Information
Title: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (ICCV 2017)
Reference
Author: KwangSu Mun
Author: ChangHwan Lee
Last updated on May. 16, 2024
CycleGAN#
Abstract#
Image-to-image translation 은 한 이미지 도메인을 다른 이미지 도메인으로 변환시키는 computer vision 의 한 task 입니다.
Image-to-image translation 은 보통 input과 output이 짝이 지어진 상태에서 학습하지만 짝이 지어진 학습 데이터를 얻는 것이 어렵습니다. 따라서 CycleGAN 논문에서는 짝지어진 예시 없이 \(X\) 라는 domain 으로부터 얻은 이미지를 target domain \(Y\) 로 바꾸는 방법을 제안합니다. 이 연구는 Adversarial loss 를 활용해, \(G(x)\) 로부터 생성된 이미지 데이터의 분포와 \(Y\) 로부터의 이미지 데이터의 분포가 구분이 불가능하도록 함수 \(G: X -> Y\) 를 학습시키는 것을 목표로 합니다. 더불어, \(X -> Y\) 로의 mapping 에 제약을 가해서 원하는 이미지를 강제하기 위해 \(F: Y -> X\) 와 같은 역방향 매핑을 함께 진행합니다. 즉, \(F(G(x))\) 가 \(X\) 와 유사해지도록 강제하는 cycle consistency loss 를 도입했습니다.
결과적으로 collection style transfer, object transfiguration, season transfer, photo enhancement 등의 task 에서 이미지 pair 가 존재하지 않는 상태에서 우수한 결과를 보여줬다고 합니다.
Background#
Image-to-Image Translation#
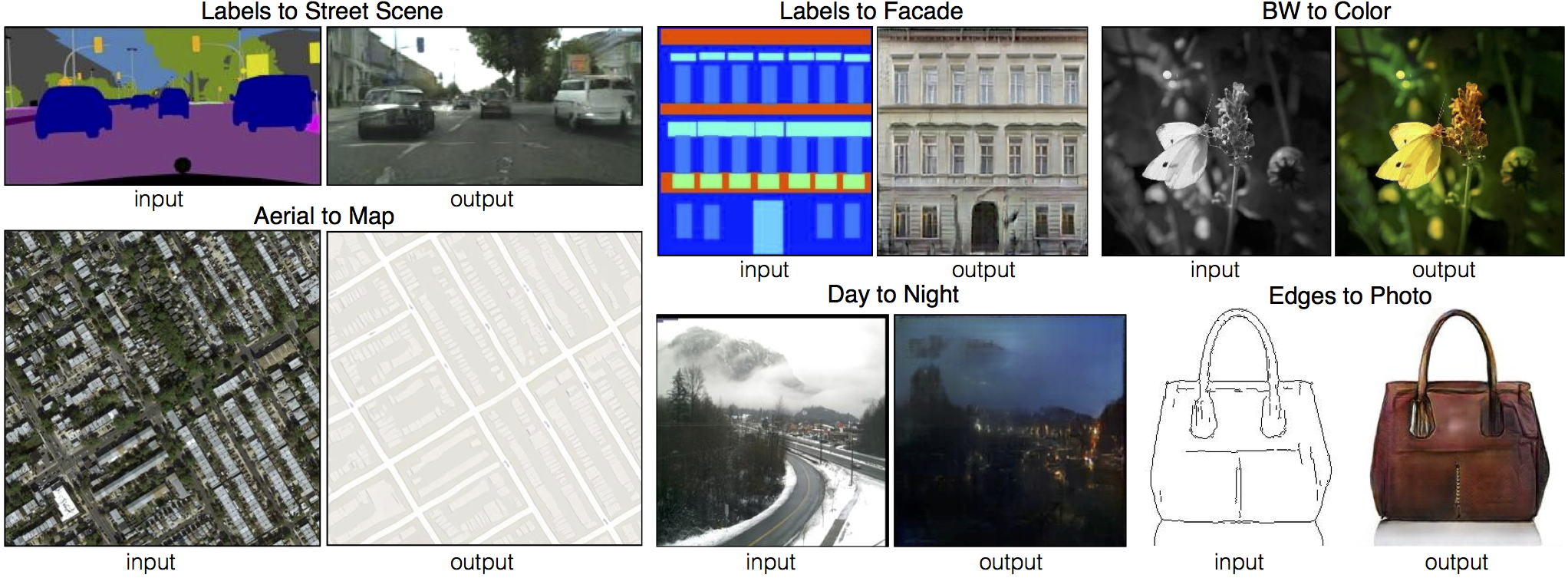
Fig. 45 image-to-image translation#
Image-to-image translation 은 input image 를 다른 스타일, 속성, 구조 등을 가진 output image 로 변환하는 task 입니다. 예를 들어 사진을 그림으로 변환한다거나, 낮에 찍은 사진을 밤에 찍은 것 처럼 변환하는 것을 말합니다. 흔히 translation 은 input 과 output 로 짝이 지어진 데이터를 바탕으로 학습이 이루어져 있었는데요. 짝이 지어진 사진 데이터를 얻는 것은 어렵고 값이 비싼 일이 됩니다.

Fig. 46 paired and unpaired data#
이 논문에서는 input image와 output image가 일대일로 짝지어지지 않은 상태에서 하나의 image 모음의 특성을 캡쳐하고, 이러한 특성을 다른 image 모음으로 변환할 수 있는 방법을 제시합니다. GAN은 domain \(X\) 에 이미지 한 세트, domain \(Y\) 에 이미지 한 세트가 제공되고, model 의 output 과 \(Y\) 가 discriminator 에 의해 구별할 수 없도록 모델 \(G: X -> Y\) 를 학습합니다. 하지만, 이것이 개별 입력 \(x\) 와 출력 \(y\) 가 무조건 유의미하게 쌍을 이룬다는 것을 뜻하지는 않습니다. \(G\) 가 생성할 수 있는 image 에는 무한한 경우의 수가 있기 때문에 종종 mode collapse 현상이 일어나기도 합니다.
Mode Collapse#

Fig. 47 mode collapsing 출처: http://dl-ai.blogspot.com/2017/08/gan-problems.html#
어떤 input image 든 모두 같은 output image 로 매핑하면서 최적화에 실패하는 현상입니다. 이 현상은 generator 입장에서, discriminator 가 이 사진이 진짜 \(Y\)인지 가짜인 \(\hat{Y}\)인지 구별하는 것을 ‘속이기만’ 하면 되기 때문에 우리의 목적과 전혀 상관이 없는 데이터를 generator 가 만들더라도 문제가 생기지 않아서 발생합니다.
이러한 이슈로 인해 추가 objective function 이 필요해졌습니다. 따라서 translation task 는 영어 -> 프랑스어 -> 영어로 번역했을 때 원래 문장에 다시 도달하는 것처럼, \(X --> Y --> X'\) 로 돌아가는 과정에서 \(X\) 와 \(X'\) 이 최대한 같아야 한다는 의미의 cycle consistency 이라는 속성을 이용합니다. 필요한 목적식을 간단하게 정리하면 다음과 같습니다.
정방향, 역방향 adversarial loss: \(X -> Y & Y -> X\)
Cycle consistency loss: \(X \)\approx\( F(G(x))\)
Method#
Overview#
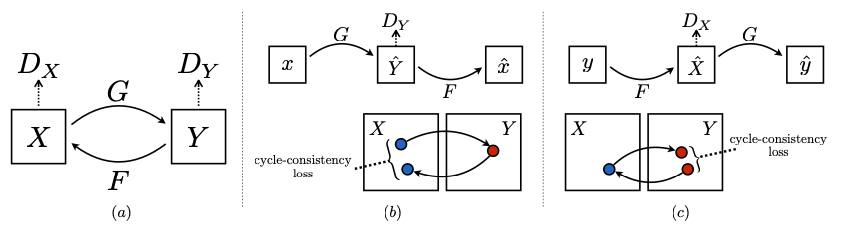
Fig. 48 CycleGAN 도식화 자료#
목표: \(X\), \(Y\) 를 mapping 하는 function 을 학습하는 것
용어 정리
data 분포를 \(x ~ p_{data}(x)\), \(y ~ p_{data}(y)\) 로 표기
\(G : X -> Y\), \(F: Y -> X\) 는 generator
\(D_X\), \(D_Y\) 는 discriminator
\(D_X\) 는 \(X\) 와 \(F(y)\) 그리고 \(D_Y\) 는 \(y\) 와 \(G(x)\) 를 구분하고, 다음과 같이 두 개의 목적식으로 학습합니다.
adversarial loss: 생성된 이미지의 분포를 대상 domain 의 data distribution 과 일치시키기 위한 것.
cycle consistency loss: 학습된 mapping \(G\) 와 \(F\) 가 서로 모순되는 것을 방지하기 위한 것.
Adversarial Loss#
\(G: X -> Y\) 와 \(D_Y\) 에 대한 목적식은 다음과 같습니다.

Fig. 49 \(\mathcal{L}_{GAN}\) Loss function (source: https://arxiv.org/abs/1703.10593)#
이는 GAN 에서 쓰이는 loss function 를 사용하지만, 차이점이 있다면 \(X -> Y\) 로 갈 때와 \(Y -> X\) 로 갈 때 총 두 개의 수식이 나옵니다. 다시 말해, \(F: Y -> X\) 와 \(D_X\) 에 대해서도 \(F\), \(D_X\) 를 넣은 동일한 수식을 사용합니다.
Cycle Consistency Loss#

Fig. 50 cycle consistency loss function#
앞서 말했듯이, mapping distribution 에 제한을 두어 최대한 우리가 원하는 이미지를 생성하기 위해 사용되는 loss function 입니다.
예비 실험에서 L1 norm 을 adversarial loss 로 대체해봤는데, 성능 향상을 관찰할 수 없었다고 합니다.
cycle consistency loss 를 통해 유도된 결과는 아래 그림에서 볼 수 있습니다.

Fig. 51 cycle consistency loss result#
Full Objective#

Fig. 52 full objective function#
이때 consistency loss 앞에 붙은 가중치 \(\lambda\) 는 GAN Loss 와의 상대적 중요도에 따라 결정됩니다.
Implementation#
Network Architecture#
Baseline architecture 로서 neural style transfer 와 super-resolution 에 인상적인 결과를 보여준 논문(https://arxiv.org/abs/1603.08155) 에서 사용된 구조를 채택합니다.
3 개의 convolutions and several residual blocks,
fractionally-strided convolution with stride 1/2,
feature 를 RGB 로 매핑하는 one convolution layer.
6 blocks for 128 x 128 image // 9 blocks for 256 x 256 및 고해상도 학습 image.
instance normalization
Training details#
모델 학습을 안정화시키기 위해 아래와 같은 테크닉을 추가로 적용합니다.
Loss function \(\mathcal{L}_{GAN}\) 에서 nll loss 를 least-squared loss 로 변경
생성된 이미지 중 가장 최근의 50개를 따로 저장해 discriminator 가 이를 한꺼번에 분류(모델 진동을 최소화하기 위함)
(참고) least-square loss 추가 설명#
LSGAN 을 참고했으며, 논문에서는 generator 업데이트시 더 안정적인 학습과 quality 높은 결과를 생성한다고 합니다.

Fig. 53 출처: https://velog.io/@sjinu/CycleGAN#
(원래 Discriminator 는 이보다 더 고차원이지만) 간략히 2차원을 표방하면 결정경계를 위와 같이 나타낼 수 있습니다. 윗 쪽이 가짜 영역, 아래 쪽이 진짜 영역입니다 이 때, 아래에 보면 진짜 데이터 샘플과 거리가 먼 가짜 데이터 샘플이 존재합니다. 즉, NLL Loss 를 사용한다면, Generator 의 입장에서는 이미 Discriminator 를 잘 속이고 있기 때문에 학습할 필요가 없게 됩니다. 즉, Vanishing Gradient 현상이 일어나기 때문에, Discriminator 를 잘 속인다는 이유만으로, 안 좋은 샘플을 생성하는 것에 대해 패널티를 줄 수가 없게 됩니다. 이 때, LSGAN 을 사용한다면 실제 데이터 분포와 가짜 데이터 샘플이 거리가 먼 것에 대해서도 패널티를 주게 됩니다.

Fig. 54 출처: https://velog.io/@sjinu/CycleGAN#
그리고 모든 실험에 대해서 \(\lambda\) 를 10 으로 설정하고, batch size = 1, 그리고 Adam solver 를 사용했습니다. 첫 100 epoch 동안에는 learning rate 를 0.0002 로 설정했고, 다음 100 epoch 마다 0 으로 조금식 수렴하게 scheduling 하였습니다.
Evaluation#
모델 성능 평가를 위해 아래와 같은 세 개의 지표를 기반으로 기존의 CoGAN, SimGAN, pix2pix baseline 모델과 비교했습니다. 그 외 loss function 에 대한 ablation study 도 수행했습니다.
AMT perceptual studies: 참가자들은 실제 사진이미지 vs 가짜 이미지, 또는 지도 이미지 vs 가짜이미지에 노출된 후 진짜라고 생각되는 이미지를 선택하게 합니다.
FCN Score: 1번 study 가 테스트에 있어 매우 좋은 기준임에도 불구하고, 이번에는 사람을 대상으로 한 실험이 아닌 양적인 기준을 사용합니다. 우선적으로 FCN 모델을 통해 생성된 사진에 대한 레이블 맵을 예측합니다. 이 레이블 맵은 아래에서 설명하는 standard semantic segmentation metric 을 사용하여 input ground truth label 과 비교할 수 있습니다. “도로 상의 자동차”라는 label 에서 사진 이미지를 생성하면, 생성된 이미지에 적용된 FCN 이 “도로 상의 자동차”를 감지하면 성공한 것입니다.
Semantic segmentation metric: pixel 당 정확도, class 당 정확도, 그리고 IoU(Intersection-Over-Union) 를 포함하는 cityscapes benchmark 의 표준 metric 를 사용합니다.
Comparison against baselines#

Fig. 55 Comparison aginst baselines#
타 baseline 모델보다 성능이 좋을 뿐만 아니라, fully supervised 모델인 pix2pix 와 비슷한 품질의 translation 성능을 보여줍니다.
AMT Score *

Fig. 56 AMT score#
Table 1 은 AMT perceptual realism task 에 대한 성능을 나타냅니다. CycleGAN 의 지도에서 항공 사진, 그리고 항공 사진에서 지도 translation 결과에서 약 1/4의 참가자를 속일 수 있었던 반면에 그 외 모든 baseline 모델은 참가자를 거의 속일 수 없었습니다.
FCN Score *

Fig. 57 FCN scores#
Table 2, Table 3 는 각각 도시 풍경에 대한 label -> photo, 그리고 photo -> label translation task 의 성능을 보여줍니다. 두 경우 모두 CycleGAN 이 baseline 들의 성능을 능가합니다.
Ablation Study - Analysis of the loss function#

Fig. 58 Analysis of loss function#
GAN 과 cycle consistency loss 의 중요성을 보여주는 ablation study 입니다. GAN loss 그리고 cycle consistency loss 를 각각 제거하면 성능이 크게 저하되는 부분을 확인할 수 있습니다. 또한 한쪽 방향에 대해서만 GAN + forward cycle 만 돌렸을 때와 GAN + backward cycle 만 돌렸을 때 학습의 불안정성을 보이고, mode collapse 를 유발하는 것을 확인할 수 있었다고 합니다.
Image reconstruction quality#

Fig. 59 Results on Cycle Consistency#
Reconctructed 된 이미지 예시들입니다. 지도 -> 항공 사진과 같이 하나의 도메인이 훨씬 더 다양한 정보를 나타내는 경우에도 재구성된 이미지가 훈련 및 테스트 시 모두 원래 입력 \(x\) 에 가깝게 복원되는 경우가 많았습니다.
Additional results on paired datasets#

Fig. 60 Additional results on paired datasets#
Figure 8 은 CMP Facade Database 의 건축 레이블 <-> 사진, 그리고 UT Zapoos50K dataset 의 edge <-> 신발 을 비롯하여 pix2pix 에 사용된 paired dataset 에 대한 몇 가지 예시 결과를 보여줍니다. CycleGAN 이 생성한 이미지 품질이 fully supervised 된 pix2pix 에 대응하는 성능을 보여주는 것을 확인할 수 있습니다.
: shallow depth of field: 얕은 초점. 초점이 맞은 대상과 배경이 흐릿하게 보이는 효과. 인물 사진 / 작품 사진에 활용. 구목하고자 하는 대상을 강조하기 위해 활용. --> 따라서 source domain은 스마트폰의 **작은 조리개로 깊은 초점** \--> target은 **조리개가 커서 얕은 초점**.-->Limitations and Discusssion#

Fig. 61 Limitations and Discussion#
이 방법은 많은 경우에 흥미로운 결과를 얻을 수 있지만, 결과가 균일하게 좋은 것은 아니었습니다.
개 <-> 고양이 translation task 와 같은 경우는 input image 에서 최소한의 변화만 주어, 사람이 보았을 때 실제로 변화가 안되는 경우도 있었고, 형체가 애매해진 경우도 있었습니다. 이를 보았을 때, geometry 가 반영되는 눈, 코, 입 등의 세부적인 구조에 대한 정확히 구현하는데 한계가 있어 보입니다.
말 <–> 얼룩말 translation 예제의 경우, 말은 사람이 타는 모습이 많았는데 얼룩말의 경우는 사람이 타는 사진이 없다보니, 사람 뿐만 아니라 배경도 얼룩 그림을 그리거나 단순히 얼룩말에서 노랗게 칠한 경우가 존재합니다.
때때로 photo -> image translation task 에서 나무와 건물의 label 을 바꾸는 경우도 있었습니다.
이러한 모호성을 해결하려면 weak semantic supervision 이 필요할 수도 있을 것 같습니다.
그럼에도 불구하고 해당 논문은 완전히 paired 되지 않은 “unsupervised” setting 에서도 image translation task 의 한계를 늘리는데 기여합니다.