDiff를 ControlNet과 결합하여 영상 생성시 depth를 통해 조절할 수 있도록 했다.
DDIM inversion을 통해 다듬어진 latent sequences를 얻고 이를 비디오 생성에 사용하는 최신 비디오 수정 연구들과 비교하여 AnimateDiff는 randomly sampled noise를 이용하여 애니메이션을 생성한다.
6. Conclusion#
본 논문에서는 애니메이션 생성을 위한 practical pipeline인 AnimateDiff를 제안한다. AnimateDiff를 통해 personalized text-to-image model을 바로 애니메이션 생성에 사용할 수 있다. 이를 위해 본 논문에서는 세가지 module을 디자인하였으며 이를 통해 AnimateDiff는 motion prior를 학습하고, visual quality를 유지할 수 있으며, MotionLoRA를 통해 가벼운 finetuning을 통해 원하는 motion으로 애니메이션을 생성할 수 있다.
motion module은 한번 학습되면 다른 이미지를 animate시키고자 할때 사용할 수 있다. 다양한 실험 결과를 통해 AnimateDiff와 MotionLoRA의 효율성과 생성능력을 검증했다. 또 content-controllability측면에서도 추가적인 학습없이 본 논문의 방식을 사용할 수 있음을 보였다.
AnimateDiff는 취향의 그림체, 캐릭터의 움직임, 카메라 워크에 맞게 이미지를 애니메이션화 시킬 수있는 효율적인 베이스 라인으로써 다양한 방면의 application에 큰 잠재력을 가지고 있다.
7. 실습#
아래 이미지들을 클릭하면 gif를 보실 수 있습니다.

Fig. 627 side-view-photo-of-17-year-old-girl-in-a-japanese-school
gpt로 생성한 그림을 input으로 사용함#

Fig. 628 side-view-photo-of-man-in-black-padded-jumper
직접 촬영한 사진을 input으로 사용함
입력한 사진의 인물의 인종이 유지되지 않았는데 학습데이터 셋의 불균형 때문으로 사료됨#

Fig. 629 image-of-a-man-with-blonde-hair-and-blue-eyes
gpt로 생성한 그림을 input으로 사용함#
📌 실습 후 느낀점
WebVid 10M이 애니메이션화에 적합한 데이터셋인지 잘 모르겠다.
다양한 metric을 평가에 사용하지 않은 점이 아쉽다.
특정 애니메이션 클립을 생성하고 싶다면 실질적으로 학습해야 하는 부분은 motionLoRA정도라 사용이 편리하다.
reproduction이 매우 용이하다.
AnimateDiff를 제대로 활용하기 위해서는 personalized T2I가 제일 중요한 부분이라고 할수 있는데, 원하는 스타일의 pretrained T2I 모델을 구하는 것이 어렵다. 그림체가 잘 맞지 않으면 애니메이션 클립 초반에 급격히 변화하는 부분이 자주 생긴다.