Information
Title: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (NeurIPS 2022)
Reference
Author: Donggeun Sean Ko
Last updated on Sep. 13, 2023
Imagen#
Introduction#
Multi-modal learning, 특히 text-to-image generation 에서 contrastive learning이 최근에 많은 주목을 받고 있음.
Contrastive learning 과 더불어 large language model (LLM) 들과 diffusion model 들을 사용하여 독창적인 image 생성도 가능함
텍스트 전용 말뭉치 (text corpus)로 학습된 LLM들의 text embedding들은 text-to-image 합성에 매우 효과적이라고 함.
Classifier-free guidance 사용하여, 더 높은 충실도 (fidelity)의 이미지를 생성하는 새로운 샘플링 기술을 사용함.
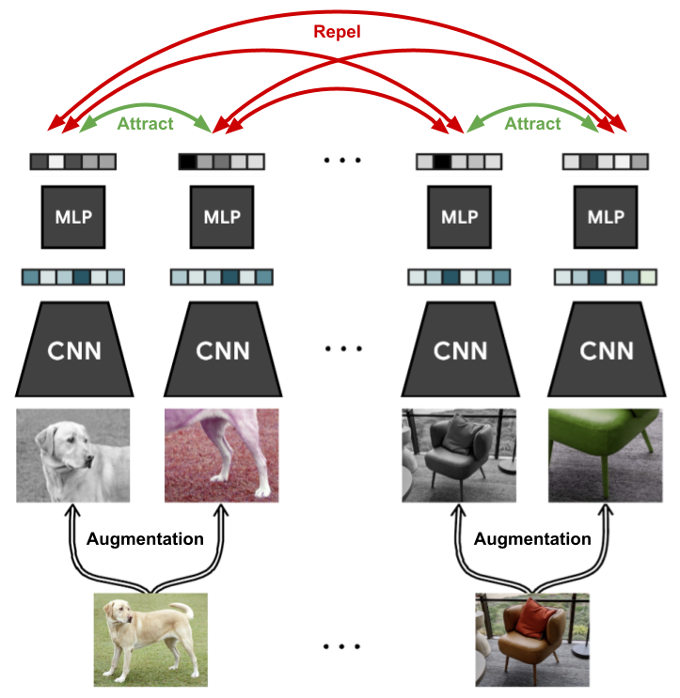
Fig. 211 Concept of Contrastive Learning#
Contributions#
Pretrained Frozen text encoder (T5-XXL) 이 text-to-image generation task 에 매우 좋은 성능을 보여줌.
Pretrained Text Encoder 사이즈를 fine-tuning하는 것이 diffusion model size fine tuning 하는 것보다 더 중요하다는 것을 실험적으로 증명함
Dynamic Thresholding 이라는 새로운 diffusion sampling technique (thresholding diffusion sampler) 을 제시하여 high guidance weight을 leverage 할 수 있게 만들어 더욱 “현실적인” 이미지 생성을 할 수 있음
Efficient U-Net이라는 기존 Palette 나 DDIM에서 사용하는 U-Net 구조보다 computational, memory efficient 한 U-Net 구조를 제시함
COCO FID 점수 7.27 SOTA 점수를 달성함
DrawBench라는 새로운 text-to-image generation evaluation용 benchmark dataset을 제시함
Methodology#
Pretrained T5-XXL + Cascaded Diffusion Model#
Pretrained Text Encoder 중 T5-XXL (구글 모델) 사용
학습 시 pretrained text encoder을 Freeze 해놓음
Text-to-Image Diffusion Model (Improved DDPM 아키텍쳐) 사용해 64x64 image 생성
2가지 SR model (Efficient U-Net)을 사용해서 64 → 256 → 1024 로 upsampling

Fig. 212 Imagen overall pipeline#
Classifier-Free Guidance#
Classifier-free guidance 이란 auxiliary classifier의 효과 없이 classifier guidance 효과를 얻는 방법
아래의 그림처럼 guidance가 없을 시 image generation이 일정하지 않음. 즉, label/class 의 영향을 못받아서, 생성이 일정하지 않음.
guidance를 줄 시, 생성된 이미지의 class나 object이 일정하고 무엇을 생성하는것인지 좀 더 자세하게 알 수 있음.

Fig. 213 Comparison between when guidance is not used (left) vs when guidance is used with parameter, w=3 (right)#
Large guidance weight sampler#
Guide의 가중치 w 를 높이면 train-test 불일치가 생긴다.
이로 인해, 높은 가중치의 이미지는 훈련 데이터 범위 안에 없어 [-1,1], classifier-free guidance가 평균과 분산을 이동시켜 이미지가 아예 “빗나가” 이상한 이미지를 생성하게 된다
Static Thresholding#
x-prediction 을 [-1,1]로 clipping 한다. 여전히 saturation 이 되고 fidelity가 덜한 이미지가 생성 됌
문제를 해결하고자 dynamic thresholding 을 제시함
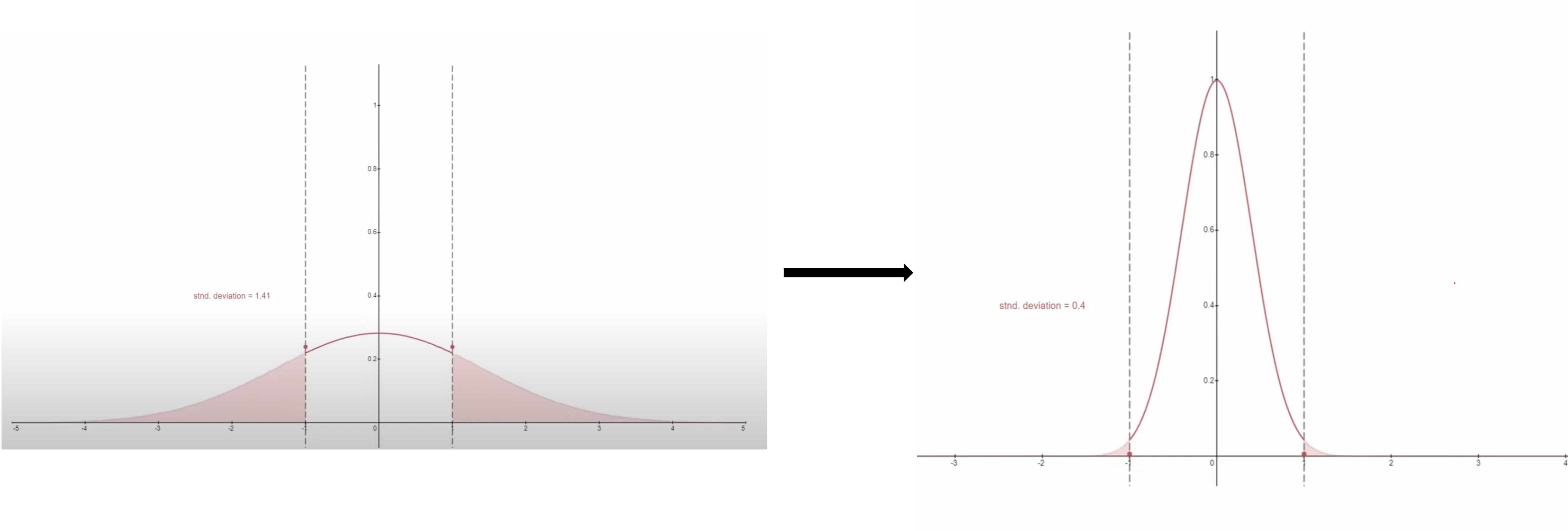
Fig. 214 Graphical visualization of static thresholding#
Dynamic Thresholding#
특정 백분위수 절대 픽셀 값을 s 라고 지정하고 s > 1 이면, 임계값을 [-s,s]로 지정한 다음 s로 나눈다.
예시: 90% 지점의 픽셀 값이 3 이면 [-3,3]으로 clipping 한 후 3으로 나눠서 [-1,1] 로 normalize 함.
Thresholding 의 차이는 아래 결과 비교 이미지로 확인 할 수 있다.
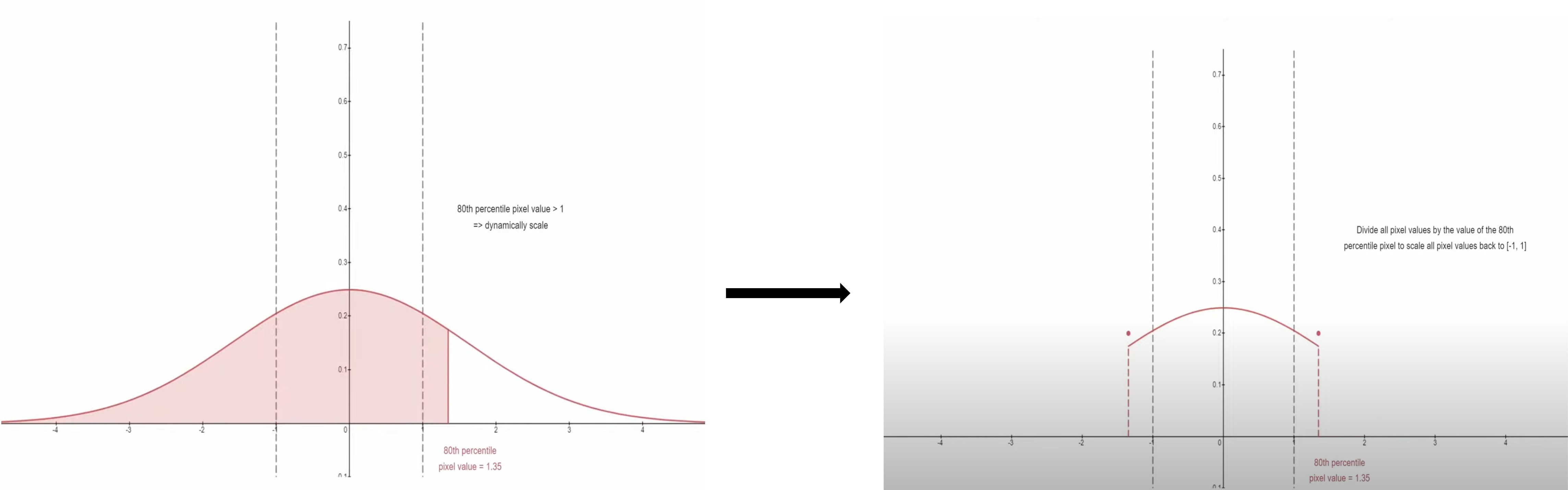
Fig. 215 Graphical visualization of dynamic thresholding#

Fig. 216 Comparison among no thresholding, static thresholding and dynamic thresholding, respectively#
Super Resolution Models#
Efficient U-Net이라는 새로운 모델을 만들어, 기존 U-Net에서 여러가지 modification을 하였다고 주장 (그렇지만 EffU-Net은 의료쪽으로 이름이 이미 있는걸로 아는데…)
Removed self-attention layer
Keep the text cross-attention layer
Skip connection scaling을 1/(√2)로 하여 convergence 를 더 빠르게 함
Lower resolution block에서 residual blocks를 더 추가함
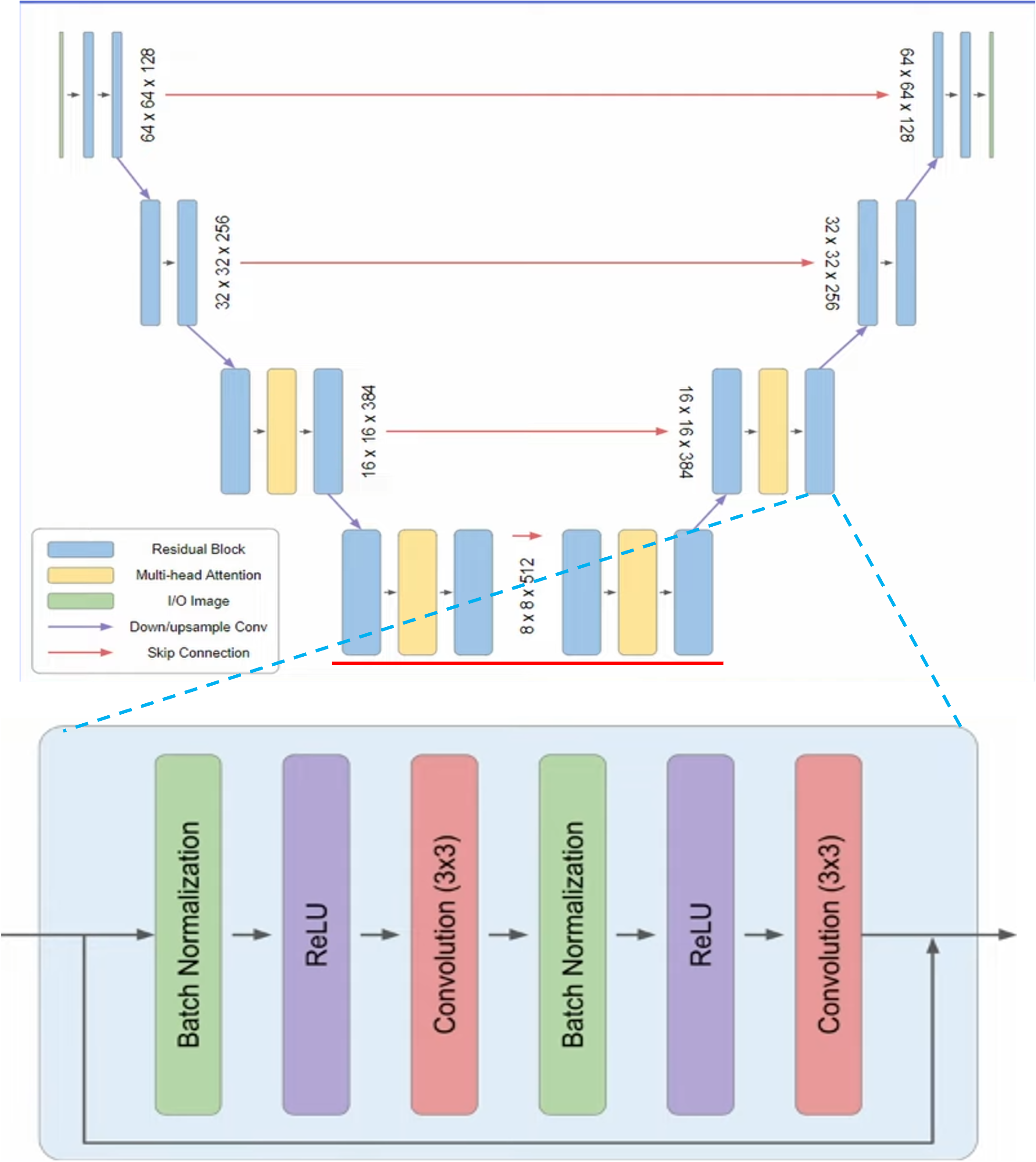
Fig. 217 Architecture of Super Resolution Diffusion Model used in Imagen#
DrawBench#
Imagen 저자들이 제시한 새로운 벤치마크 데이터셋. 본 데이터셋은 text prompt 와 category label 로 이루어졌다
깃허브에서 다운 받을 수 있으며, 예시는 아래 그림과 갗다 11 categories, 200 text prompts Human evaluation 으로 진행 (25명의 평가자) Model A에서 생성한 이미지 set vs Model B에서 생성한 이미지 set
평가자는 2가지 질문을 주며 2가지 기준점으로 평가함 Q1. Which set of images is of higher quality? Q2. Which set of images better represents the text caption: {text caption}?
기준점
Image Fidelity
Image-text alignment
평가자는 3가지 답변 중 하나를 선택해야함
I prefer set A
I am Indifferent
I prefer set B
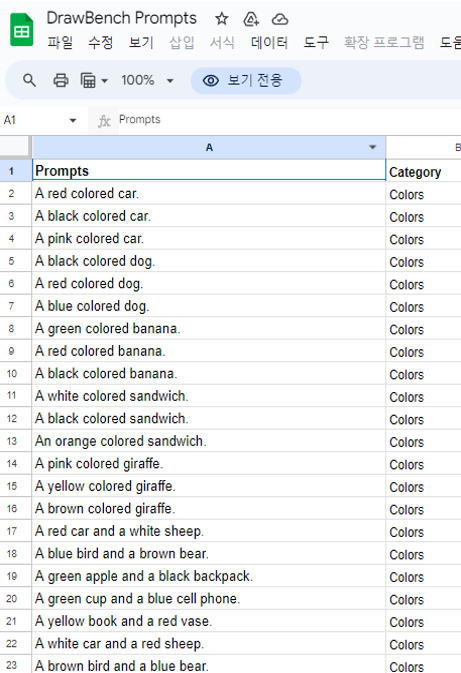
Fig. 218 Screenshot of DrawBench dataset#
Results#
Figure 2 에서는 DrawBench에서 나온 결과를 체리피킹 없이 보여준다.
아마 저자들은 체리피킹 없이도 좋은 결과를 보여주고, 다양한 카테고리에서도 훌륭한 이미지를 생성 할 수 있다는 주장인 것 같다.

Fig. 219 Result of Imagen in DrawBench dataset#
Zero-shot 으로 한 FID값이 MS-COCO로 학습한 모델들 FID 보다 높음.
Table 2 에서는 Imagen이 no people (사람이 없는 사진) 에는 photorealism 점수가 올라감 → Imagen 은 photorealistic people을 생성하기에 한계가 있음.
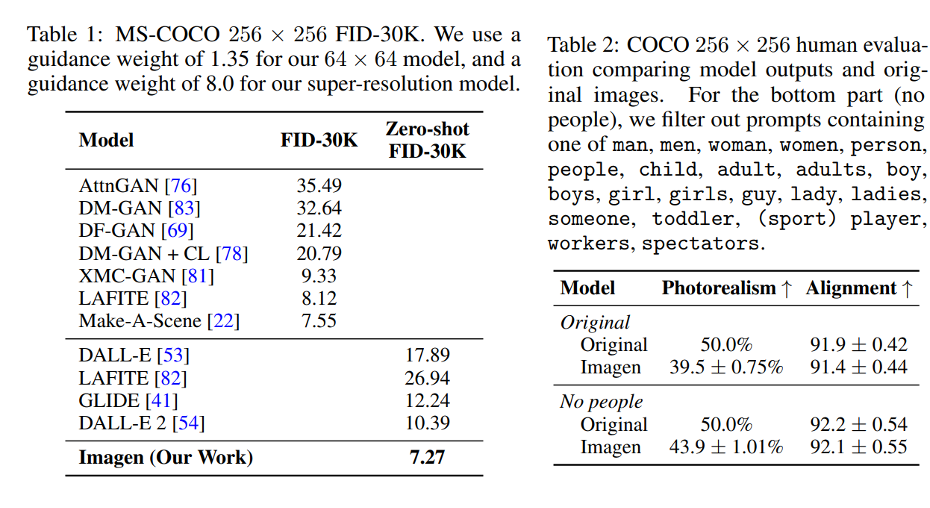
Fig. 220 Result Table of Imagen#
Qualitative Result Table of Imagen from Human Evaluators#
Human raters (사람 평가자) 들은 T5-XXL로 text encoding 한 text-to-image generation 모델을 CLIP-based 보다 더 선호함
기본적으로 Imagen 은 다른 text-to-image generation 모델에서 (SOTA 모델인 DALL-E 2) 보다도 human raters 에서 DrawBench 데이터셋에서 좋은 평가를 받음
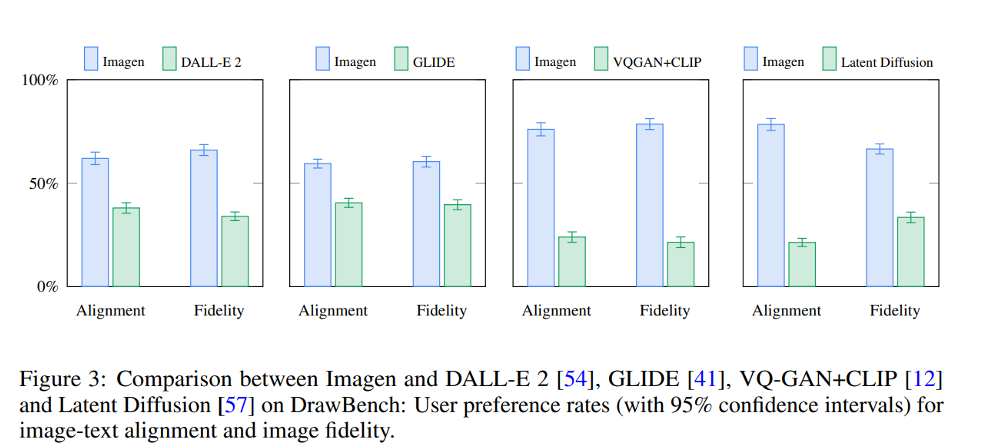
Fig. 221 Qualitative Result Table of Imagen from Human evaulators#
Ablation Study#
Scaling text encoder size 가 U-Net size scaling 보다 더 중요함
(a)의 text encoder 사이즈의 변화가 FID 및 CLIP score 점수에 더욱 많은 영향을 끼침
Dynamic thresholding 이 performance boost에 더욱 영향을 끼침
Dynamic thresholding을 이용하면 성능을 더욱 끌어 올릴 수 있음
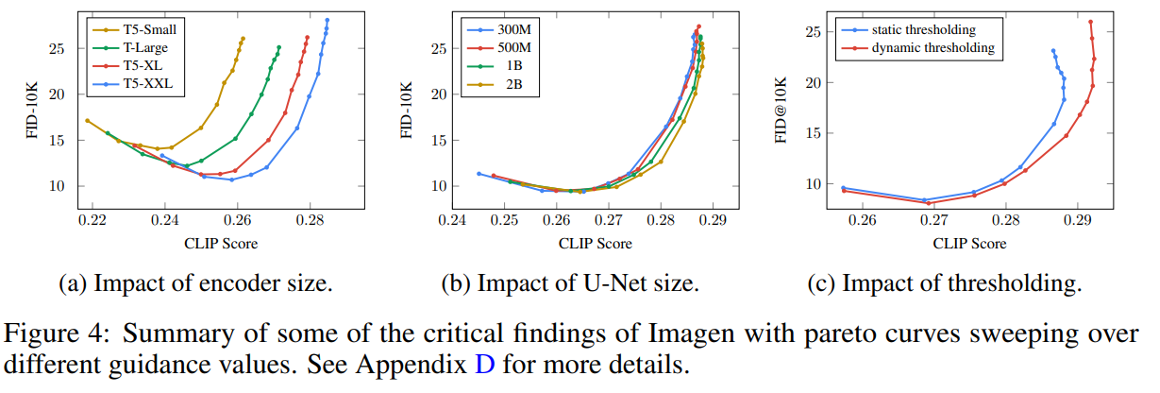
Fig. 222 Qualitative Result Table of Imagen from Human evaulators#
Conclusion#
Frozen large pretrained language model shows better performance over text-image paired multimodal encoders such as CLIP in text-to-image generation task
Efficient U-Net significantly improves performance time
Dynamic thresholding allows usage of much higher guidance weights with better fidelity of generated images