Information
Title: {Your Diffusion Model is Secretly a Zero-Shot Classifier}, {ICCV 2023}
Reference
Author: SeonHoon Kim
Edited by: SeonHoon Kim
Last updated on Nov. 09, 2023
Your Diffusion Model is Secretly a Zero-Shot Classifier#
핵심
학습된 Diffusion Models 에서 Classifier 를 추가 학습 없이 획득할 수 있다.
Stable Diffusion 같은 거대 모델로부터 Zero-shot classifier 를 얻을 수 있다.
Class-conditional Diffusion Models 에서는 일반적인 (non Zero-shot) classifier 를 얻을 수 있다.
결과 요약
Classification 성능이 나쁘지 않았다.
Zero-shot classifier 는 Multimodal Compositional reasoning ability 가 매우 훌륭했다.
이렇게 Diffusion 모델에서 추출된 Classifiers 는 Distribution shift 에 대해 Robust 한 성능을 보여주었다.
Classifier 구현 방법
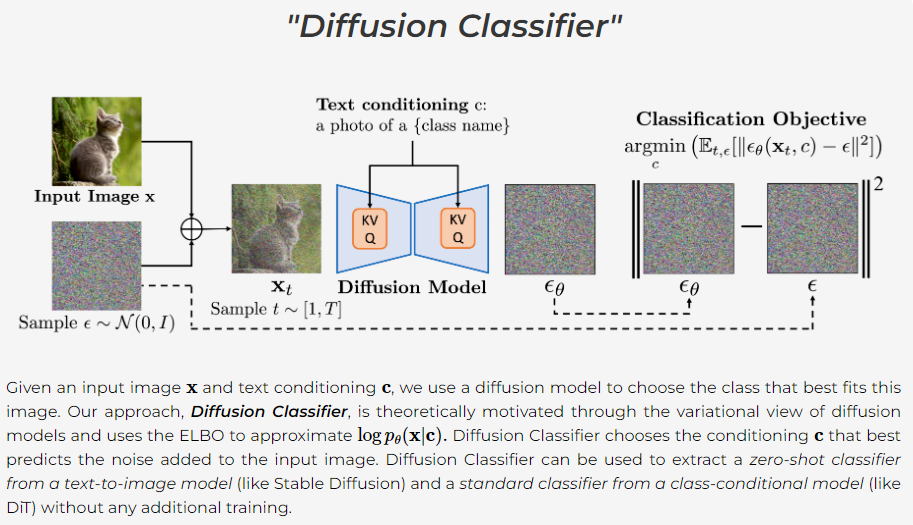
Fig. 388 Diffusion Classifier 아키텍쳐#
예시로 먼저 살펴보기.
예를 들어, 어떤 동물 이미지 X 를 Stable Diffusion 으로 Classification 하고 싶다면..
1. 일단 해당 동물의 클래스를 포함하고 있을 만한 데이터셋을 구한다.
37개의 동물 클래스가 존재하는 Pets 데이터셋을 사용한다고 치자.
2. text prompts 로 “호랑이” 가 주어진 Stable Diffusion 으로,
X 의 Noised Image 에서 Reverse process 를 진행한다. 그럼 Loss 를 획득할 수 있을 것이다.
3. 37개의 모든 Pets Classes 에 대해서 이를 수행해서,
가장 Loss 가 작은 Class 를 판별한다.
이 Class 가 바로 이미지 X 의 클래스이다.

Fig. 389 Algorithm 1 : Diffusion Classifier 학습 알고리즘#
n_samples에 지정된 수 만큼 t 와 noise 를 각각 샘플링해 벡터를 만든다.클래스 판별이 필요한 이미지 X 의 t-step Noised image 인 X_t 를 구한다.
X_t 를 Diffusion Model 에 Input 으로 주어 Noise 를 출력한다.
loss 를 구한다.
위 과정을, 여러 번 (
n_trials만큼) 시도해서 평균낼 수도 있다.
loss 가 가장 낮은 Class 를 찾을 때 까지, 가능한 모든 Class 에 대해 추론한다.
최종 남은 Class 를 X 의 Class 라고 판정한다.
Zero-shot classification 도 위와 동일한 과정으로 진행된다.
다만 추론할 Class list 가 필요하다.
- 예를 들어서, Stable Diffusion 의 Zero-shot classification 을 수행하기 위해서는,
(Stable Diffusion 이 학습하지는 않았지만) 37개의 클래스가 정의되어 있는
Pets 와 같은 데이터셋으로 Classification 을 수행할 수 있다.하지만, Class 마다 n_samples 수 만큼 t 를 샘플링하고,
또 X_t 를 구하고,
Diffusion Model 로 노이즈를 추론하고,
loss 를 구하는 것은 Inference times 가 많이 소모됨.
따라서 다음의 방법을 활용해 inference times 을 줄인다.

Fig. 390 Algorithm 2. Efficient Diffusion Classifier Algorithm#
일단 작은 수의 n_samples 로 error 가 높은 class 들을 걸러낸다.
소수의 class 만 남았다면,
이제는 정확한 추론을 위해서 더 큰 n_samples 를 설정해 추론한다.
(large n_samples 로 t 와 \(\epsilon\) 을 sampling 한다.)
c.f.
### Oxford-IIIT Pets
```bash
python eval_prob_adaptive.py --dataset pets --split test --n_trials 1 \
--to_keep 5 1 --n_samples 25 250 --loss l1 \
--prompt_path prompts/pets_prompts.csv
왜 이렇게까지 inference time 을 줄이려고 하지??
- 위의 스크립트 그대로 RTX 3090 에서 돌리면,
Pets 이미지 1장 Classification 하는데 18초 걸린다.
- ImageNet 은 Class 1,000 개 있는데,
512x512 이미지 1장 Classification 하려면 1,000 초 걸린다.c.f. Loss 계산 코드 (eval_prob_adaptive.py)
all_noise = torch.randn((max_n_samples * args.n_trials, 4, latent_size, latent_size), device=latent.device)
def eval_error(unet, scheduler, latent, all_noise, ts, noise_idxs,
text_embeds, text_embed_idxs, batch_size=32, dtype='float32', loss='l2'):
assert len(ts) == len(noise_idxs) == len(text_embed_idxs)
pred_errors = torch.zeros(len(ts), device='cpu')
idx = 0
with torch.inference_mode():
for _ in tqdm.trange(len(ts) // batch_size + int(len(ts) % batch_size != 0), leave=False):
batch_ts = torch.tensor(ts[idx: idx + batch_size])
noise = all_noise[noise_idxs[idx: idx + batch_size]]
noised_latent = latent * (scheduler.alphas_cumprod[batch_ts] 0.5).view(-1, 1, 1, 1).to(device) + \
noise * ((1 - scheduler.alphas_cumprod[batch_ts]) 0.5).view(-1, 1, 1, 1).to(device)
t_input = batch_ts.to(device).half() if dtype == 'float16' else batch_ts.to(device)
text_input = text_embeds[text_embed_idxs[idx: idx + batch_size]]
noise_pred = unet(noised_latent, t_input, encoder_hidden_states=text_input).sample
if loss == 'l2':
error = F.mse_loss(noise, noise_pred, reduction='none').mean(dim=(1, 2, 3))
elif loss == 'l1':
error = F.l1_loss(noise, noise_pred, reduction='none').mean(dim=(1, 2, 3))
elif loss == 'huber':
error = F.huber_loss(noise, noise_pred, reduction='none').mean(dim=(1, 2, 3))
else:
raise NotImplementedError
pred_errors[idx: idx + len(batch_ts)] = error.detach().cpu()
idx += len(batch_ts)
return pred_errors
실험 결과
Figure 2
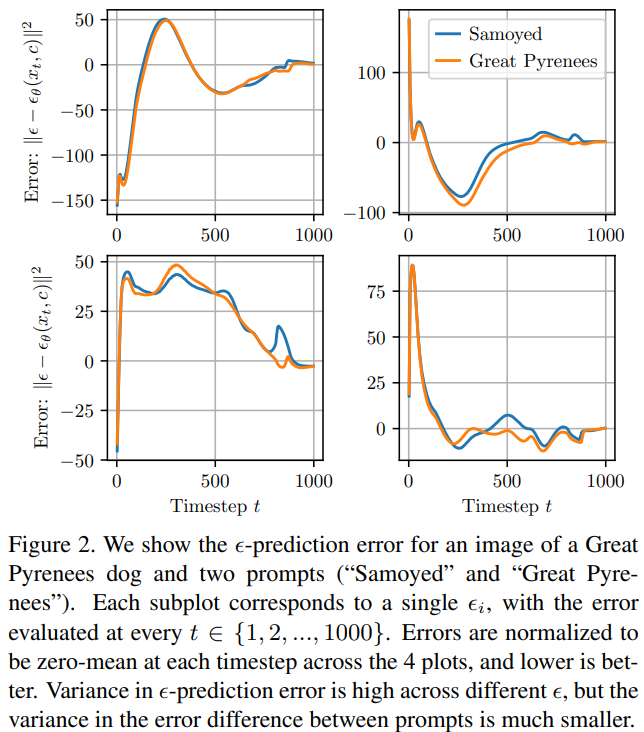
Fig. 391 Figure 2#
특정한 이미지 x 의 모든 클래스에 대해서 loss 를 추론하게 될텐데,
모든 클래스에 대해서
동일한 \(\epsilon\) (즉 sampled noise) 과 동일한 t (즉 sampled time steps) 를 사용해야 한다.
이 두 변수에 따라 loss 가 크게 달라지기 때문.
Figure 3 & Figure 4
Figure 3
t 에 따라서, Classification 성능이 달라졌다.
Figure 4
Figure 3 의 결과에 따라서,
intermediate timesteps 를 더 많이 sampling 하면 성능이 올라가는지 실험해보았다.그렇지 않았다.
timesteps 를 Uniform 하게 sampling 했을 때 성능이 가장 좋았다.
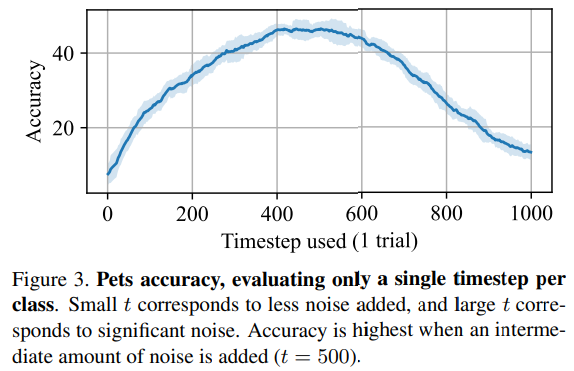
Fig. 392 Figure 3#
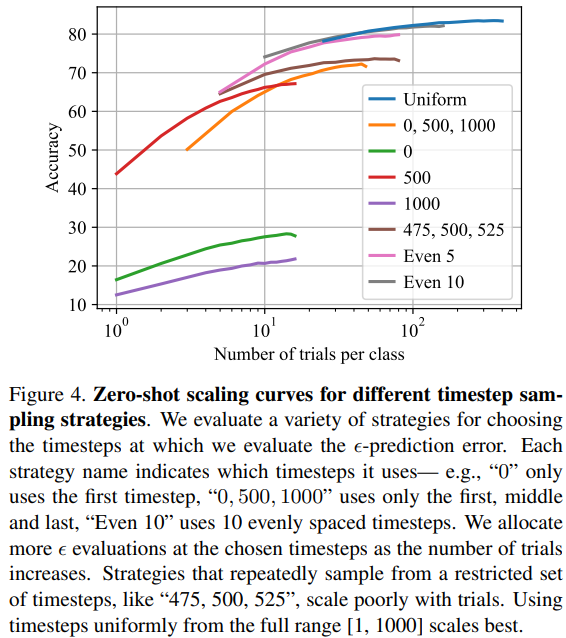
Fig. 393 Figure 4#
Table 1 (+ F. Additional Implementation Details 참고)
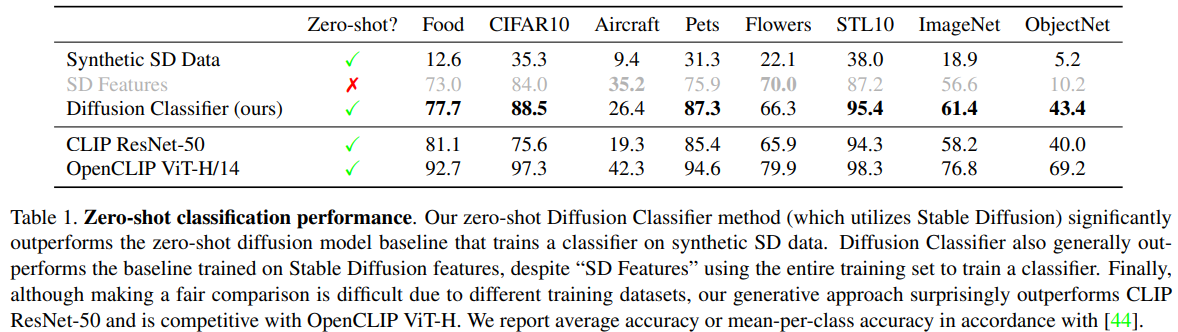
Fig. 394 Table 1#
본 논문에서 제시한 Diffusion Classifier 가 Classification 능력이 나쁘지 않았다.
Diffusion 모델에서 knowledge 를 추출해내는 다른 방법들보다 성능이 뛰어났다.
- Diffusion Classifier 는 Zero-shot 성능이,
“Stable Diffusion 으로 생성된 영상을“ 학습한 ResNet-50 classifier 보다 뛰어났다.
- Synthetic SD data :
Class 마다 10,000 장의 이미지를 Stable Diffusion 2.0 으로 생성해
데이터셋을 구축하고 (90% train / 10% validation),
해당 데이터셋으로 ResNet-50 classifier 를 학습시켜서 classification 수행한 결과
- Diffusion Classifier 는 Classification 성능이,
Stable Diffusion 의 intermediate U-Net layer 를 추출해 학습시킨
ResNet-based 모델보다 뛰어났다.
- SD features :
Input 이미지에 따른 Stable Diffusion 의 Intermediate U-Net features 를
ResNet 기반의 classifier 에 전달해서 추론.
이 때 classifier 는 모든 데이터셋을 직접 학습한다. 따라서 zero-shot 은 아니다.CLIP ResNet-50 모델보다도 성능이 뛰어났다.
OpenCLIP ViT-H/14 모델에 competitive 했다.
Table 2
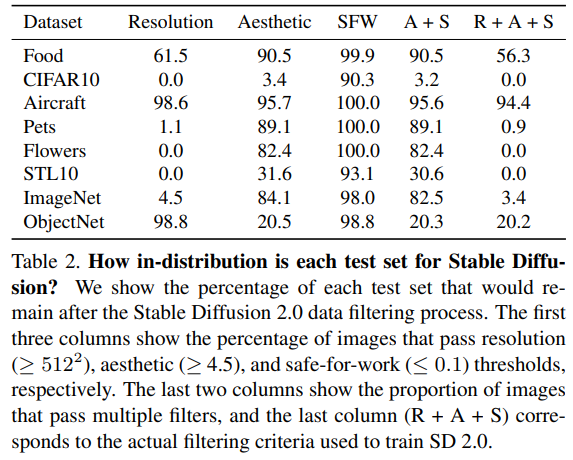
Fig. 395 Table 2#
Stable Diffusion 은
Resolution 이 높은지, Aesthetic 한지, Safe-for-work 한지에 따라서 filtered 된
LAION-5B 데이터셋을 학습했다.이와 같은 기준으로 filtering 하면,
CIFAR10, Pets, Flowers, STL10, ImageNet 데이터셋의 test set 은 97~100% 가 filtered out 된다.따라서, 이들 데이터셋은 Stable Diffusion 에게 완전한 out-of-distribution 데이터이다.
따라서, 필터링이 안된 데이터로 Stable Diffusion 을 추가 학습시키면
classification 성능도 올라갈 것이다.Figure 5 & Table 3

Fig. 396 Figure 5#
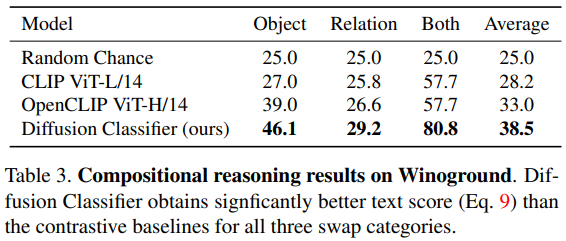
Fig. 397 Table 3#
본 논문에서는 Winoground 데이터셋을 활용해
visio-linguistic compositional reasoning abilities 를 측정했다.주어진 captions 를 적절한 이미지에 매치시키는 능력을 측정하는 것이다.
Winoground 데이터셋
Object 는 명사절끼리 뒤바뀐 경우
Relation 은 동사끼리 or 형용사끼리 or 부사끼리 뒤바뀐 경우
Both 는 다른 품사끼리 서로 뒤바뀐 경우
Stable Diffusion 의 Diffusion Classifier 가 최고의 성능을 보여주었다.
본 논문에서 제시한 method 를 통해서 추가 학습 없이,
여느 diffusion 모델처럼 sample generation 만을 학습했음에도,
Stable Diffusion 모델을 훌륭한 classifier 이자 reasoner 로 변모시킬 수 있었다.Table 4
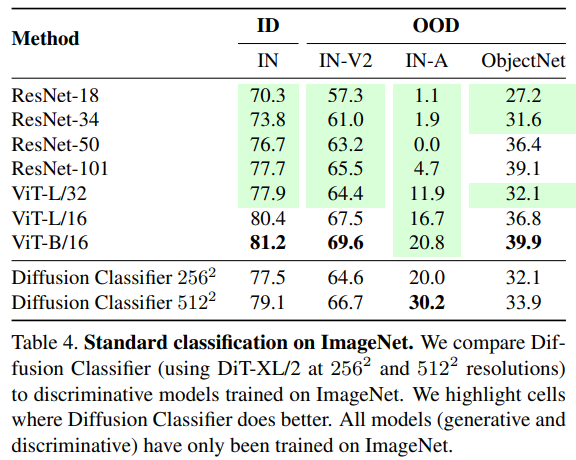
Fig. 398 Table 4#
ImageNet 에 존재하는 1,000 개의 클래스를 활용해
Pretrained DiT (Diffusion Transformer) 를 활용한 Diffusion Classifier 의 성능을,
Discriminative Classifiers (ResNet-101 and ViT-B/16) 와 비교했다.ImageNet 에 대해서, 79.1% 의 top-1 accuracy 를 기록하며 ViT-L/32 을 능가했다.
더 적은 augmentation 기법을 사용하였고,
regularization 은 사용하지 않았음에도 Discriminative Classifiers 의 성능을 능가했다.Figure 6
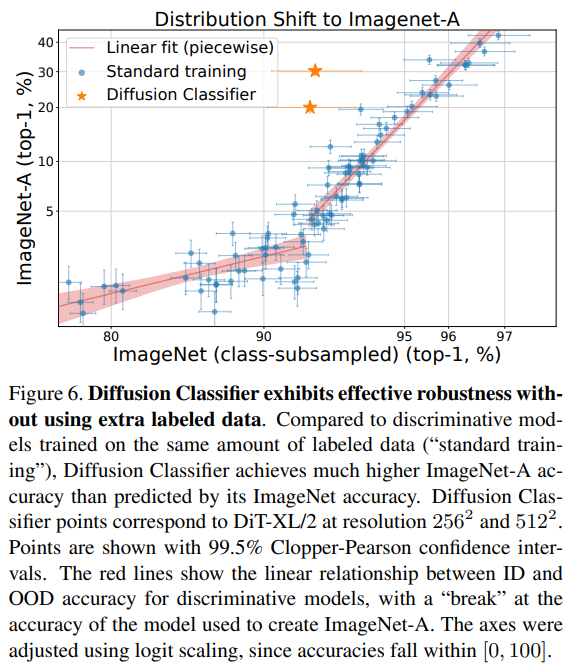
Fig. 399 Figure 6#
ImageNet 데이터셋에서,
ImageNet-A 와 겹치는 클래스에 대해서만 Classification 을 수행한다.일반적인 discriminative classifiers 는 신뢰구간 과 함께 파란 점으로 찍혀 있다.
Diffusion Classifiers 는 신뢰구간 과 함께 별 모양의 점으로 찍혀 있다.
Diffusion Classifiers 는 In-distribution (ImageNet) 에서 획득한 Accuracy 에 따라
기대되는 것보다,
훨씬 Out-of-distribution (ImageNet-A) 에서의 성능이 뛰어났다.
- 즉, OOD 에 훨씬 Robust 하다.결론
Diffusion Models 에서 Diffusion Classifier 를 추출하는 방법을 제시함
Stable Diffusion 에서 추출한 Diffusion Classifier 가 Zero-shot 능력이 우수함을 확인
DiT 에서 추출한 Diffusion Classifier 가 Standard Classification 능력이 우수함을 확인
Diffusion Classifiers 의 Compositional Reasoning 능력이 우수함을 확인
Diffusion Classifiers 가 OOD 에 매우 Robust 함
Filtering 되지 않은 데이터도 학습시킬 수 있다면,
Stable Diffusion 의 Diffusion Classifier 성능은 더 개선될 것임.Imagen 의 경우 OpenCLIP 보다 훨씬 큰 거대 언어 모델인, T5-XXL 을 활용했음.
Imagen 의 Classification 능력은 Stable Diffusion 보다 뛰어날 것으로 예상됨.