Information
Title: Scalable Diffusion Models with Transformers (ICCV 2023)
Reference
Code: facebookresearch/DiT
Project Page : https://www.wpeebles.com/DiT
Author: Junhyoung Lee
Last updated on July. 20, 2024
DiT#
Abstract#
LDM 의 U-Net 백본을 transformer 로 바꾸어 학습을 진행한 diffusion model
Gflops 측정: depth/width 증가 or 입력 토큰 수 증가로 Gflops 가 높게 나타났음 (FID 낮게 유지한 상태)
우수한 scalability 특성을 보유하며, \(\text{DiT-XL/2}\) 모델은 class conditional ImageNet 벤치마크에서 이전의 생성 모델에 비해 성능이 뛰어났음 (FID 2.27)
1. Introduction#
Diffusion 모델이 이미지 생성 모델의 트렌드를 유지하고 있지만, convolution 네트워크인 U-Net 모델 사용
transformers 는 autoregressive 모델에서 사용되고 있었음
초기에는 픽셀 레벨의 autoregressive model과 conditional GAN에서 U-Net 이 성공을 이끌었음
DDPM 에서는 ResNet 블럭이 주요하게 구성됨
반면, transformer 에서는 spatial self-attention 블럭이 구성되어 있고, 저해상도에 포함됨
ADM
classifier-guidance diffusion model
adaptive normalization layer 와 같은 U-Net 에서 선택적으로 제거
저자들은 diffusion 모델의 아키텍처 구성의 중요성을 밝혔음
U-Net 의 inductive bias 가 diffusion 모델의 성능의 영향을 끼치지 않고, transformer 로 쉽게 대체 가능함
transformer 를 기반으로 새로운 종류의 diffusion model 을 제안 → Diffusion Transformer (DiT)
DiT는 ViT를 준수하며, 기존 convolution 네트워크보다 시각적 인식(visual recognition)을 위해 더 효과적으로 확장되는 것으로 나타남
3. Diffusion Transformers#
3.2. Diffusion Transformer Design Space#
scaling 속성을 유지하기 위해 standard transformer 구조를 따르도록 설계
이미지(spatial representations)의 DDPM을 학습하기 때문에, 패치를 연산하는 ViT 구조로 설계됨
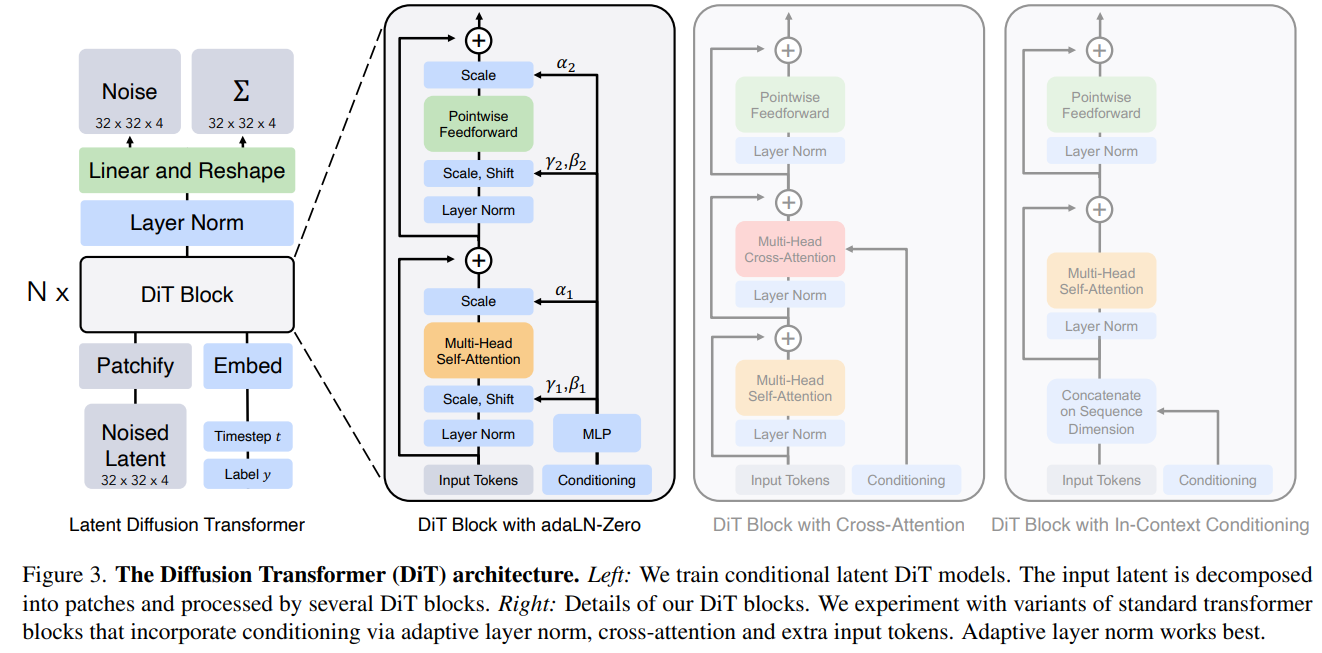
Fig. 529 architecture#
Patchify#
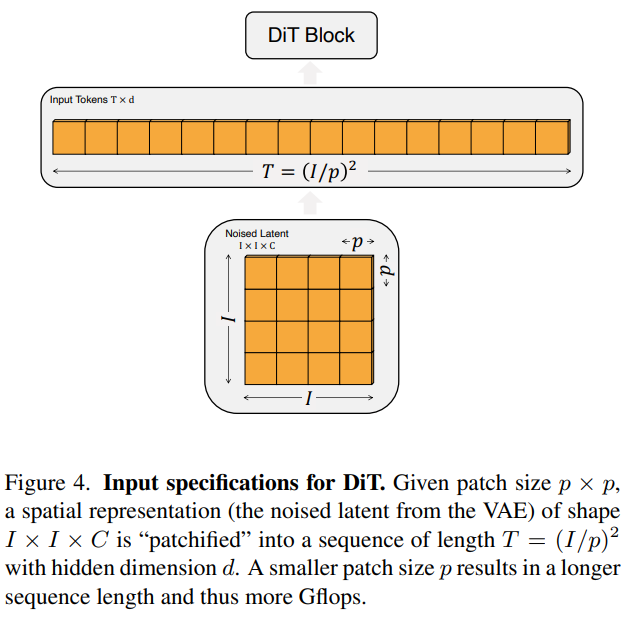
Fig. 530 fig4#
DiT 에 spatial representation \(z\) (256x256x3 이미지에서는 \(z\) 는 32x32x4 로 표현) 가 입력됨
“patchify” : \(z\) → \(d\) 차원의 \(T\) tokens 로 변환 + positional embedding
\(p\) 에 따라 토큰 수가 달라짐 (\(p\) = 2, 4, 8)
\(p\) 를 반으로 줄이면 \(T\) 가 4배가 되므로 총 transformer Gflops 는 최소 4배가 되어 상당한 영향을 끼침
DiT block design#
Diffusion 모델은 보통 noised image 입력과 noise timestep \(t\), class label \(c\) 의 벡터 임베딩 값을 conditional 정보로 입력 시퀀스에 더해줌
다른 conditional inputs 으로 처리하는 4개의 transformer block을 진행함
In-context conditioning
\(t\), \(c\) 를 추가의 토큰으로 더하는 방식 → 이미지 토큰과 동일하게 처리함
ViT 의 \(\text {cls}\) 토큰과 유사한 방식
마지막 블럭에서는 conditioning 토큰을 제거함
Cross-attention block
이미지 토큰과 별도로 \(t\), \(c\) 를 concat 함
self-attention 다음에 cross attention 을 포함하도록 구조를 수정함
cross-attention 연산이 15% 오버헤드로 모델에 가장 많은 Gflops를 추가함
Adaptive layer norm (adaLN) block
Transformer 블럭의 standard layer norm layer 를 adaptive layer norm (adaLN) 으로 교체함
직접 scale \(\gamma\), shift \(\beta\) 파라미터를 학습하는 것보다, \(t\) 와 \(c\) 벡터 임베딩 값의 합으로부터 회귀하도록 설계함
최소한의 Gflops 를 추가하므로 연산에 효율적임
모든 토큰에 대해 같은 function을 적용함으로써 conditioning 하는 방법
adaLN-Zero block
ResNet: 각 residual block 의 initializing 이 identity function 이 효과적이라는 것을 증명함
각 블럭의 마지막 batch norm scale factor \(r\) 를 0으로 초기화 하는 것이 large-scale 학습에 좋다는 것을 발견함
Diffusion U-Net 모델은 비슷한 초기화 전략을 사용하는데, residual connection 전에 각 블럭의 최종 convolutional layer 를 0으로 초기화함
\(\gamma, \beta\) 를 회귀하는 것 외에도 DiT 블럭 내의 residual connection 전에 적용되는 dimension 별 scaling \(\alpha\) 를 회귀함
모든 \(\alpha\) 에 대해 영벡터를 출력하도록 MLP를 초기화함 → 전체 DiT 블록을 identity function 으로 초기화하게됨
adaLN 블록과 비슷하게 adaLN-Zero 는 Gflops 에 영향을 끼치지 않음
Transformer decoder#
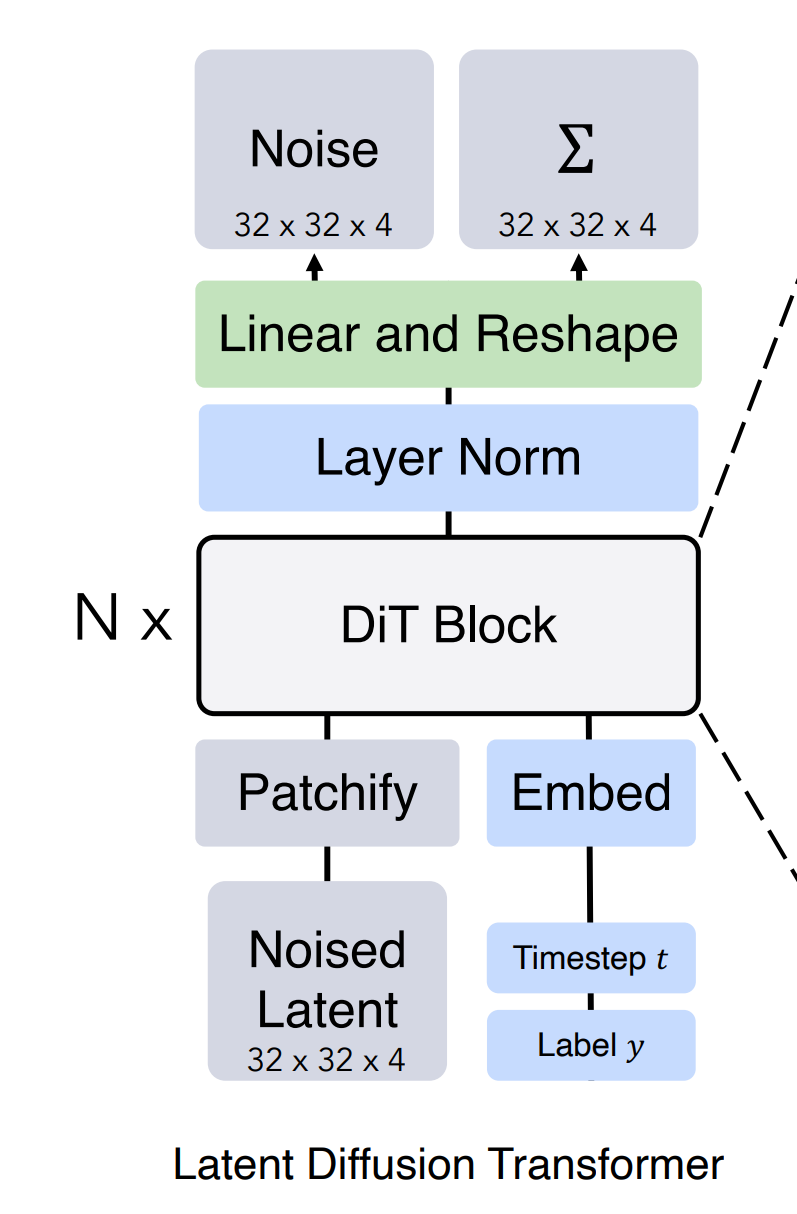
Fig. 531 architecture2#
최종 DiT 블록을 통과한 후, 이미지 토큰 시퀀스를 예측된 noise 값과 covariance 값 디코딩해야함
\(\text{LayerNorm}\) (adaLN을 사용하는 경우 adaLN)
\(\text{Linear, Reshape}\)
\(\text{VAE}\) decoder → “output shape = input image shape”
Q) covariance 값은 왜 예측하는지?
ADM 학습과 연관됨
Noise 차이 loss 이외의 분산도 학습을 진행했음 → vlb_loss 활용
4. Experimental Setup#
DiT models
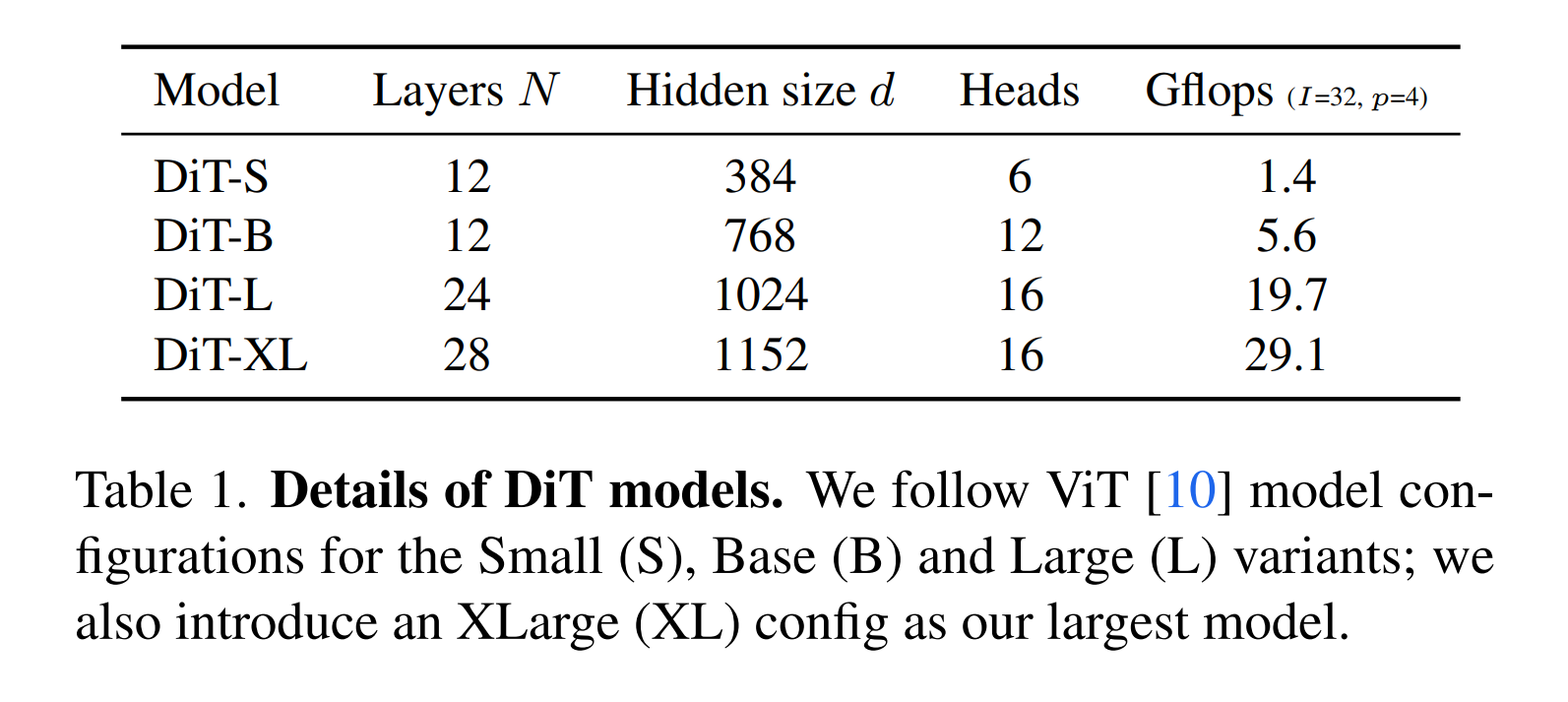
Fig. 532 table1#
Training setting#
\(\text {DiT-XL/2}\): \(\text{XLarge}\) config and \(p = 2\).
class-conditional latent DiT models
해상도: 256x256, 512x512
데이터 셋: ImageNet
마지막 linear layer 는 0으로 초기화, 나머지는 standard weight 초기화
Optimizer: AdamW
Learning rate: \(1 × 10^{−4}\)
Batch size: 256
Augmentation: horizontal flip
exponential moving average (EMA): 0.999
Diffusion: Stable Diffusion 의 VAE 사용
Evaluation#
Class-conditional image genertation model 비교#
Fig. 533 table2#
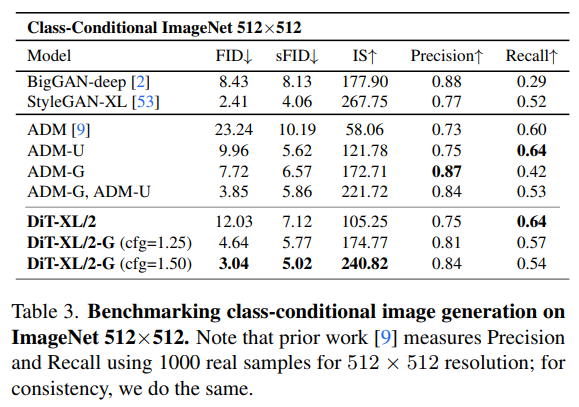
Fig. 534 table3#
ADM, LDM 보다 DiT-XL 모델이 FID, IS 점수가 좋음
DiT block design#
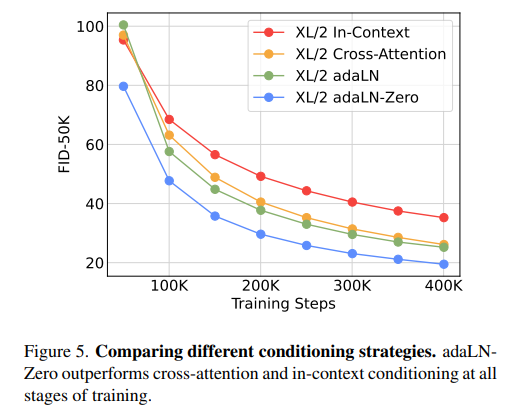
Fig. 535 fig5#
adaLN-Zero 구조가 적은 학습에도 FID 점수가 좋음
Scaling model size and patch size#
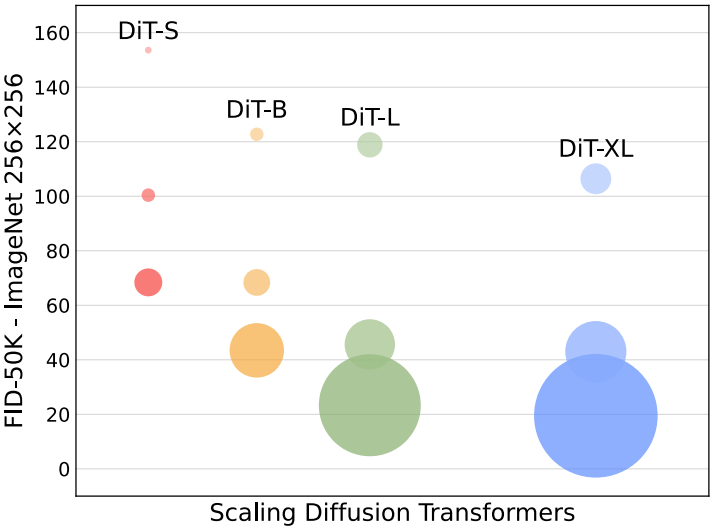
Fig. 536 fig6#
모델이 클수록 FID 점수가 좋음
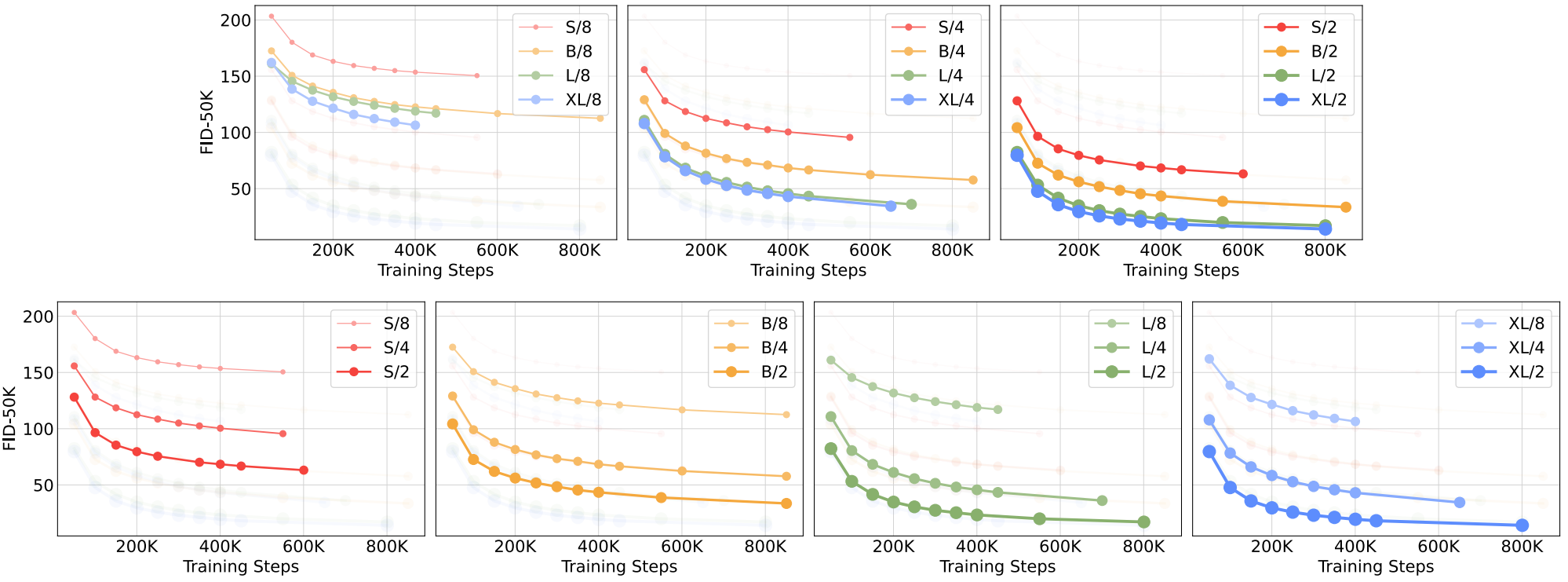
Fig. 537 fig7#
DiT Gflops are critical to improving performance#
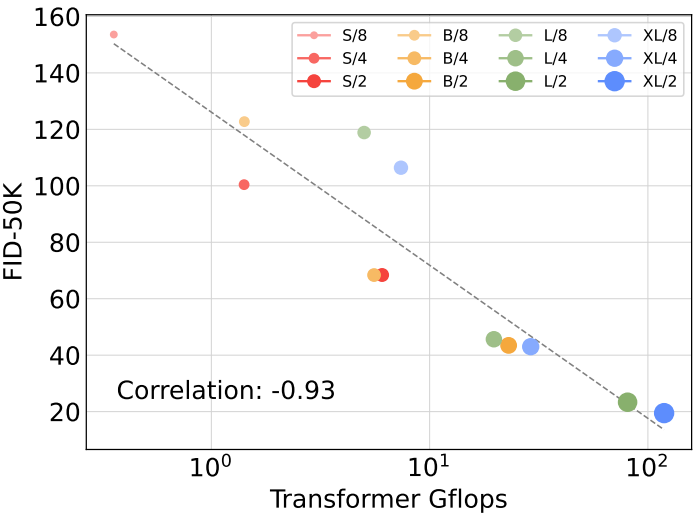
Fig. 538 fig8#
Transformer Gflops 가 클수록 FID 점수가 좋음
Larger DiT models are more compute-efficient#
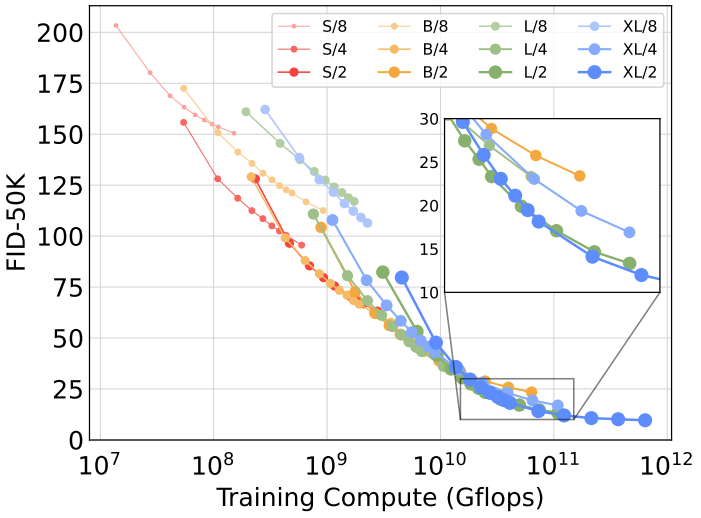
Fig. 539 fig9#
학습할 때의 Gflops 가 높을 수록 FID 점수가 좋음
Visualizing scaling#

Fig. 540 visual_result#
패치 사이즈와 transformer 크기에 따른 생성 결과 확인
패치가 작을수록, 모델 크기가 클수록 생성 결과가 좋음
Conclusion#
Diffusion Transformers 는 간단한 transformer 기반 diffusion 모델
이전 U-Net 모델보다 성능이 뛰어나고, transformer 모델의 scaling 특성을 우수하게 적용함
adaLN 을 통해 연산의 효율성도 가져옴