Information
Title: DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
Reference
Author: Jeonghwa Yoo
Last updated on May. 08, 2023
DreamPose#

Fig. 647 DreamPose 입출력#
1. Introduction#
DreamPose가 제안된 배경
패션 사진은 온라인에 널리 퍼져 있지만, 전달할 수 있는 정보가 제한적이며 입었을 때 옷의 늘어진 모양이나 흐름 등 옷의 중요한 뉘앙스를 포착하지 못한다.
패션 동영상은 이러한 모든 디테일을 보여주기에 소비자의 의사 결정에 유용한 정보를 제공하지만, 동영상이 있는 상품은 매우 드물다.
DreamPose
본 논문에서는 포즈 시퀀스를 따라 패션 사진을 사실적인 애니메이션 비디오로 변환하는 방법인 DreamPose를 소개한다.
Stable diffusion을 기반으로 한다.
하나 이상의 사람 이미지와 포즈 시퀀스가 주어지면, 포즈 시퀀스를 따라 고품질 비디오를 생성한다.
기존 비디오 생성 모델들의 문제점
이미지 생성 디퓨전 모델은 좋은 결과를 보여주었지만, 비디오 생성 디퓨전 모델은 동일한 품질의 결과를 얻지 못했으며, 텍스처 움직임이나 카툰과 같은 모양으로 제한된 경우가 많다.
시간적 일관성이 떨어진다.
모션 jitter가 발생한다.
사실성(realism)이 부족하다.
대상 비디오의 움직임이나 세부적인 물체 모양을 제어할 수 없다.
기존 모델이 주로 텍스트에 기반으로 하기 때문에
DreamPose의 접근법
이미지 및 포즈 시퀀스를 조건으로 받는 방식을 사용하여 fidelity와 프레임 간 일관성을 높일 수 있다.
이미지 분포를 효과적으로 모델링하는 기존 사전 학습된 이미지 디퓨전 모델을 파인 튜닝하였다. → 이미지 애니메이션 태스크를 컨디셔닝 신호와 일치하는 이미지의 부분 공간을 찾는 것으로 단순화 할 수 있다.
해당 태스크를 위해 스테이블 디퓨전의 인코더와 컨디셔닝 메커니즘을 재설계하였다.
2-스테이지 파인튜닝 방식을 사용한다
UNet과 VAE를 하나 혹은 여러 입력 이미지에 대해서 파인튜닝
Contribution
DreamPose: 패션 이미지 애니메이션을 위해 이미지 및 포즈를 조건으로 하는 디퓨전 방식
프레임 간 시간적 일관성을 크게 향상 시키는 간단하지만 효과적인 포즈 컨디셔닝 방식
컨디셔닝 이미지의 fidelity를 높여주는 split CLIP-VAE 인코더
이미지의 fidelity와 새로운 포즈에 대한 일반화 사이의 균형을 효과적으로 맞추는 파인튜닝 전략
3. Background#
디퓨전 모델
디퓨전 모델은 품질, 다양성, 학습 안정성 측면에서 합성 태스크에서 GAN을 능가하는 최신 생성 모델이다.
표준 이미지 디퓨전 모델은 정규 분포된 랜덤 노이즈에서 이미지를 반복적으로 복원하는 방법을 학습한다.
Latent diffusion model (ex. Stable Diffusion)

Fig. 648 Latent Diffusion Model#
오토인코더의 인코딩된 latent space에서 작동하므로 최소한의 품질을 희생하면서 계산 복잡성을 절약한다.
스테이블 디퓨전 모델은 VAE와 디노이징 UNet의 두 가지 모델로 구성된다.
VAE 오토인코더
인코더 \(\mathcal{E}\): 프레임 \(x\)를 컴팩트한 latent 표현 \(z\)로 추출 (\(z=\mathcal{E}\)\((x)\))
디코더 \(\mathcal{D}\): latent 표현에서 이미지를 복원 (\(x’=\mathcal{D}(z)\))
학습하는 동안, latent feature \(z\)는 결정론적 가우시안 프로세스에 의해 타임 스탬프 \(T\)로 디퓨즈되어 노이지 feature인 \(\tilde{z}_T\)를 만듦
원본 이미지를 복구하기 위해 각 타임스탬프에 해당하는 latent feature의 노이즈를 반복적으로 예측하도록 시간으로 컨디셔닝된 UNet이 학습 된다.
UNet의 목적 함수
\[ \begin{align}{\cal L}_{D M}=\mathbb{R}_{z,\epsilon\in{\mathcal{N}}(0,1)}[||\epsilon-\epsilon_{\theta}({\tilde{z}}_{t},t,c)]|_{2}^{2}]\end{align} \]c: 컨디셔닝 정보의 임베딩 (텍스트, 이미지, 세그멘테이션 마스크등, 스테이블 디퓨전에서는 CLIP 텍스트 인코더로부터 얻어짐
예측된 latent \(z’\)은 예측된 이미지 \(x’ = \mathcal{D}(z')\)를 복구하도록 디코딩 된다.
Classifier-free guidance
Implicit classifier를 통해 예측된 노이즈 분포를 조건으로 주어진 분포로 밀어붙이는 샘플링 메커니즘이다.
이는 랜덤한 확률로 실제 조건으로 주어진 입력을 널 입력(∅)으로 대체하는 훈련 방식인 드롭아웃을 통해 달성된다.
인퍼런스하는 동안 조건으로 주어진 예측은 스칼라 가중치 s를 사용하여 unconditional한 예측을 조건부로 가이드하는 데 사용된다.
\[ \begin{align}\epsilon_{\theta}=\epsilon_{\theta}(\tilde{z}_{t},t,\emptyset)+s\cdot(\epsilon_{\theta}(\tilde{z}_{t},t,\mathrm{c})-\epsilon_{\theta}(\tilde{z}_{t},t,\emptyset))\end{align} \]\(\epsilon_{\theta}(\tilde{z}_{t},t,\emptyset)\): 조건이 없는 경우에 노이즈 벡터
\(\epsilon_{\theta}(\tilde{z}_{t},t,c)\): 조건이 있는 경우에 노이즈 벡터
→ 조건을 Null로 줬을 때의 모델의 예측값과 조건을 줬을 때의 모델이 예측값을 보간한다.
4. Method#
본 논문에서는 단일 이미지와 포즈 시퀀스로부터 사실적인 애니메이션 동영상을 만드는 것을 목표로 한다.
이를 위해 패션 동영상 컬렉션에서 사전 학습된 스테이블 디퓨전을 패션 동영상 컬렉션에 맞게 파인튜닝한다.
추가 컨디셔닝 신호(이미지 및 포즈)를 받고 동영상으로 볼 수 있는 시간적으로 일관된 콘텐츠를 출력하기 위해 스테이블 디퓨전의 구조를 조정하는 작업이 포함된다.
4.1. Overview#
입출력
입력: 입력 이미지 \(x_0\), 포즈 \(\{p_1, …, p_n\}\)
출력: 비디오 \(\{x'_1, …, x’_N\}\) (\(x’_i\): 입력 포즈 \(p_i\)에 해당하는 i 번째 예측된 프레임)
입력 이미지와 포즈 시퀀스를 조건으로 하는 사전 훈련된 latent diffusion model을 사용한다.
추론 시에는 일반적인 디퓨전 샘플링 절차를 통해 각 프레임을 독립적으로 생성한다.
균일하게 분포된 가우시안 노이즈로 시작하여 두 조건 신호로 디퓨전 모델을 반복적으로 쿼리하여 noisy latent의 노이즈를 제거한다.
마지막으로 예측된 디노이즈된 latent \(z’_i\)를 디코딩하여 예측된 비디오 프레임 \(x’_i=\mathcal{D}(z’_i)\)를 만든다.
4.2. Architecture#
이미지 애니메이션을 위해 원래의 text-to-image 스테이블 디퓨전 모델을 수정하고 파인튜닝한다. (조건: 이미지, 포즈)
이미지 애니메이션의 목표
제공된 입력 이미지에 대한 충실도
시각적 품질
생성된 프레임의 전반적인 시간적인 안정성
이러한 목표를 달성하기 위해 아키텍처를 아래와 같이 구성하였다.
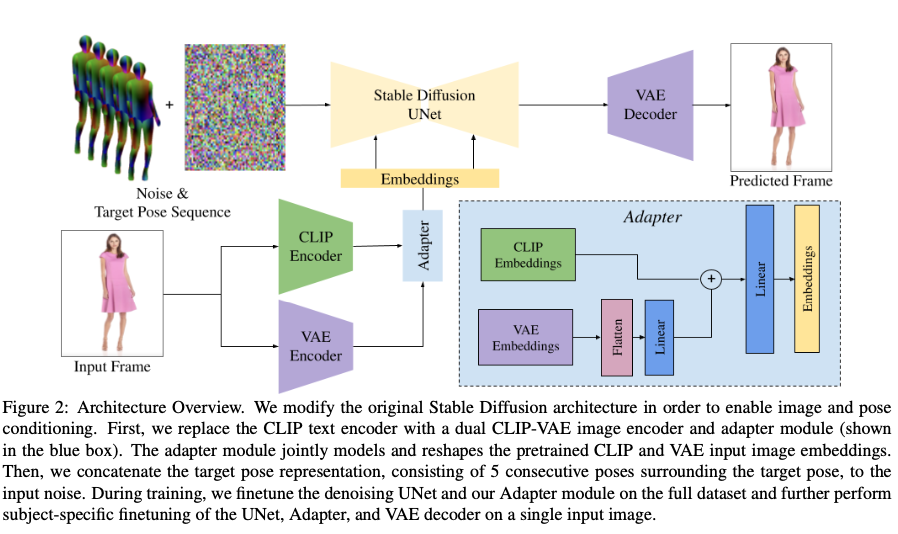
Fig. 649 DreamPose Architecture#
4.2.1 Split CLIP-VAE Encoder#
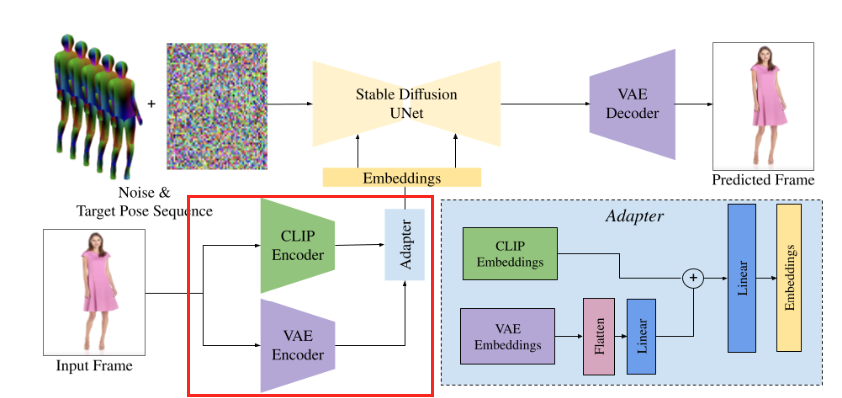
Fig. 650 DreamPose Encoder#
해당 모듈-컨디셔닝 어댑터(custom conditioning adapter)의 필요성
이미지를 조건으로 넣기 위한 이전 연구 (ex: InstructPix2Pix)는 주로 조건으로 들어오는 이미지 신호를 디노이징 U-Net에 대한 입력 노이즈와 concat한다.
이는 원하는 출력 이미지와 공간적으로(spatially) 정렬된 조건 신호에 대한 조건화에 효과적이지만, DreamPose의 경우에는 네트워크가 입력 이미지와 공간적으로 정렬되지 않은 이미지를 생성하는 것을 목표로 한다.
따라서 해당 태스크에는 다른 방법이 필요하고, 이를 위해 맞춤형 컨디셔닝 어댑터를 구현하였다.
맞춤형 컨디셔닝 어댑터는 CLIP 텍스트 인코더를 사용하여 이미지 조건화를 대체하는 맞춤형 컨디셔닝 어댑터(custom conditioning adapter)를 구현하였다.
이 어댑터는 사전 학습된 CLIP 이미지 및 VAE 인코더에서 인코딩된 정보를 결합한다.
디퓨전 기반 파인튜닝
목표: 입력 신호를 원래 네트워크 학습에 사용된 신호와 최대한 유사하게 만들어 학습 기울기를 가능한 한 의미 있게 만드는 것 → 학습된 prior 값의 손실을 방지하는 데 도움이 된다.
이러한 이유로 대부분의 디퓨전 기반 파인튜닝 체계는 모든 원래 컨디셔닝 신호를 유지하고 새로운 컨디셔닝 신호와 상호 작용하는 네트워크 가중치를 0으로 초기화한다.
VAE Encoder의 필요성
스테이블 디퓨전이 텍스트 프롬프트의 CLIP 임베딩으로 컨디셔닝 되고 CLIP이 텍스트와 이미지를 공유 임베딩 스페이스(shared embedding space)로 인코딩한다는 점을 감안할 때 CLIP 컨디셔닝을 조건으로 주어진 이미지에서 파생된 임베딩으로 간단히 대체하는 것이 자연스러워 보일 수 있다.
하지만 실제로는 CLIP 이미지 임베딩만으로는 조건으로 주어진 이미지에서 세밀한 디테일을 캡처하기에 충분하지 않다.
따라서 스테이블 디퓨전의 VAE에서 인코딩된 latent 임베딩을 추가로 입력한다.
이를 통해 디퓨전의 출력 도메인과 일치하는 추가적인 장점을 가지게 된다.
어댑터 \(\mathcal{A}\)
스테이블 디퓨전 아키텍처는 기본적으로 컨디셔닝 신호로 VAE latent를 지원하지 않기 때문에 어댑터 모듈 \(\mathcal{A}\)를 추가한다.
해당 어댑터는 CLIP과 VAE 임베딩을 결합하여 네트워크의 일반적인 cross-attention 연산에 사용되는 하나의 임베딩을 생성한다.
이 어댑터는 두 신호를 함께 혼합하고 디노이징 U-Net의 cross-attention 모듈에서 예상하는 일반적인 모양으로 출력을 변환한다.
디퓨전 기반 파인튜닝에서 언급했 듯이 학습에서 네트워크의 충격을 완화하기 위해 처음에는 VAE 임베딩에 해당하는 가중치는 0으로 설정되어 네트워크가 CLIP 임베딩으로만 학습을 시작한다.
최종 이미지 컨디셔닝 신호 \(c_I\)를 다음과 같이 정의한다.
4.2.2 Modified UNet#
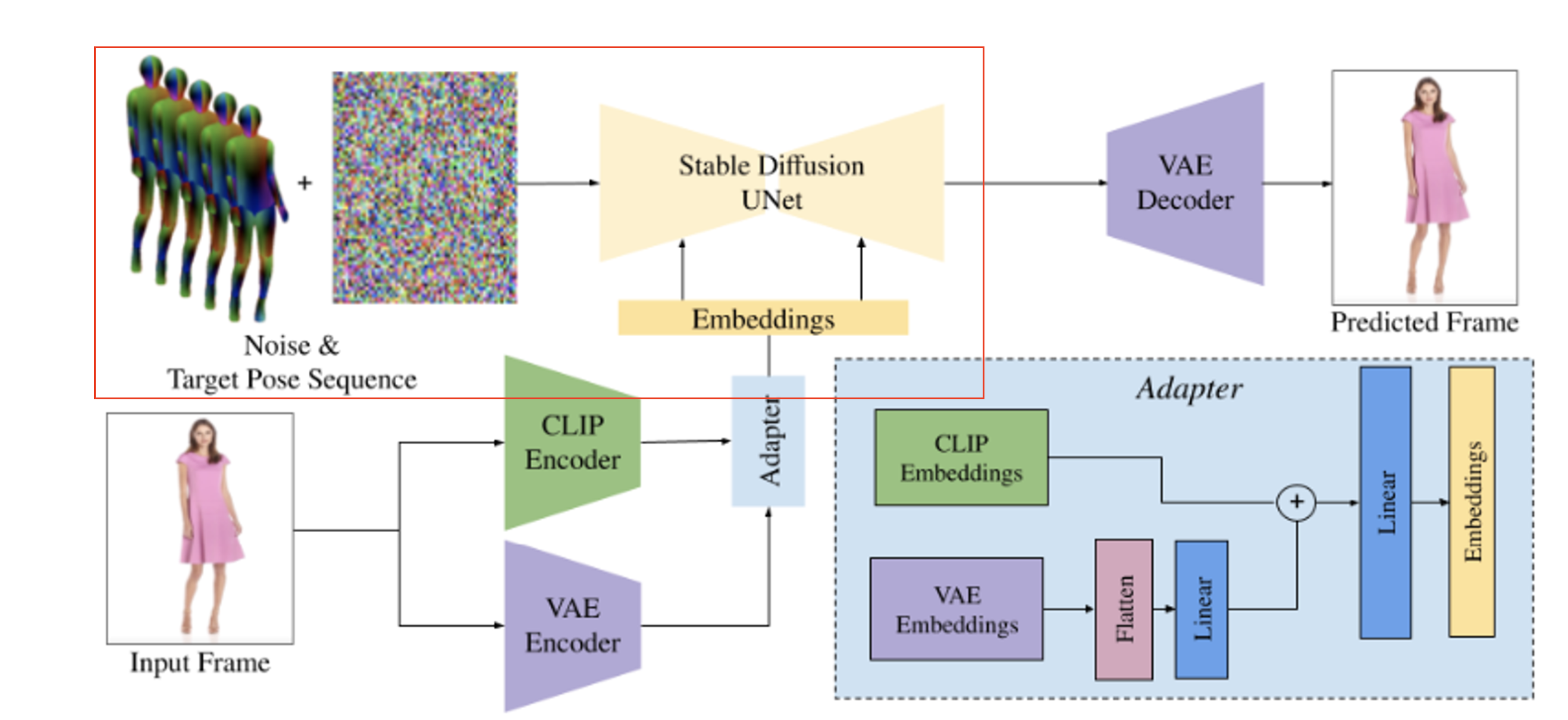
Fig. 651 Modified UNet#
이미지 컨디셔닝과 달리 포즈 컨디셔닝은 이미지와 정렬 된다.
Noisy latent \(\tilde{z}_i\)를 타겟 포즈 표현 \(c_p\)와 concat한다.
실제 비디오에서 추정된 포즈의 노이즈를 고려하고 생성된 프레임에서의 시간적 일관성을 극대화하기 위해, \(c_p\)를 다섯 개의 연속된 포즈 프레임으로 구성하였다. 즉, \(c_p = \{p_{i-2}, p_{i-1}, pi, p_{i+1}, p_{i+2}\}\) → 개별 포즈로 네트워크를 학습하는 것보다 연속 포즈로 학습하면 전반적인 움직임의 부드러움과 시간적 일관성이 증가한다.
구조적으로 0으로 초기화된 10개의 추가 입력 채널을 받아들이도록 UNet 입력 레이어를 수정하고 noisy latent에 해당하는 원래 채널은 사전 학습된 가중치에서 수정되지 않는다.
4.2.3 Finetuning#
스테이블 디퓨전 모델의 대부분의 레이어 weight는 미리 학습된 text-to-image 스테이블 디퓨전 체크포인트로 초기화된다.
이 때, CLIP 이미지 인코더는 별도의 미리 학습된 체크포인트에서 로드된다.
새로운 레이어는 초기에 새로운 컨디셔닝 신호가 네트워크 출력에 기여하지 않도록 초기화 된다.
초기화 후 DreamPose는 아래의 두 단계로 파인튜닝된다.
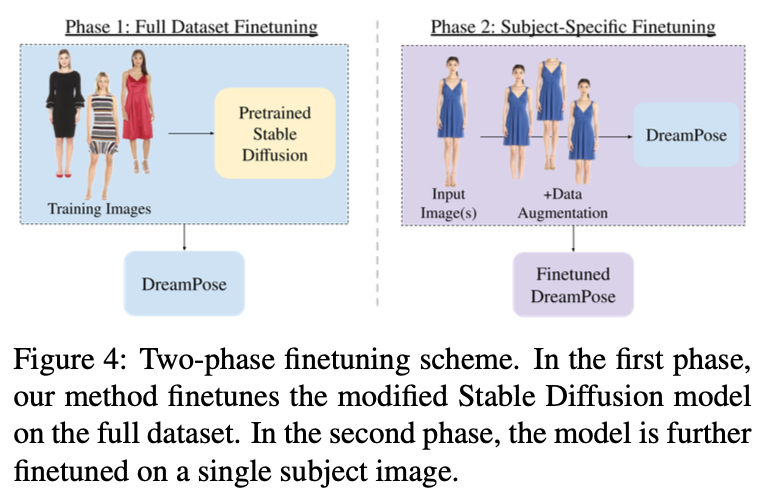
Fig. 652 Two-phase Finetuning#
Full Dataset Finetuning
전체 훈련 데이터셋에 대한 UNet과 어댑터 모듈을 파인 튜닝하여 입력 이미지 및 포즈와 일치하는 프레임을 합성한다.
Subset-Specific Finetuning
하나 이상의 피사체별 입력 이미지에 대해 UNet과 어댑터 모듈을 파인튜닝한 다음 VAE 디코더를 통해 기본 모델을 개선하여 추론에 사용되는 피사체별 맞춤형 모델을 생성한다.
다른 이미지 조건부 디퓨전 방법과 마찬가지로, 입력 이미지의 사람과 의상의 identity를 보존하고 프레임 간에 일관성을 유지하려면 샘플별 파인튜닝이 필수적이었다.
그러나 단순히 단일 프레임과 포즈 쌍에 대해 훈련하면 텍스처 고착(texture-sticking)과 같은 아티팩트가 출력 비디오에 발생한다.
이를 방지하기 위해 각 단계에서 랜덤 크롭을 추가하는 등의 방법으로 이미지-포즈쌍을 증강한다.
VAE 디코더를 파인튜닝하는 것이 더 선명하고 사실적인 디테일을 복구하는 데 중요하다.
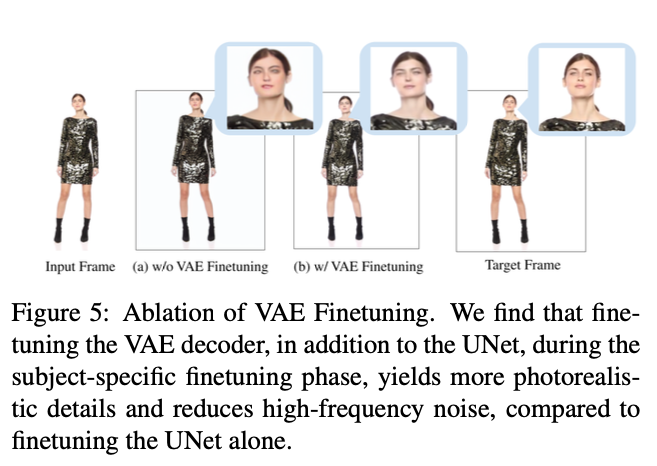
Fig. 653 VAE 파인튜닝의 중요성#
4.4. Pose and Image Classifier-Free Guidance#
추론시 단일 입력 이미지와 피사체별 모델(subject-specific model)을 사용하는 일련의 포즈에서 프레임별로 동영상을 생성한다.
이중(dual) classifier-free guidance를 사용하여 추론 시에 이미지 컨디셔닝 \(c_I\)와 포즈 컨디셔닝 \(c_p\)의 강도를 조절한다.
이중 classfier-free guidance는 식 (3)에서 다음과 같이 수정된다.
\[\begin{split} \begin{align*} {\epsilon_{\theta}(z_{t},c_{I},c_{p})} & {= \epsilon_{\theta}(z_{t},\emptyset,\emptyset)} \\ {} & {+\, s_{I}(\epsilon_{\theta}(z_{t},c_{I},\mathcal{\emptyset})-\epsilon_{\theta}(z_{t},\emptyset,\emptyset))} \\ {} & {+\, s_{p}(\epsilon_{\theta}(z_{t},\mathcal{c}_{I},\mathcal{c}_p)-\epsilon_{\theta}(z_{t},\mathcal{c}_{I},\emptyset))} \end{align*} \end{split}\]\(s_I\), \(s_p\): 가이던스 웨이트
\(c_I\): 이미지 컨디셔닝
\(c_p\): 포즈 컨디셔닝
→ 이미지 컨디셔닝이 있는 경우와 없는 경우의 노이즈 벡터 차이를 계산하고, 포즈 컨디셔닝이 있는 경우와 없는 경우의 노이즈 벡터 차이를 계산해서 이를 가이던스 웨이트를 통해 강도를 조정해서 반영
\(s_I\)가 크면 입력 이미지에 높은 외관 충실도를 보장하고, \(s_p\)가 크면 입력 포즈에 대한 정렬을 보장한다.
이중 classifier-free guidance는 포즈 및 이미지 가이드를 강화하는 것 에외도, 피사체별 모델 파인튜닝 후 하나의 입력 포즈에 대한 오버피팅을 방지한다.
5. Experiments#
5.1. Implementation Details#
입력 이미지 resolution: 512x512
GPU: NVIDIA A100 2개
첫 번째 훈련 단계
전체 훈련 데이터셋 사용
5 epoch
5e-6 learning rate
배치사이즈: 16 (4 gradient accumulation step)
Dropout: 포즈 입력 5%, 이미지 입력 5%
두 번째 훈련 단계
특정 샘플 프레임 사용
500 step
1e-5 learning rate
Dropout 적용 X
VAE 디코더 파인튜닝
1500 step
5e-5 learning rate
추론 시에는 PNDM 샘플러 사용 (100step)
5.2. Dataset#
UBC Fashion 데이터셋 사용
Split
Train: 339개의 영상
Test: 100개의 영상
각 비디오의 프레임 속도는 초당 30프레임이며 길이는 약 12초
학습 중에는 학습 비디오로부터 랜덤으로 프레임 쌍을 샘플링 하였다.
DensePose를 이용해서 포즈를 계산하였다.
6. Results#
6.1. Comparisons#
공개적으로 사용 가능한 두 가지 최신 비디오 합성 방법인 MRAA(Motion Representations for Articulated Animation)과 Thin-Plate Spline Mothion Model(TPSMM)과 수치적 및 정성적인 비교를 하였다.
제공된 훈련 스크립트와 권장 에폭 수를 사용하여 두 가지 모델을 UBC 패션 데이터셋을 이용해서 스크래치부터 학습하였다.
평가를 위해서는 AVD 모드에서 제공된 테스트 스크립트를 사용하였다.
PIDM과도 정성적인 비교를 하였다. PIDM의 경우 훈련 스크립트를 사용할 수 없어서 DeepFashion 데이터셋에 대해 학습된 체크포인트를 통해 비교하였다.
100개의 디노이징 스텝을 사용하여 PIDM과 DreamPose를 실행하였다.
6.1.1 Quantitative Analysis#
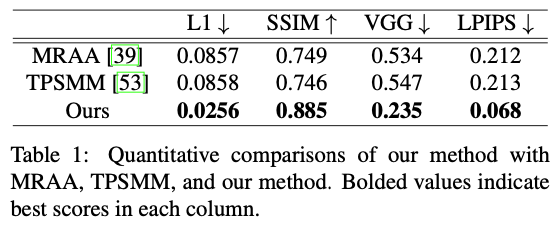
Fig. 654 정량적 성능 비교#
256 픽셀 해상도의 100개의 고유한 패션 동영상으로 구성된 UBC 패션 테스트 셋에 대해 모든 모델을 테스트 하였다.
각 동영상에 대해 입력 프레임에서 최소 50프레임 이상 떨어져 있는 50개의 프레임을 추출하여 테스트하였다.
MRAA와 TPSMM은 모두 driving video에서 추출된 feautre에 의존하는 반면, DreamPose는 UV-포즈 시퀀스에만 의존한다는 점에 유의하라.
그럼에도 불구하고 DreamPose 모델은 네 가지 정량적 지표 모두에서 두 가지 방법보다 정량적으로 우수한 성능을 보였다.
6.2.2 Qualitative Analysis#

Fig. 655 정성적 성능 비교#
MRAA와 TPSMM은 새로운 포즈를 취할 때 인물의 identity, 옷감 주름, 미세한 패턴이 손실되는 반면 DreamPose는 디테일을 정확하게 유지한다.
포즈를 크게 변경하는 동안 MRAA는 팔 다리가 분리 될 수 있다.
PIDM과의 비교

Fig. 656 PIDM과의 비교#
DreamPose는 얼굴의 identity와 의상 패턴 모두 더 충실도 높은 결과를 생성한다.
PIDM은 사실적인 얼굴을 합성하지만, 원본 인물의 identity와 일치하지 않고, identity와 옷차림이 프레임마다 달랐다. → PIDM이 비디오 합성에서는 잘 동작하지 않는다.
6.2. Ablation Studies#
아래 네 가지 변형에 대해 성능을 비교한다.
\(\text{Ours}_{\text{CLIP}}\): 듀얼 CLIP-VAE 인코더 대신에 사전 학습된 CLIP 이미지 인코더를 사용 → CLIP-VAE 인코더 효과 테스트
\(\text{Ours}_{\text{NO-VAE-FT}}\): VAE 디코더를 파인튜닝하지 않은 버전 → 디코더 파인튜닝 효과 테스트
\(\text{Ours}_{\text{1-pose}}\): 5개의 연결된 연속 포즈 대신 하나의 대상 포즈만 노이즈에 연결한 버전 → 연결된 5개의 프레임 효과 테스트
\(\text{Ours}_{\text{Full}}\): 논문에서 제안한 모든 방법이 다 적용된 DreamPose
Quantitative Comparison
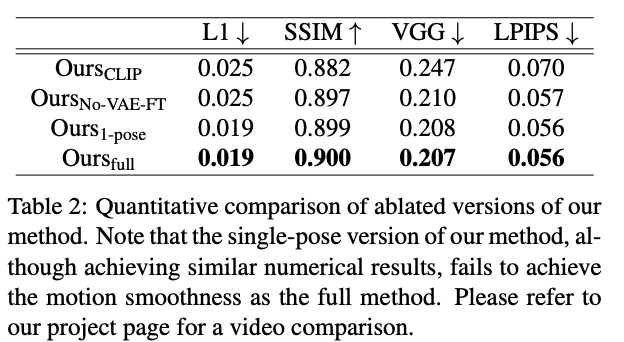
Fig. 657 Ablation Studies - 정량적 비교#
Qualitative Comparison

Fig. 658 Ablation Studies - 정성적 비교#
기존의 스테이블 디퓨전에서는 인물의 identity에 대한 디테일을 보존할 수 없었다.
텍스트 인코더를 CLIP 인코더로 교체한 결과 대부분의 이미지 디테일은 캡처할 수 있지만, 여전히 외형에 대한 정보 손실이 발생한다.
VAE 디코더를 파인튜닝하면 디테일의 선명도가 크게 향상되고 입력 포즈에 대한 오버피팅이 발생하지 않는다.
한 가지 포즈만 입력하면 팔과 머리카락 주변에서의 피사체의 형태가 눈에 띄게 깜박이는 현상이 나타났다.
6.3. Multiple Input Images#
DreamPose는 피사체에 대한 입력 이미지를 여러 장 넣어서 파인튜닝할 수 있다.
피사체의 입력 이미지를 추가하면 품질과 시점의 일관성이 향상된다.

Fig. 659 Multiple Input Images 결과#
7. Limitations & Future Work#
실패 사례
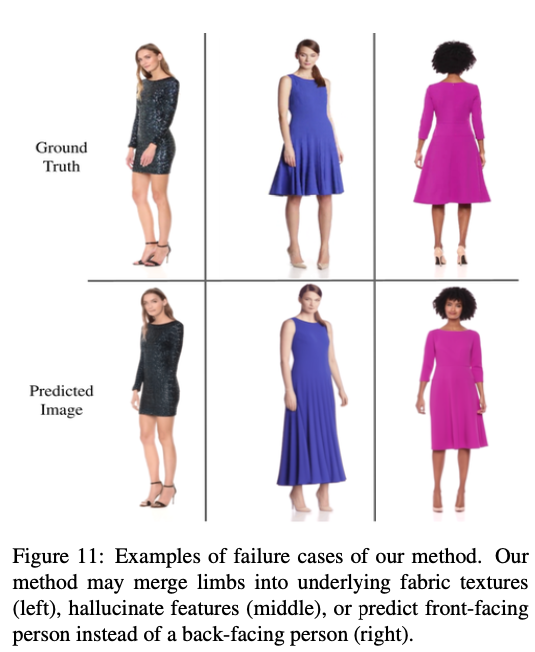
Fig. 660 실패 사례 예시#
드문 경우지만 팔다리가 옷 속으로 사라지고(왼쪽), hallucinate feature가 보이고(중간)와 대상 포즈가 뒤를 향할 때 방향이 잘못 정렬 되는 경우(오른쪽)가 관찰된다.
또한 단순한 패턴의 옷에서 사실적인 결과를 생성하지만 일부 결과는 크고 복잡한 패턴에서 약간의 깜박임 동작을 보인다.
다른 디퓨전 모델과 마찬가지로 파인튜닝 및 추론 시간이 GAN 또는 VAE에 비해 느리다.
특정 피사체에 대한 모델 파인튜닝은 프레임당 18초의 렌더링 시간 외의 UNet의 경우 약 10분, VAE 디코더의 경우 약 20분이 소요된다.
8. Conclusion#
스틸 패션 이미지 애니메이션을 위한 새로운 디퓨전 기반 방법인 DreamPose를 제안하였다.
한 장의 이미지와 포즈 시퀀스가 주어졌을 때, 섬유, 패턴, 사람의 identity를 애니메이션 하는 사실적인 사실적인 패션 동영상을 생성하는 방법을 증명하였다.