Information
Title: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
Reference
Code:
Project Page : https://humanaigc.github.io/animate-anyone/
Author: Geonhak Song
Last updated on {March. 13, 2024}
Animate Anyone#

Fig. 630 Animate Anyone Example Figure#
Abstract#
Diffusion 모델들이 visual generation 연구에 주류가 되었지만, image-to-video 영역에서는 어려움이 있다. 특히, character animation에서 캐릭터의 상세 정보의 일관성을 유지하는 것은 큰 문제이다.
reference image의 복잡한 appearance 특징의 일관성을 유지하기 위해서 spatial attention feature과 통합할 ReferenceNet 설계
controllability와 continuity을 위해서 효과적인 pose guider 도입.
비디오 프레임간 부드러운 전이를 위해 효과적인 effective temporal modeling 도입
이를 통해 어떠한 임의의 캐릭터에 대해서도 animate할 수 있고 우월성을 보임
1. Introduction#
Character Animation History
Character Animation은 source character 이미지로부터 사실적인 비디오를 animate하는 작업으로 GAN을 시작으로 많은 연구가 진행되어왔다.
그러나 생성된 이미지 또는 비디오는 local distortion, blurred details, semantic inconsistency, temporal instability 문제가 있어 널리 사용되기에는 어려움이 있어왔다.
Diffusion 기반 image-to-video 예시
최근 diffusion model의 우수성에 따라 image-to-video task에 diffusion model을 활용하려는 연구들이 보였다.
DreamPose (23.04)
Stable Diffusion을 확장한 fashion image-to-video 합성을 가능하는데 초점을 맞췄다.
본 모델은 CLIP과 VAE feature를 통합한 adpatar module를 제안했다.
그러나 consistent 결과를 위해서 input sample에 대해 추가 finetuning이 필요하고 운용 효율이 떨어진다.
DisCO (23.07)
Stable Diffusion을 수정하여 human dance generation 진행
CLIP과 ControlNet을 활용한 통합 모델 구축
그러나 character detail 보존에 어려움을 겪고 frame간 jittering issue 존재
Character Animation 관점에서의 Text-to-image generation 한계
text-to-image generation & video generation에 시각적 품질과 다양성에 큰 진전이 있어왔지만, 복잡한 detail을 잘 살리는 것이 어렵고 정확도 측면에서도 부정확한 부분이 있다.
더욱이, 실질적 character 움직임을 다룰 때, 일관성 측면에서 안정적이고 연속적인 영상을 만들어내는 것이 어렵다.
현재는 일반성과 일관성을 동시에 만족하는 character animation 방법을 찾을 수 없어 본 논문에서 Animate Anyone 방법을 제안한다.
Animate Anyone 모델 구조 요약
appearance consistency를 위한 ReferenceNet 도입.
spatial attention를 사용하는 UNet으로 ReferenceNet feature과 통합
이는 모델로 하여금 일관된 feature space에서 reference image의 관계성을 종합적으로 학습하게 함
pose controllability를 위한 lightweight pose guider 도입.
효과적인 pose control signal을 denoising 절차에 통합함.
temporal stability를 위한 temporal layer 도입
연속적이고 부드러운 temporal motion process와 동시에 고해상도 detail quality 보존을 위한 frame간 관계성 학습
제안 모델의 결과
5K character video clip 인터넷 데이터 세트로 훈련
장점 1) character appearance의 spatial & temporal consistency을 효과적으로 유지
장점 2) temporal jitter & flickering과 같은 문제 없는 높은 신뢰도의 비디오 생성
장점 3) 어떠한 character image에도 animation video 생성 가능
benchmark에 대한 결과 또한 우수성 증명
3. Methods#
목표 : character animation을 위한 pose-guided image-to-video 합성
3.1 Preliminary: Stable Diffusion#
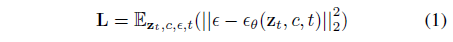
Fig. 631 Eq (1) Stable Diffusion Objective#
\(\epsilon_\theta\) : UNet func
\(c\) : conditional embedding
\(z\) : image latent
\(t\) : timestep
\(z_t\) : noise latent
CLIP ViT-L/14 text encoder
denoising UNet : 4 downsample layers , 1 middle layer, 4 upsample layers.
각 Res-Trans block별 2D convolution, self-attention, cross-attention로 구성
3.2 Network Architecture#
Overview
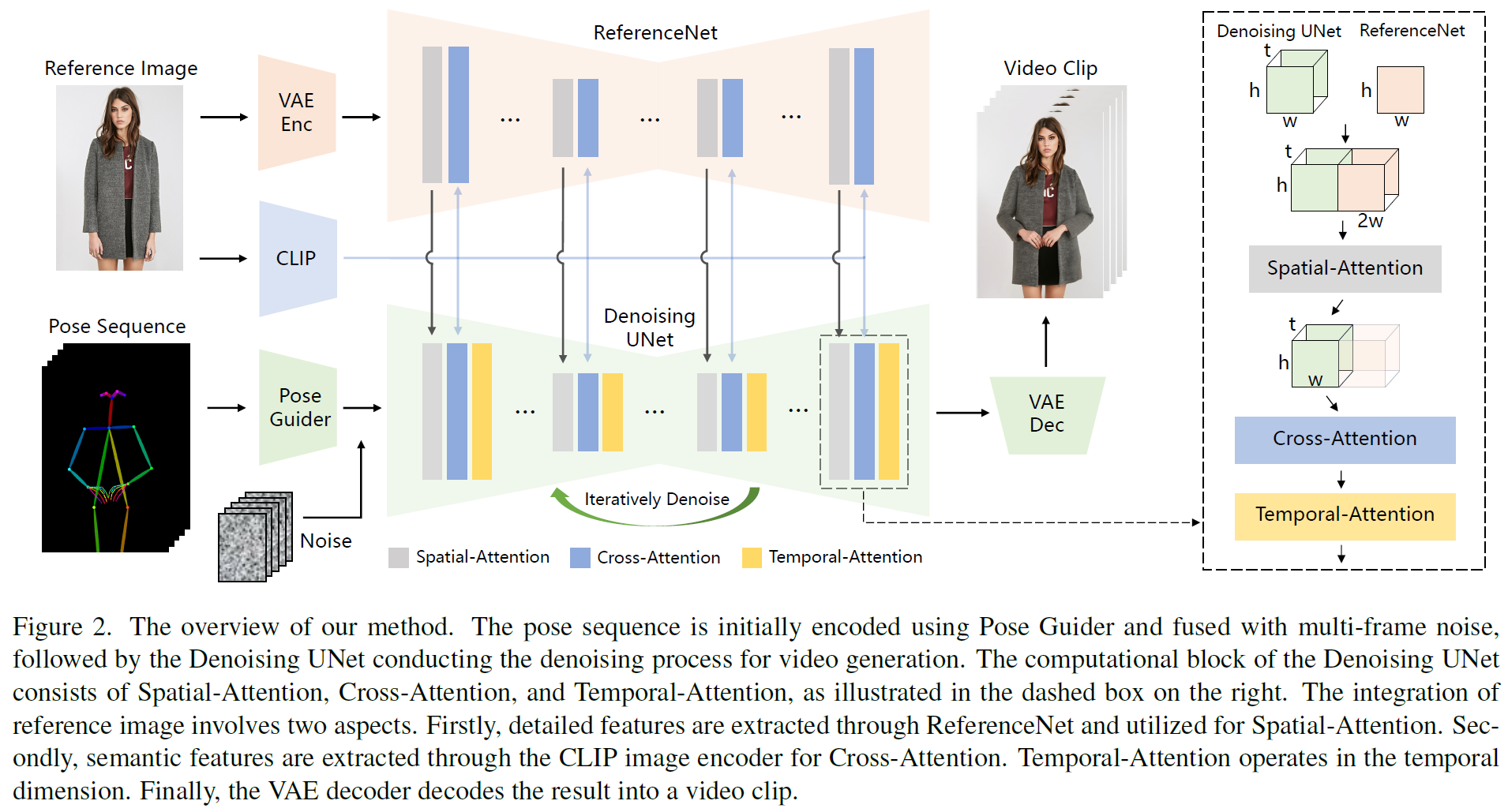
Fig. 632 Figure 2 Animate Anyone Overview#
3가지 중요 요소 통합
ReferenceNet : reference image로부터 character의 appearance features encoding
Pose Guider : 제어가능한 character movements를 위한 motion control signal encoding
Temporal layer : character motion 연속성을 위한 temporal relationship encoding
ReferenceNet
text보다 image가 더 low-level detailed feature를 통한 일관성 유지 정보를 내포함.
이에 따라 최근 CLIP image encoder가 text encoder보다 많이 사용되었지만, detail consistency에는 역부족
이유 1: CLIP image encoder는 224x224의 저해상도 이미지들로 구성되어 중요한 세부정보 손실이 있을 수 있다.
이유 2: CLIP은 text에 더욱 부합하게 훈련되어 high-level feature matching에 강조되고 이에 따라 feature encoding에 있어 detail feature에 부족함이 존재
이에 따라 reference image feature extraction network인 ReferenceNet 고안 (이때 temporal layer 제외)
ReferenceNet은 SD로 초기화하고 각각 독립적으로 update 수행하고 UNet과 통합
self-attention layer를 spatial attention layer로 변경
Feature map : \(x_1 \in \mathcal{R}^{t \times h \times w \times c }\) (UNet ), \(x_2 \in \mathcal{R}^{h \times w \times c }\) (ReferenceNet) 이 주어졌을 때, \(x_2\)를 t번 곱해 w축에 따라 \(x_1\)과 concat
self-attention을 수행하고 feature map의 반을 결과로 뽑음.
2가지 장점
사전 학습된 image feature model SD를 사용함에 따라 초기값이 잘 정의된 것 사용가능.
UNet과 ReferenceNet의 초기값이 공유되고 동일한 네트워크 구조를 가짐에 따라 UNet은 (동일한 feature space에 상관관계가 있는) ReferenceNet feature 중 선별적으로 feature 학습이 가능
CLIP image encoder를 cross-attention에 도입
reference image의 semantic feature를 제공함에 따라 신속한 전체 네트워크 훈련 초기값 설정 가능.
ControlNet은 target image와 공간적으로 align된 정보를 활용 → 부적합
본 방법에서는 reference image와 target image가 공간적으로는 관계되어있지만, align되지 않음.
타 diffusion 기반 video generation에서는 모든 video frame에 대해 denoising을 진행
ReferenceNet은 feature 추출할 때 한 번만 필요
효과 : inference 단계에서 계산량이 증가하지 않는다.
Pose Guider
ControlNet은 robust한 conditional 생성을 입증해왔지만, 추가 Fine-tuning이 필요했었다.
저자들은 추가적인 계산량 증가를 막기위해 추가적인 control network를 통합하지 않고 lightweight Pose Guider 도입
noise latent와 동일 해상도를 가지는 pose 이미지 align을 위해 four convolution layers (4×4 kernels, 2×2 strides, using 16,32,64,128 channels) 사용
Gaussian weights 초기화, final projection layer에서 zero convolution 도입.
Temporal Layer
이미 많은 곳에서 T2I 모델에 temporal layer를 통합했을 때 frame간 temporal dependency가 가능함을 보임.
본 방법에서는 U-Net 내 Res-Trans block 안에 있는 spatial-attention과 cross-attention 진행 후에 temporal layer 추가
순서 1) reshape : \(x \in \mathcal{R}^{b \times t \times h \times w \times c }\) → \(x \in \mathcal{R}^{(b \times h \times w) \times t \times c }\)
순서 2) temporal attention 수행 → residual connection
효과 : appearance details에 대한 temporal smoothness & continuity
3.3 Training Strategy#
훈련 두 단계
첫 번째 단계
temporal layer를 제외한 single-frame noise를 입력으로 받는 모델 학습
ReferenceNet & Pose Guider
reference 이미지는 전체 비디오 클립에서 랜덤으로 선택
초기 weight는 사전학습된 SD weight
Pose Guider는 마지막 projection layer를 제외한 모든 layer gaussian weight 초기화
VAE Encoder, Decoder, CLIP image encoder 는 그대로
두 번째 단계
첫 번째 단계에서 훈련한 모델 속 temporal layer만 훈련
temporal layer 초기값 : AnimateDiff pretrained weight
입력 : 24frame video clip
4. Experiments#
4.1 Implementations#
Data : 5K character video clips (2-10 seconds long) 인터넷에서 다운로드
Pose Estimation Model : DWPose(Distillation for Whole-body Pose estimator) (23.07) IDEA-Research/DWPose (the student’s head with only 20% training time as a plug-and-play training strategy)
GPU : 4 NVIDIA A100 GPUs
첫 번째 훈련 단계 : 768×768 해상도 video frame sampled, resized, and center-cropped 30,000 steps, batch size 64.
두 번째 훈련 단계 : temporal layer 10,000 steps 24-frame video sequences, batch size 4.
learning rates : 1e-5.
Inference 단계 : reference image의 캐릭터 skeleton의 길이에 근사하기 위해서 유도된 pose skeleton의 길이 rescale
DDIM sampler, 20 steps
긴 영상 생성을 위해 temporal aggregation method 채택
Evaluation : benchmark dataset 2개(UBC fashion video dataset, Tik-Tok dataset) 사용
4.2 Qualitative Results#

Fig. 633 Figure 3 Qualitative Results#
전신이 나오는 임의의 characters, 절반 길이의 portraits, cartoon characters, humanoid characters에 대해 animation
reference image와 유사한 temporal consistency를 보이는 사실적인 결과 생성
4.3 Comparisons#
SSIM, PSNR, LPIPS, FVD(Fréchet Video Distance)
Fashion Video Synthesis
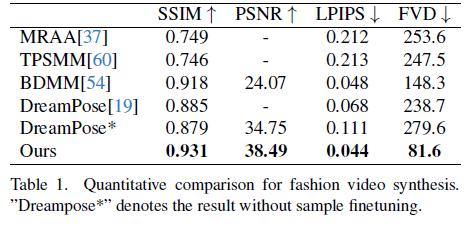
Fig. 634 Table 1 Quantitative Comparison for fashion video synthesis#
Quantitative comparison - Table 1
UBC fashion video dataset (500 training & 100 testing videos로 구성, 각 video 약 500 frames)

Fig. 635 Figure 4 Qualitative comparison for fashion video synthesis#
DreamPose & BDMM은 옷의 일관성을 잃어버리는 문제. 색과 섬세한 구조적 요소에 대한 error 발생
반면, 제안 방법은 옷의 세부 내용까지 일관성있게 보존됨.
Human Dance Generation
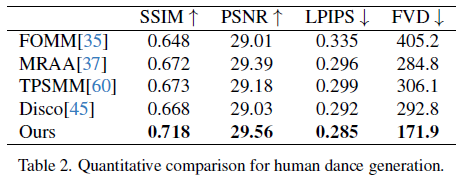
Fig. 636 Table 2 Quantitative comparison for human dance generation#
Quantitative comparison - Table 2
TikTok dataset (340 training & 100 testing single human dancing videos (10-15s))

Fig. 637 Figure 5 Qualitative comparison between DisCo and Animate Anyone method#
DisCo에서는 인물 foreground mask를 위해 SAM 활용하는 pipeline 활용
그러나 본 방법에서는 masking 없이 모델 자체가 subject motion으로부터 전경과 배경의 구분 가능
복잡한 dance sequence에서도 시각적으로 연속적인 motion을 보여줌. robustness
General Image-to-Video Methods

Fig. 638 Figure 6 Qualitative comparison with image-to-video methods#
비교 모델 : AnimateDiff & Gen-2
reference image에 대한 외관 신뢰도만 비교
image-to-video 방법은 얼굴이 일관되게 유지되는 문제에 봉착된 상황 속에서 다른 모델 대비 제안 모델이 긴 시간동안 apperance consistency 유지
4.4 Ablation study#

Fig. 639 Figure 7 Ablation study of different design#
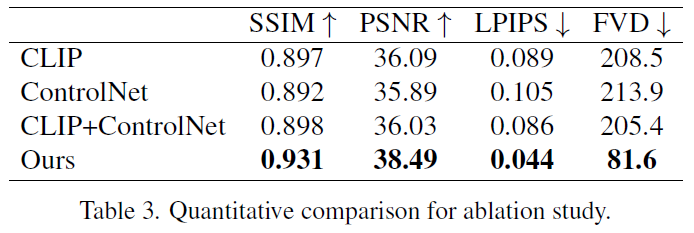
Fig. 640 Table 3 Quantitative comparison for ablation study#
ReferenceNet design 효과성 증명을 위한 Ablation study
(1) CLIP image encoder만 사용
(2) 초기 finetuning SD 이후 reference image 기반 ControlNet training
(3) 위 2 방법론 통합
결론 : ReferenceNet를 사용하는 것이 모든 방법 대비 가장 좋았다.
5. Limitations#
손의 안정적인 움직임을 보이는 것에 어려움을 보임. 가끔 왜곡, motion blur 발생
제공하는 이미지는 한 측면만 보이기 때문에 보이지 않은 부분에 대해서는 ill-posed problem으로 불안정
DDPM 활용에 따른 non-diffusion 기반 모델 대비 낮은 operational efficiency