Dream Booth 3D#
Information
Title: DreamBooth3D: Subject-Driven Text-to-3D Generation
Reference
Project Page : https://dreambooth3d.github.io/
Author: Jeongin Lee
Last updated on {Sep. 3, 2024}
0. Abstract#
DreamBooth3D : 피사체의 3-6개의 캐주얼한 촬영 이미지로부터 text-to-3D 생성 모델을 personalization (맞춤화)
DreamBooth + DreamFusion 의 결합
DreamBooth : personalizing text-to-image models
DreamFusion : text-to-3D generation
두 방법론을 나이브하게 결합시 subject의 input viewpoints 에 대해 오버피팅하는 개인화된 t2i 모델로 인해 Subject 에 대해 만족스럽지 못한 3D 결과물 생성
t2i 모델의 개인화 기능과 함께 NERF의 3D 일관성을 공동으로 활용하는 3단계 최적화 전략 (3-stage optimization strategy)을 통해 이를 극복
Subject 의 입력 이미지에서 볼 수 없는 새로운 포즈, 색상 등 에 대해 텍스트 중심 수정을 통해 고품질의 subject 중심의 3D 결과물 생성 가능
1. Introduction#
도입
3D asset생성은 VR, 영화, 게임 등 다양한 분야에 응용 가능하나, 텍스트 프롬프트만으로 생성된 3D asset 의 정체성, 기하학적 구조, 외관을 정확하게 제어하기 어려움.
특히, 특정 subject 의 특성을 반영하는 3D assets 를 생성하는 능력에 대한 개발 필요
T2I 모델 subject personalization (맞춤화, 개인화) 태스크에서 성공적인 결과를 보인 연구들은 많지만, 3D asset 생성이나 3D control 을 제공하지는 않음.
DreamBooth3D는 소수의 (3-6개) 캐주얼하게 촬영된 이미지로부터 subject 중심의 텍스트-3D 생성을 제안
⇒ NeRF 와 T2I 모델을 함께 최적화하여 subject 중심의 3D 자산을 생성하자 !
문제점
subject에 맞게 개인화된 T2I 모델 & NeRF 를 최적화 하는 것은 여러 실패 사례가 발생
주요 문제 : 개인화된 T2I 모델이 제한된 주제 이미지의 카메라 뷰포인트에 과적합
연속적인 임의의 뷰포인트에서 일관된 3D NeRF 결과물을 최적화하는 데 충분하지 않음.
해결책
DreamBooth3D는 효과적인 3단계 최적화 방식을 제안
Dream Booth , Dream Fusion 사용
[STEP 1️⃣]
DreamBooth 모델을 부분적으로 미세 조정
DreamFusion을 사용하여 NeRF 최적화
부분적으로 미세 조정된 DreamBooth 모델은 주어진 대상 뷰에 과적합 되지 않으며 모든 subject별 세부 정보를 캡처하지 않음
결과적으로 생성된 NeRF 자산은 3D 일관성이 있지만 subject 에 대한 특성을 완전히 반영하지못함.
[STEP 2️⃣]
DreamBooth 모델을 완전히 미세 조정하여 세부 사항을 캡처
1단계에서 학습된 NeRF의 다중 뷰 렌더링을 완전히 학습된 DreamBooth 모델에 투입
이를 통해 subject 별로 다중 뷰 가상 이미지 집합을 생성
[STEP 3️⃣]
1단계의 주어진 subject 이미지와 가상(pseudo) 다중 뷰 이미지를 사용하여 DreamBooth 모델을 추가로 최적화
추가 최적화한 DreamBooth 로 NeRF 3D 볼륨을 최종 최적화
최종 NeRF 최적화시 추가 규제항으로 pseudo 다중 뷰 데이터 세트에 대한 weak reconstruction loss를 사용
3단계에 걸친 NeRF 및 T2I 모델의 합동 최적화는 DreamBooth 모델이 subject 의 특정 view point 에 과적합되는 것을 방지하는 동시에 동시에 결과 NeRF 모델이 대상의 정체성에 충실하도록 보장
결과
실험 샘플 결과들을 통해 본 접근 방식이 입력 텍스트 프롬프트에 존재하는 컨텍스트를 존중하면서 주어진 대상과 유사성이 높은 현실적인 3D 자산을 생성할 수 있음을 입증
여러 베이스라인과 비교할 때, 정량적 및 정성적 결과는 DreamBooth 3D 생성이 보다 3D 일관성이 있고 대상 세부 사항을 더 잘 포착한다는 것을 입증
2. Related Work#
Text-to-Image Generation.
텍스트 조건 반영 : 사용자가 제공한 자연어 텍스트 프롬프트에 정렬된 이미지를 생성하기 위해 사전 학습된 large language model (LLM) 을 활용
T2I diffusion 모델의 성공에 힘입어, 많은 작품들이 텍스트 기반 이미지 조작과 같은 다양한 작업에 사전 학습된 T2I 모델을 활용합니다
3D Generation.
최근 사전 학습된 대규모 T2I diffusion 모델을 활용하여 텍스트 프롬프트에서 3D 자산을 생성할 수 있는 text-to-3D 방법이 제안
기존 방법론
텍스트를 통해 t2i 모델로 이미지를 직접 reconstruction
본 방법론
입력 이미지를 직접 reconstruction 하지 않고 suject 개념을 제공하기 위한 입력 이미지 사용 → Recontextualization 수행 가능 (sleeping, jumping, color…etc)
입력 이미지를 동일한 배경, 조명, 카메라 등으로 촬영할 필요가 없음.
Subject-driven Generation.
Subject 중심 이미지 생성의 최근 발전을 통해 사용자는 특정 대상과 개념에 대해 이미지 생성을 개인화(맞춤화)
DreamBooth
희귀 토큰, 모델 finetuning, 규제를 위한 prior preservation loss를 사용하여 모델의 언어 비전 사전을 확장하여 이를 달성Textual Inversion 입력 개념을 나타내는 사전 학습된 text-to-image 모델의 임베딩 공간에서 새로운 word 를 최적화함으로써 이를 달성

Fig. 732 Textual Inversion \ (source: {https://arxiv.org/abs/2208.01618})#
→ 이러한 방법론들은 3D asset 을 제공하지 않고 일관성 있는 3D 이미지를 생성할 수 없음.
3. Approach#
Problem setup.

Fig. 733 Input and Output#
Input : subject 이미지 집합, 텍스트 프롬프트
\(\left\{I_i \in \mathbb{R}^{n \times 3}\right\}(i \in\{1, \ldots, k\})\) : 각 n개의 픽셀, k 장의 subject 이미지들의 집합
context(맥락) 부여, 의미 변화를 위한 텍스트 프롬프트 T (ex) sleeping, standing…etc.
🌟 Goal 텍스트 프롬프트에 충실하면서 주어진 subject 의 identity (기하 형태 및 외관)을 반영하는 3D assets 생성#
3D volume 에서 radiance 필드를 인코딩하는 MLP 네트워크 \(M\) 으로 구성된 Neural Radiance Fields (NeRF) 를 기반으로 3D assets 를 최적화
본 문제는 subject 이미지에 대한 반영이 필요하기 때문에, 일반적인 multi-view 이미지 캡처가 필요한 3D reconstruction 설정에 비해 상당히 제한적이고 어려운 문제
T2I personalization 및 Text-to-3D 최적화의 최근 발전을 기반으로 기술을 구축
⇒ DreamBooth personalization + DreamFusion text-to-3D로 최적화를 사용
3.1. Preliminaries#
3.1.1 T2I diffusion models#
T2I diffusion models : Imagen, StableDiffusion and DALL-E 2 …etc..
T2I diffusion model \(\mathcal{D}_\theta(\epsilon, \mathbf{c})\)
input :초기 노이즈 \(\epsilon\) , 프롬프트 텍스트 임베딩 \(\mathbf{c}\)
an initial noise \(\epsilon \sim \mathcal{N}(0,1)\)
text embedding \(\mathbf{c}=\Theta(T)\) (a given prompt \(T\) with a text encoder \(\Theta\))
output : 프롬프트를 반영하여 생성한 이미지
T2I diffusion model 을 통해 생성된 이미지는 일반적으로 프롬프트와 일치하지만 생성된 이미지내에서 세부적인 제어가 어려움. → DreamBooth 를 통해 이를 해결
3.1.2 Dream Booth T2I Personalization.#
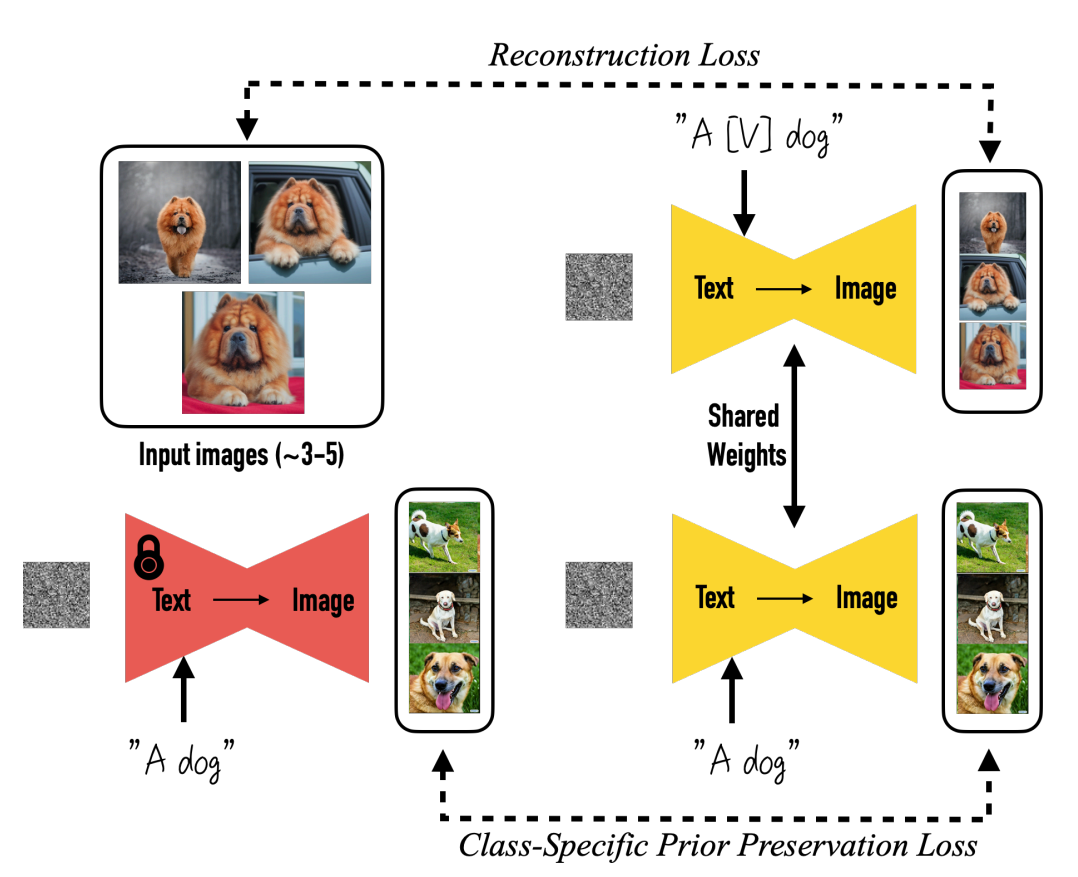
Fig. 734 특정 피사체에 대한 소수의 이미지 집합 (3-5장) 을 통해 텍스트로 주어지는 Context 에 맞는 맞춤화 이미지 생성#
\(\left\{I_i\right\}\) 에서 네트워크를 파인튜닝하여 T2I diffusion 모델을 맞춤화, \(\left\{I_i\right\}\) : a small set of casual captures
DreamBooth diffusion loss : T2I model 파인튜닝을 위해 사용
\[ \mathcal{L}_d=\mathbb{E}{\epsilon, t}\left[w_t\left\|\mathcal{D}_\theta\left(\alpha_t I_i+\sigma_t \epsilon, \mathbf{c}\right)-I_i\right\|^2\right], \]\(t \sim \mathcal{U}[0,1]\) : the time-step in the diffusion proces
\(w_t, \alpha_t, \sigma_t\) : the corresponding scheduling parameters
DreamBooth Class prior preserving loss
DreamBooth 는 \(\left\{I_i\right\}\) 에 대한 over fitting 을 방지하여 다양성을 개선하고, language drift 현상을 피하기 위해 선택적으로 class prior preserving loss 를 사용
최종 loss : reconstruction loss + class prior preservation loss
(example) over fitting

Fig. 735 over fitting#
(example) language-drift

Fig. 736 language-drift#
3.1.3 DreamFusion#
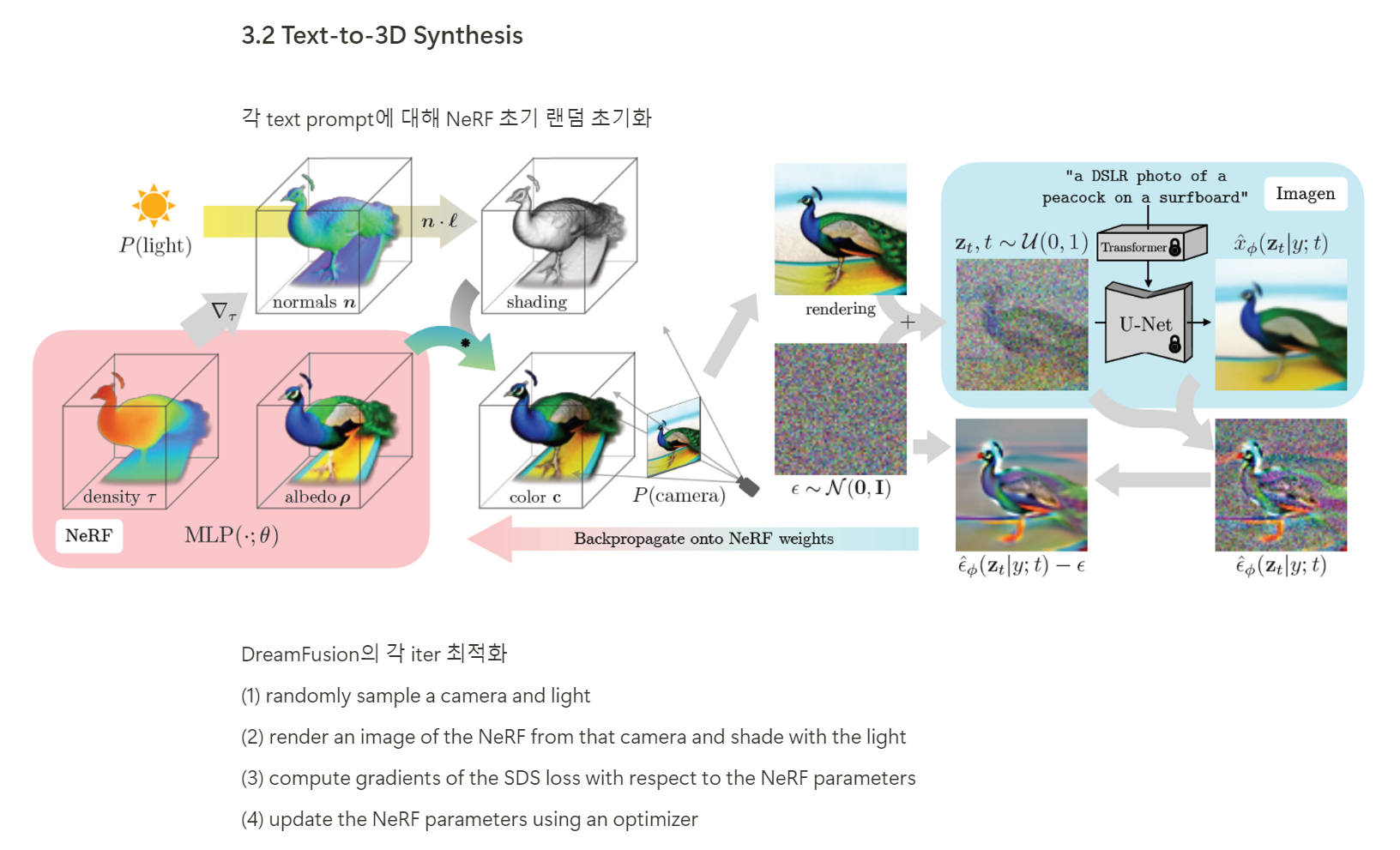
Fig. 737 DreamFusion process / (source : DreamFusion)#
T2I diffusion model을 사용하여 볼륨의 랜덤뷰가 프롬프트 \(T\) 에 상응하도록 NeRF \(\mathcal{M}_\phi\) (\(\phi\) : parameters) 를 통해 표현된 볼륨을 최적화
normals : 밀도의 그래디언트로부터 계산된 nomals은 Lambertian shading 으로 기하학적 사실성을 개선시키기 위해 모델을 랜덤으로 relight 하는데 사용됨.
\(\mathcal{M}_\phi\) : mapping (camera, light (location) → albedo &density)
랜덤 뷰 \(v\), 랜덤 조명(light) 방향이 주어지면 shaded(음영 처리된) 이미지 \(\hat{I}v\) 로 볼륨 렌더링을 수행
이 때 볼륨 렌더링한 이미지가 텍스트 프롬프트 \(T\) 처럼 보이도록 NeRF \(\phi\) 의 매개변수를 최적화하기 위해 DreamFusion 은 score distillation sampling *(SDS) 를 도입
score distillation sampling (SDS)
\[ \nabla_\phi \mathcal{L}_{SDS}=\mathbb{E}{\epsilon, t}\left[w_t\left(\mathcal{D}_\theta\left(\alpha_t \hat{I}_v+\sigma_t \epsilon, \mathbf{c}\right)-\hat{I}_v\right) \frac{\partial \hat{I}_v}{\partial \phi}\right] . \]렌더링된 이미지의 노이즈가 처리된 버전들을 T2I diffusion model의 낮은 에너지 상태로 push
다양한 views를 랜덤으로 선택하고, NeRF 를 통해 역전파 함으로써, rendering 결과들이 T2I model \(\mathcal{D}_\theta\) 로 주어진 프롬프트에 맞게 생성된 이미지처럼 보이도록 함.
DreamFusion 에서 사용된 실험 환경을 정확하게 동일하게 사용함.
3.2 Failure of Naive Dreambooth+Fusion#
피사체(subject) 중심 text-to-3D 생성을 위한 직관적인 접근 방식
subject에 대해 T2I model 을 pesonalized(맞춤화)
맞춤화된 T2I model 을 text-to-3D optimization 을 위해 사용
즉, DreamBooth 최적화(personalized) ⇒ DreamFusion 최적화
BUT, Naive Dreambooth+Fusion 의 결합은 불만족스러운 결과를 초래
핵심 문제 (KEY Issue)
Dream Booth가 훈련된 뷰에 존재하는 subject 의 뷰에 과적합 되어 이미지 생성에서 viewpoint 에 대한 다양성이 감소하는 경향을 보임.
미세 조정 단계가 증가할수록, Subject 유사성 증가 (👍) BUT input exemplar views에 유사하도록 viewpoints 생성 (👎) ⇒ 즉, 다양한 시점에서 이미지를 생성하는 능력이 저하됨.
이런 DreamBooth 모델 기반의 NeRF SDS 손실은 일관된 3D NeRF 결과물을 얻기에 불충분
DreamBooth+Fusion NeRF 모델이 서로 다른 view 에 걸쳐 학습된 동일한 대상에 대한 뷰(예: face of a dog : 다양한 각도에서 본 동일한 dog face)를 가지고 있음.
“Janus problem” : 두 가지 상반되거나 연관된 측면을 동시에 다루어야 하는 문제
3.3. Dreambooth3D Optimization#
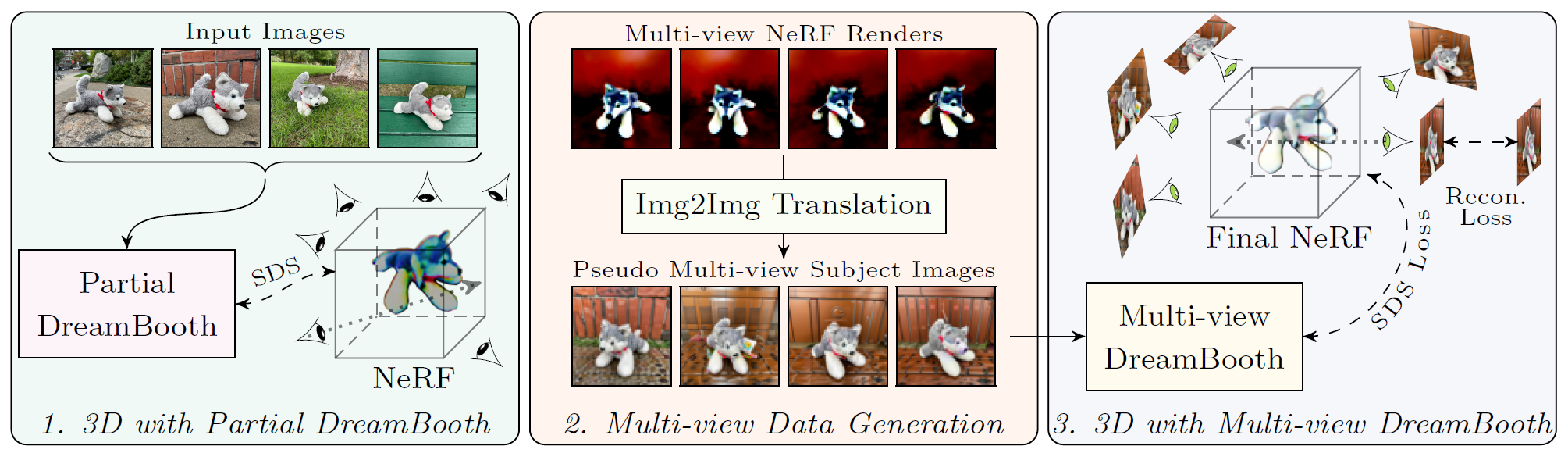
Fig. 738 DreamBooth3D Overview#
DreamBooth3D Overview
stage-1 (왼쪽): 먼저 DreamBooth를 부분적으로 훈련시키고, 결과 모델을 사용하여 초기 NeRF를 최적화
stage-2 (가운데): 초기 NeRF에서 랜덤 시점에 따라 다중 시점 이미지를 렌더링한 후, 완전히 훈련된 DreamBooth 모델을 사용하여 이를 가상 다중 시점 subject 이미지로 변환
stage-3 (오른쪽): 다중 시점 이미지를 사용하여 부분적인 DreamBooth를 추가로 미세 조정한 다음, 결과적으로 얻어진 다중 시점 DreamBooth를 사용하여 최종 NeRF 3D 자산을 SDS 손실과 다중 시점 재구성 손실을 통해 최적화
위의 문제를 해결하고 성공적인 subject 맞춤 text-to-3D 생성을 위해 효율적인 3단계 최적화 방식을 기반으로 한 Dream-Booth3D 제안
3.3.1 Stage 1️⃣: 3D with Partial DreamBooth#
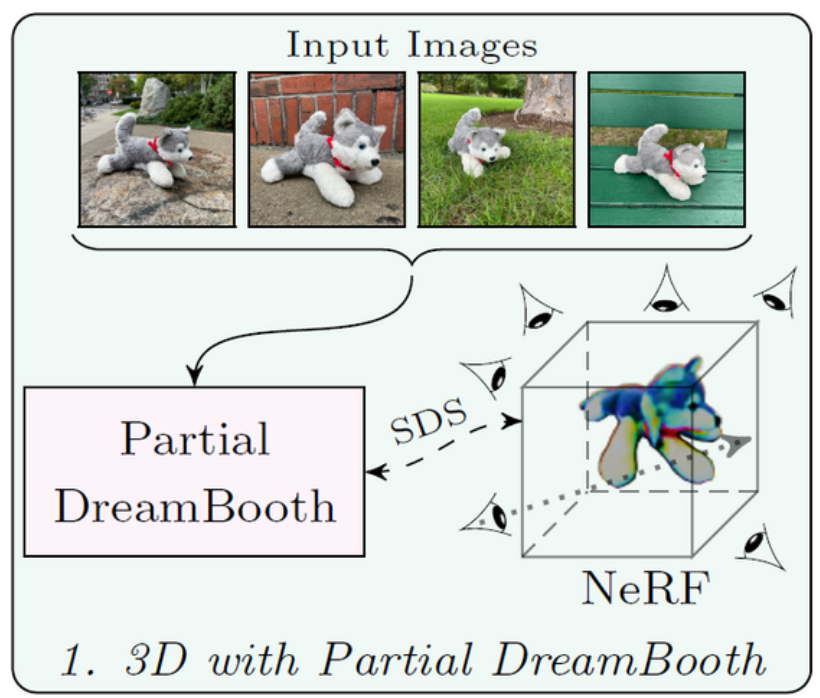
Fig. 739 Stage-1 : 3D with Partial DreamBooth#
입력된 Subject 이미지를 사용하여 DreamBooth 모델 \(\hat{\mathcal{D}}_\theta\) 를 훈련
🌟 DreamBoothT2I 모델의 초기 체크포인트가 (=부분적으로 파인튜닝한 결과) 주어진 subject view에 과적합되지 않음을 확인
⇒ partial DreamBooth (부분적으로 파인튜닝한 Dreambooth)
partial DreamBooth 모델 하에 DreamFusion은 더 일관된 3D NeRF를 생성가능
NeRF 최적화시 SDS 손실 사용 :
\(\nabla_\phi \mathcal{L}_{SDS}=\mathbb{E}{\epsilon, t}\left[w_t\left(\hat{\mathcal{D}}_\theta^{\text {partial }}\left(\alpha_t \hat{I}_v+\sigma_t \epsilon, \mathbf{c}\right)-\hat{I}_v\right) \frac{\partial \hat{I}_v}{\partial \phi}\right]\)
\(\hat{\mathcal{D}}_\theta^{\text {partial }}\): partial DreamBooth
SDS 손실을 사용하여 주어진 텍스트 프롬프트에 대한 초기 NeRF 자산을 최적화
partial DreamBooth 모델과 NeRF 결과물은 입력된 subject 와 완전히 유사하지 않음
🌟 즉, Stage-1️⃣ 에서의 초기 NeRF 는 주어진 subject 와 부분적으로ㅁ 유사하면서, 주어진 텍스트 프롬프트에 충실한 subject class 3D 모델
3.3.2 Stage 2️⃣: Multi-view Data Generation#
🌟 Stage-2 Multi-view Data Generation : 본 접근법의 가장 중요한 부분
일관성을 갖춘 3D initial NeRF 와 fully-trained DreamBooth 를 사용하여 pseudo multi-view subject 이미지들을 생성
Initial NeRF 로부터 다양한 랜덤 viewpoints \(\{v\}\)을 따라 여러 이미지\(\left\{\hat{I}v \in \mathbb{R}^{n \times 3}\right\}\) 를 렌더링하여 다중 시점 렌더링을 생성
각 렌더링에 고정된 양의 노이즈를 추가하는 forward diffusion 과정을 통해 \(t_{pseudo}\)로 전환
reverse diffusion 과정을 실행하여 fully-trained DreamBooth 모델 \(\hat{\mathcal{D}}_\theta\) 를 사용하여 샘플을 생성
샘플링 과정은 각 뷰에 대해 독립적으로 수행
Initial NeRF 결과물 에 노이즈를 추가한 noisy render 를 조건으로 지정함으로써, 넓은 범위의 시점을 커버하면서 subject 를 잘 나타내는 이미지 생성 가능 ⇒ 다양한 노이즈가 있는 이미지를 조건으로 학습시, 다양한 변형에 대한 학습 가능하기 때문
BUT reverse diffusion 과정은 다른 뷰에 다른 세부 사항을 추가할 수 있기 때문에 결과 이미지는 multi-view 에 대한 일관성이 없음.
⇒ 가상(pseudo) 다중 시점 이미지 집합 (collection of pseudo multi-view images)
🔑 Key insight
초기 NeRF 이미지가 unseen views 에 가까울 경우, DreamBooth가 Subject 의 unseen views를 효과적으로 생성 가능
입력 이미지에 비해 Subject 와 더 유사한 출력 이미지를 효과적으로 생성가능**
위 그림을 통해 체크할 부분
fully-trained DreamBooth 를 사용한 Img2Img 변환의 샘플 출력
입력 NeRF 렌더링의 시점을 유지하면서도 subject 이미지와 더 유사한 모습
기존 연구들과 달리 Img2Img 변환을 DreamBooth, NeRF 3D assets 과 결합하여 사용 (기존 연구의 경우 Img2Img 변환을 이미지 editing 응용으로만 사용)
3.3.3 Stage3️⃣: Final NeRF with Multi-view DreamBooth#
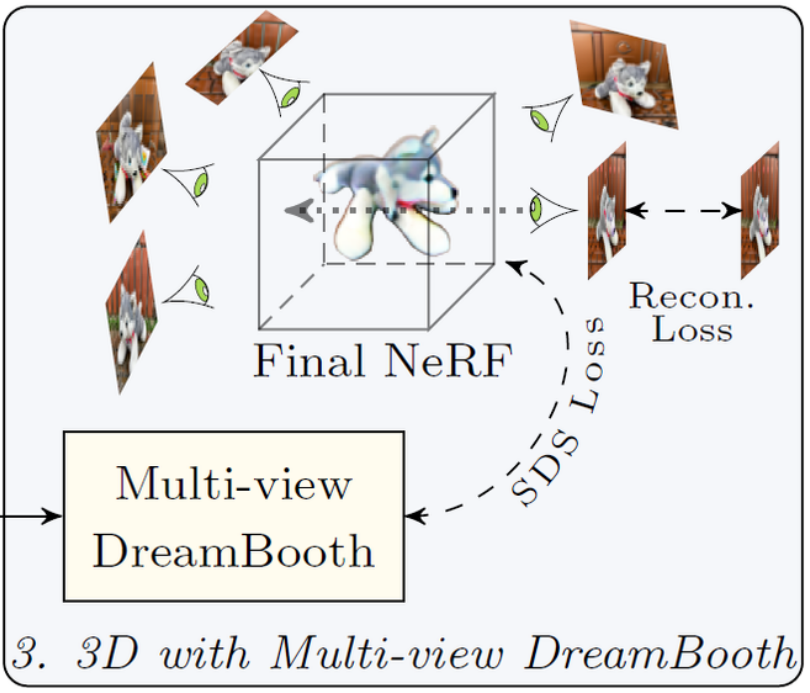
Fig. 740 Stage-3 : Final NeRF with Multi-view DreamBooth SDS와 multi-view reconstruction 손실을 사용한 최종 NeRF 최적화#
새로운 데이터 \(I^{\text{aug}}\) 생성
가상 다중 시점 이미지 \(\left\{I_v^{\text {pseudo }}\right\}\), 입력 Subject 이미지 \(\left\{I_i\right\}\) 의 결합을 통해 생성
\(I^{\text {aug}}\) 를 사용하여 최종 Multi-view DreamBooth 모델을 최적화
1단계에서 partial DreamBooth \(\hat{\mathcal{D}}_{\theta^*}\) 준비
위의 증강 데이터 \(I^{\text {aug}}\) 를 사용하여 \(\hat{\mathcal{D}}_{\theta^*}\) 에 대한 파인튜닝을 추가 진행
Multi-view DreamBooth \(\hat{\mathcal{D}}_\theta^{\mathrm{multi}}\) 를 생성
\(\hat{\mathcal{D}}_\theta^{\text {multi }}\) 모델을 사용하여 DreamFusion SDS Loss 와 함께 NeRF 3D assets 를 최적화
1단계의 partial DreamBooth에 비해 multi-view DreamBooth 의 뷰 일반화와 subject 보존 능력이 더 우수하기 때문에 subject idendtity가 상당히 향상된 NeRF 모델 생성 가능
BUT SDS 손실만 사용시 최적화된 NeRF assets 이
주어진 subject 에 대해 우수한 기하학적 유사성 보유
Color saturation artifacts 현상 다수 발생
이를 해결하기 위해 \(\left\{I_v^{\mathrm{pseudo}}\right\}\) 를 사용한 새로운 weak reconstruction loss 도입
**** Color saturation artifacts :**
색상의 과도한 포화(saturation)로 인해 비현실적이거나 왜곡된 색상 표현이 나타나는 결함 현상
모델이 특정 색상을 과도하게 강조하는 경우 발생
색상 값을 잘못 예측하여 비현실적인 색상 표현이 나타난 경우 발생
다양한 시점에서 일관된 색상 표현을 유지하지 못한 경우 발생
Reconstruction loss
\(\left\{I_v^{\mathrm{pseudo}}\right\}\) 가 생성된 카메라 매개변수 \(\left\{P_v\right\}\) 정보를 알고 있으므로, 두 번째 NeRF MLP \(\mathcal{F}\gamma\) 의 훈련을 reconstruction loss 를 통해 추가로 규제
\[ \mathcal{L}_{recon }=\left\|\Gamma\left(\mathcal{F}_\gamma, P_v\right)-I_v^{\text {pseudo }}\right\|_p, \]\(\Gamma\left(\mathcal{F}\gamma, P_v\right)\) : 카메라 시점 \(P_v\) 를 따라 NeRF \(\mathcal{F}\gamma\) 에서 이미지를 렌더링하는 함수
Reconstruction loss 의 목적
생성된 볼륨의 색상 분포를 image exemplars 과 더 가깝게 조정
unseen views에서 subject 유사성을 향상
Final NeRF Loss function
\(\mathcal{L}_{\text {nerf }}\) 는 Mip-NeRF360 [2]에서 사용된 추가적인 NeRF 정규화
4. Experiments#
Implementation Details.
사용 모델:
T2I : Imagen T2I 모델
Text-encoding: T5-XXL
NeRF : DreamFusion
훈련 시간: 4core TPUv4, 각 프롬프트당 3단계 최적화를 완료하는 데 약 3시간 소요
훈련 단계:
부분 DreamBooth 모델 (\(D_θ^{partial}\)) : 150번의 반복훈련
전체 DreamBooth 모델 (\(D_θ\)) : 800번 반복 훈련시 최적의 성능
pseudo multi-view data generation : 원점에서 고정된 반경으로 균일하게 샘플링한 20개의 이미지를 렌더링
Stage-3 Multi-view DreamBooth \(\hat{\mathcal{D}}_\theta^{\mathrm{multi}}\): 3단계에서 추가로 150번 반복하여 부분적으로 훈련된 \(\hat{D}_{θ}^∗\) 모델을 Finetuning
Hyperparams : supplementary material 참고
Datasets.
훈련 데이터: 공개된 이미지 컬렉션을 사용하여 personalized text-to-3D 모델을 훈련
다양한 subject(개, 장난감, 배낭, 선글라스, 만화 캐릭터 등) 의 4-6개의 casual 이미지를 포함한 30개의 다른 이미지 컬렉션으로 구성
희귀 객체 성능 분석: “올빼미 장식품”과 같은 희귀한 대상의 성능을 분석하기 위해 추가 이미지 수집
3-6개의 프롬프트에 대해 각 3D 모델을 최적화하여 3D contextualizations 문맥화 시연
Baselines.
Latent-NeRF
RGB 픽셀 공간이 아닌 Stable Diffusion 의 latent feature 공간에서 SDS 손실을 통해 3D NeRF 모델을 학습
baseline 으로써 fully dreamboothed T2I model 를 사용하여 Latent-NeRF 실행
DreamFusion+DreamBooth: DreamBooth 확산 모델을 먼저 훈련한 후 DreamFusion을 사용하여 3D NeRF를 최적화하는 단일 단계 접근 방식
본 연구의 3단계 최적화 기반 방법론 : “DreamBooth3D”
Evaluation Metrics.
CLIP R-Precision
rendering된 장면들이 주어졌을 때 프롬프트와 얼마나 정확하게 일치하는지 비율을 나타냄.
CLIP ViT-B/16, ViT-B/32, ViT-L-14 모델을 평가에 사용
추가적으로 user study 수행 (뒤에 언급)
4.1. Results#
Visual Results
비교 결과: DreamBooth3D, Latent-NeRF, DreamBooth+Fusion 기준 모델의 비교
Latent-NeRF : 일부 경우(오리)에서 적절히 작동하지만, 대부분의 경우 일관된 3D 모델을 생성하는 데 실패
DreamBooth+Fusion : 여러 시점에서 동일한 외형 및 구조를 보임
DreamBooth3D : 360도 일관된 3D Asset을 생성하며, 주어진 subject 의 기하학적 구조 및 외관의 세부 사항을 잘 반영함
Initial vs. Final NeRF
1단계와 3단계에서 생성된 초기 NeRF와 최종 NeRF 결과
초기 NeRF : 주어진 subject 와 부분적으로만 유사, 3D 일관성을 유지
최종 NeRF : 주어진 subject 와 더 유사하, 일관된 3D 구조를 유지
이러한 예시는 DreamBooth3D의 3단계 최적화가 필요함을 입증 (?)
User Study.
→ DreamBooth3D와 비교 모델들을 세가지측면에 대해 아래의 질문에 대한 답변으로 평가**
subject 충실도: “어떤 3D 항목이 subject 와 더 유사하게 보입니까?”
3D 일관성과 타당성: “어떤 3D 항목이 더 타당하고 일관된 기하학적 구조를 가지고 있습니까?”
프롬프트 충실도: “어떤 비디오가 제공된 프롬프트를 더 잘 반영합니까?”
연구 방법
3D 일관성과 주제 충실도 연구에서는 데이터셋의 30개 subject 각각에 대해 회전 비디오 결과를 제시하고 11명의 사용자가 각 쌍에 대해 응답
프롬프트 충실도 연구에서는 54개의 고유한 프롬프트와 주제 쌍에 대해 비디오를 생성하고, 21명의 사용자가 응답
최종 결과
최종 결과는 다수결 투표를 통해 산출
DreamBooth3D는 3D 일관성, 주제 충실도, 프롬프트 충실도에서 기준 모델들보다 유의미하게 더 선호됨.
4.2. Sample Applications#
Recontextualization. (재문맥화)
단순한 프롬프트를 사용하여 다양한 개 주제의 3D 모델로 재문맥화한 샘플 결과
모든 subject 에서 텍스트 프롬프트에 주어진 문맥을 일관되게 반영
출력된 3D 모델의 자세와 로컬 변형은 입력 이미지에 없는 포즈임에도 불구하고 매우 사실적
Color/Material Editing.
색상 편집 및 재질 편집
Accessorization
subject 에 액세서리 추가
Stylization
크림색 신발을 색상과 프릴 추가를 기반으로 스타일화
Cartoon-to-3D
비사실적 피상체 이미지(예: 2D 평면 캐릭터)를 그럴듯한 3D 형태로 변환
모든 subject 이미지가 정면임에도 불구하고, 그럴듯한 3D 결과물 생성
4.3. Limitations#

Fig. 741 limitations#
최적화된 3D 표현이 때때로 과도하게 포화되고 매끄럽게 처리되는 경우가 존재
높은 가중치 가이던스를 가진 SDS 기반 최적화에 의해 발생
64×64 픽셀이라는 상대적으로 낮은 이미지 해상도로 제한되어 발생
diffusion 과 NeRF 의 효율성 향상은 더 높은 해상도로 확장할 수 있는 가능성을 제공
Janus problem : 최적화된 3D 표현은 입력 이미지에 시점 변화가 없으면 여러 불일치한 시점에서 정면으로 보이는 viewpoints 불일치 문제가 발생
선글라스와 같은 얇은 객체 구조를 재구성하는 데 어려움이 존재
5. Conclusion#
Subject 중심의 텍스트-3D 생성을 위한 방법인 DreamBooth3D를 제안
Subject 에 대한 소규모 casual 이미지 셋트가 주어지면, (카메라 포즈와 같은 추가 정보 없이) 입력 텍스트 프롬프트에서 제공된 컨텍스트(자고 있는, 점프하는, 빨간 등)를 준수하는 subject 별 3D assets 를 생성
DreamBooth 데이터셋 에 대한 광범위한 실험을 통해 해당 방법이 주어진 subject 와 높은 유사성을 가지면서도 입력 텍스트 프롬프트에 나타난 컨텍스트를 잘 반영하는 현실적인 3D assets 을 생성할 수 있음을 입증
정량적 및 정성적 평가에서 여러 기준 모델보다 우수한 성능을 보임을 확인