Information
Title: Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
Reference
Author: Jun-Hyoung Lee
Last updated on Nov. 30. 2023
VideoLDM#

Fig. 603 Video LDM samples#
Abstract#
Latent Diffusion Models (LDMs)는 computing resource 를 줄이기 위해 낮은 차원의 latent space 로 압축하여 high quality 의 image synthesis 를 가능하게 했다.
비디오 생성 모델링의 퀄리티 부족하며,
이유가 학습에 필요한 computing cost 가 많이 발생, 데이터 셋 부족하다.
제안
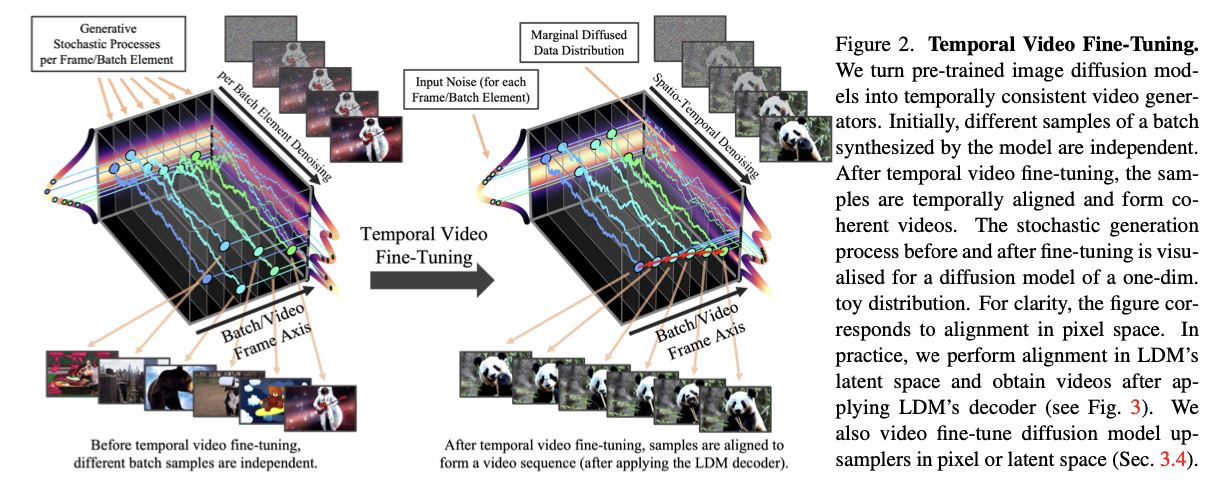
Fig. 604 Temproal Video finetuning#
기존에는 가우시안 노이즈의 랜덤한 샘플들 끼리의 denoising 결과 다른 이미지를 생성했다.
Temporal Video finetuning 을 거치게 되면 비디오 시퀀스의 형태(시간축에 정렬된 이미지)로 생성할 수 있다.
VideoLDM 은 기존 LDM 방법에 고해상도의 비디오 생성을 적용했다.
대규모 이미지 데이터 셋을 활용해 LDM 을 pre-train 했고, (only image)
pre-trained image LDMs 를 활용 가능하다.
temporal modeling 만 학습한다.(기존 이미지 LDM은 freeze)
1280x2048 해상도 까지 가능하다.
그 후, 이미지 generator 를 비디오 generator 로 전환한다.
latent space diffusion model 에 temporal(시간적) 차원을 적용한다.
이미지 시퀀스(비디오)를 인코딩해 파인 튜닝 진행한다.
diffusion model upsampler 를 시간적으로 정렬하여 일관적인 비디오 super resolution model 로 변환한다.
Applied task
자율 주행의 시뮬레이션 엔진 (512x1024 해상도로 실제로 평가 진행해 sota 달성)
creative content creation (using text-to-video)
3. Latent Video Diffusion Models#
비디오 데이터 셋: \(x ∈ R^{T×3×\tilde H×\tilde W}\) 로 표현
\(T\): frame 수, \(\tilde H, \tilde W\): 높이, 너비
3.1. Turning Latent Image into Video Generators#
잘 학습된 image LDM 을 활용하는 것이 주요한 key point.
문제점
image LDM 은 개별의 프레임에 대한 high quality 이미지를 생성할 수 있고, → 시간적인 정보는 포함하고 있지 않다.
따라서 이를 연속적인 프레임으로 렌더링해 사용할 수 없다.
\(l_\phi ^i\) 로 표현하는 temporal neural network 를 추가했다.
이는 이미지 LDM 의 공간적인 정보에 연관되며, 시간적으로 일관된 방식으로 개별 프레임을 정렬할 수 있도록 한다.
비디오를 인식할 수 있는 backbone 을 정의한다.
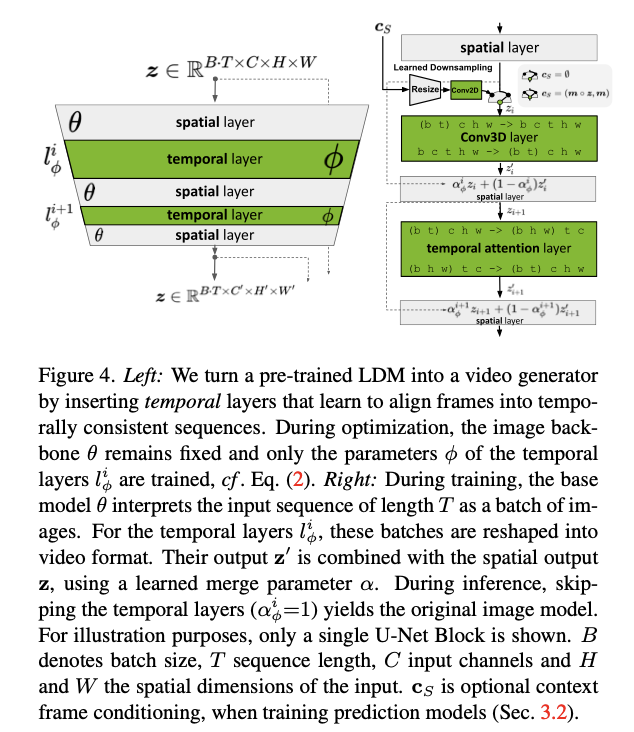
Fig. 605 Video-Aware Temporal Backbone#
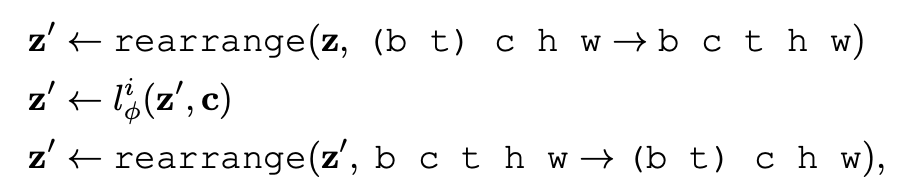
Fig. 606 Einops notation#
einops 로 구현했으며, spatial layer 에서는 비디오(배치x시간) 정보가 함께 인코딩이 되며,
temporal layer 에서는 이를 rearrange 를 통해 배치, 시간 정보를 나눠 시간 차원에서 인코딩이 진행된다.
(option) 이때 text prompt 가 conditioning 이 될 수 있다.
(i) temporal attention (ii) 3D conv 로 구성된다.
Sinusoidal embedding 을 사용해 시간에 대한 위치 인코딩 활용했다.
temporal layer 을 거친 후, spatial layer 의 output 과 가중합을 통해 정보가 결합된다.
3.1.1 Temporal Autoencoder Finetuning#
Image LDM 을 사용하면 시퀀스로 생성할 때 flickering이 발생하는 문제가 있다.
이를 해결하기 위해, autoencoder 의 decoder 에서 temporal 한 layer 를 추가한다.
이는 3D conv 로 구축된 patch-wise temporal discriminator 도 추가해 비디오 데이터를 fine tuning 한다.

Fig. 607 Temporal Autoencoder Finetuning#
인코딩된 비디오 프레임의 latent space 내에서 image DM 을 사용할 수 있도록 인코더는 학습이 되지 않는다.
3.2. Prediction Models for Long-Term Generation#
그럼에도 불구하고, 긴 동영상은 생성하지 못하는 한계가 있다.
따라서 전체 \(T\) 프레임에서 마스킹된 \(S\) 프레임으로 구성해 모델이 예측하게끔 학습을 한다.
이러한 프레임들은 LDM 의 인코더를 통해 채널 차원에 concat 되며, temporal layer 에 입력된다.
inference 에서는 반복적인 샘플링 과정을 통해 긴 영상을 생성할 수 있게 했다.
최신 prediction 을 재 사용해 새로운 context 를 생성했다.
classifier-free guidance 를 도입해 마스킹된 프레임 수를 0, 1, 2 개를 사용해 학습.
3.3. Temporal Interpolation for High Frame Rates#
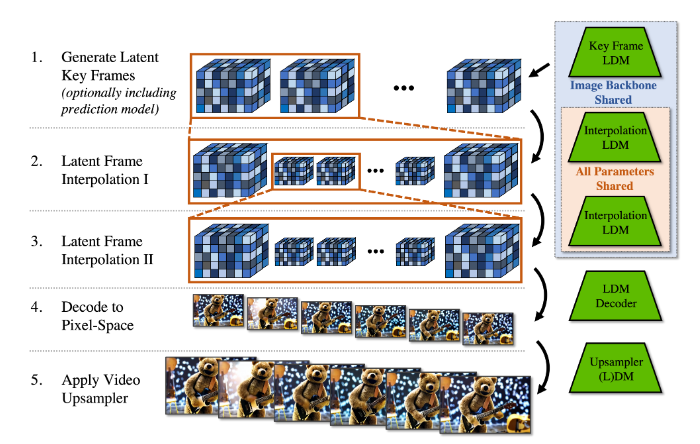
Fig. 608 Temporal Interpolation#
High resolution video 란 해상도 뿐만 아니라 높은 frame rate 를 가지고 있어야 한다.
이를 위해 두 가지 과정으로 진행한다.
semantic 한 큰 변화가 있는 키 프레임을 생성한다.
메모리 제약으로 인해 low frame rate 로 생성할 수 있다.
키 프레임을 활용한 interpolate 진행한다.
interpolate 할 프레임을 masking 을 씌운다.
두 개의 키 프레임에 대해 세 개의 프레임을 예측하는 것으로 T → 4T interpolation model 을 학습해 사용했다.
높은 frame rate 를 위해 16T 까지 interpolation 모델 구축.
3.4. Temporal Fine-tuning of SR Models#
megapixel 의 해상도까지 생성하는 것이 목표이다.
cascaded DMs 에 영감받아 4배 해상도를 키웠다.
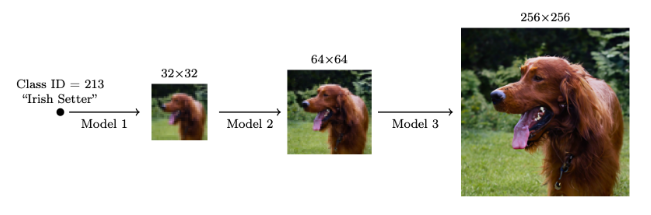
Fig. 609 Cascaded DM#
noise augmentation(with noise level conditioning) 으로 super resolution 모델 학습했다.
또한 consistency 한 SR 모델을 구축하기 위해 spatial / temporal layer를 추가했다.
저해상도 시퀀스 길이 \(T\) 를 concat 하여 conditioning
locally 하게 patch 단위로 연산하고, 후에 convolution 을 진행한다.
computing resource
VideoLDM 에서의 main LDM 을 효율적으로 연산을 하기 위해 latent space 에서 모든 비디오 모델링이 수행된다.
그로 인해, 높은 배치 사이즈 + 긴 영상 생성 가능하다.
upsampler 는 패치 단위로 진행하기에 computing resource 를 줄일 수 있다.
4. Experiments#
Dataset
RDS(real driving scene): 683,060 개, 8초(30 fps), 512×1024, day/night, “crowdedness”
WebVid-10M: 10.7M video-caption pairs, 52K video hours, resized 320×512
Evaluation metric
FVD + human evaluation
CLIP similarity (CLIP- SIM) + IS
4.1. High-Resolution Driving Video Synthesis#

Fig. 610 Real-World Driving Scenes with Video LDM#
4.2. Text-to-Video with Stable Diffusion#
WebVid-10M 데이터셋(resized 320×512)으로 Stable Diffusion 의 spatial layer 에 대해 학습했고,
text-conditioning 을 적용한 temporal layer 를 추가해 학습 진행했다.
그 후 upscaler 를 학습해 4배 upscale 해 1280×2048 해상도로 비디오 생성 가능해졌다.
113 frames: 24fps 4.7초 or 30fps 3.8초

Fig. 611 Text-to-Video with Stable Diffusion#
다양성이 적은 Real video 로 제한적인 데이터로 학습했지만, 기존 Stable Diffusion 의 생성 능력을 가져와 artistic 한 생성이 가능하다.
performance
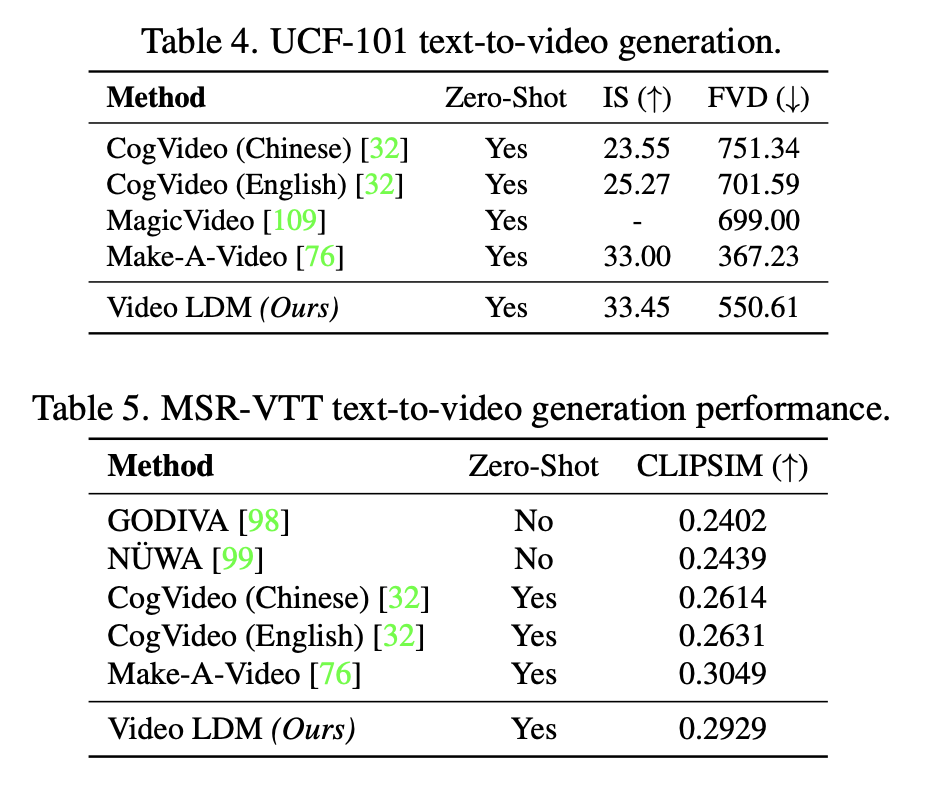
Fig. 612 Performance Table#
Make-A-Video 의 경우 VideoLDM 보다 더 많은 데이터 셋과 text-to-video를 entirely하게 학습했다.
4.2.1 Personalized Text-to-Video with Dreambooth#

Fig. 613 Text-to-Video with DreamBooth#
위쪽의 VideoLDM 을 활용한 결과가 consistency 한 결과를 가져왔다.