Information
Title: Zero-shot text-to-image generation (ICML 2021)
Reference
Code: Unofficial-PyTorch
Code: Official
Author: Donggeun “Sean” Ko
Last updated on June 22 2023
DALL-E#
1. Introduction#
GPT-3 기반 모델이며 120억개 parameter 수와 2.5억 데이터 (text,image) set으로 학습
Autoregressive 한 모델링을 통하여 image와 text를 이용하여 text-to-image generation task를 수행
2021년 기준 zero-shot SOTA performance 달성
아래 그림과 같이 text input에 따라 diverse한 이미지 생성

Fig. 86 Images generated using DALL-E#

Fig. 87 Images generated using DALL-E#
2. Background#
GPT-3와 VQ-VAE를 활용하여 나온 논문.
VQ-VAE를 먼저 학습하고, Autoregressive Transformer을 순차적으로 학습하여 zero-shot architecture을 구축.
GPT-3#
Autoregressive Language Model며 few-shot learning을 통해 fine-tuning 없이 높은 성능을 냄 *(fine-tuning 을 할 수는 있지만 본 논문에서는 task-agnostic performance 에 중점을 맞춰 Few shot을 함)
GPT-3 는 transformer에서 decoder 부분만 사용 (GPT-2 와 유사한 구조를 가지고 있음 )
약 1750억 parameter 개수의 모델
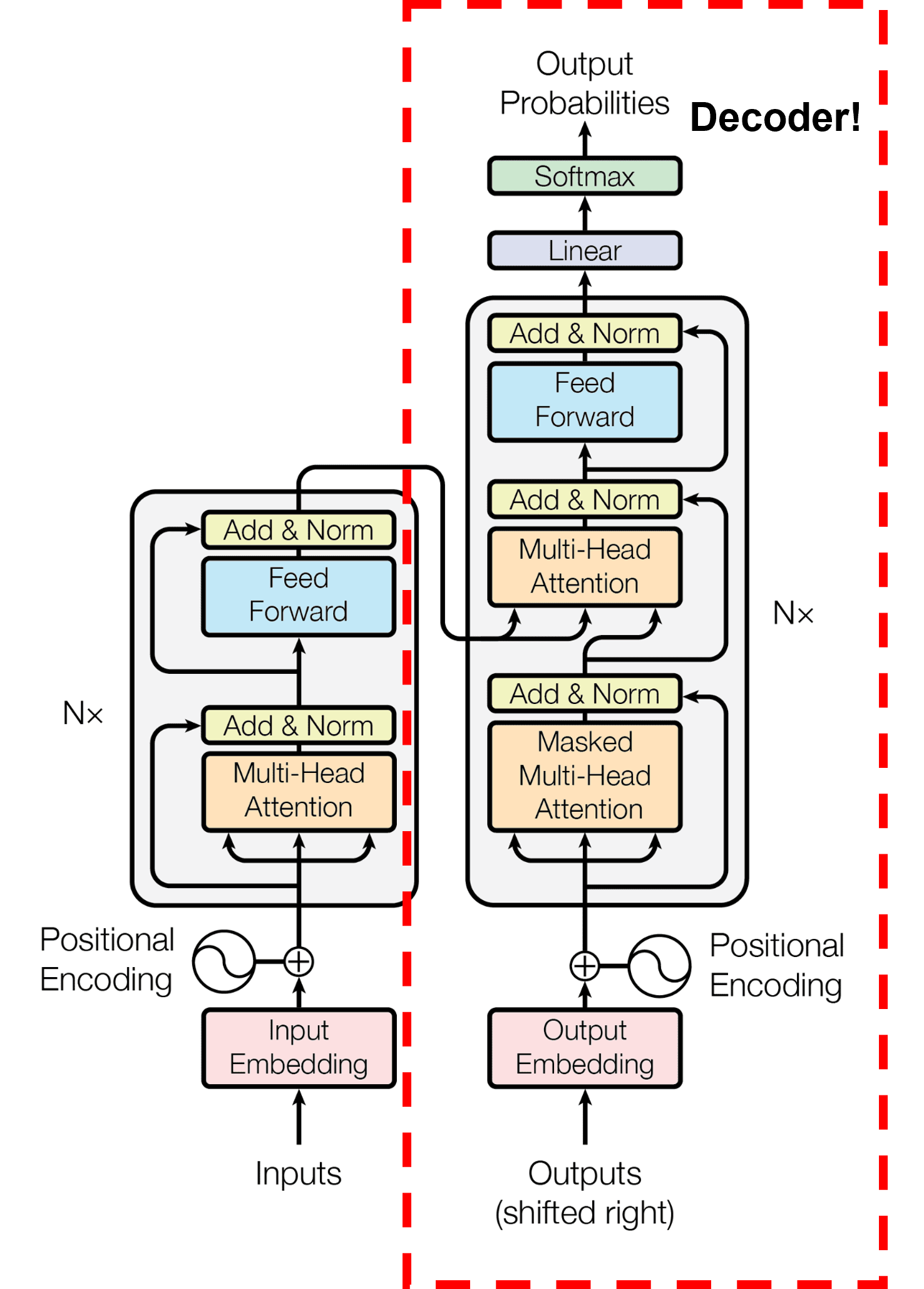
Fig. 88 Transformer 아키텍쳐 \ (source: https://arxiv.org/pdf/2005.14165.pdf)#
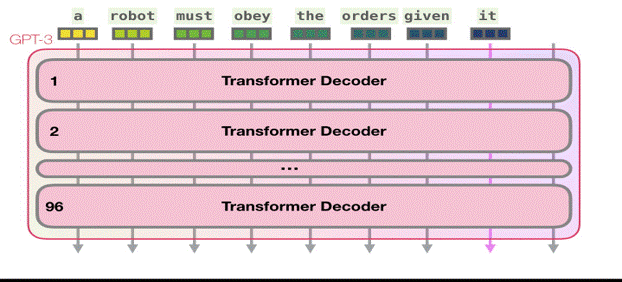
Fig. 89 GPT 3 Animation \ (source: https://jalammar.github.io/how-gpt3-works-visualizations-animations/)#
VQ-VAE#
Encoder에서 나온 output은 discrete 하며 posterior 과 prior 이 categorical distribution을 갖는다고 가정함.
CNN (encoder) 을 거친 각 D차원의 위치에 \(H \times W\) 그리드로 이미지를 나누고 embedding space (Codebook) 에서 \(𝑒_1\)부터 \(𝑒_𝑘\) 중에서 가까운 1개 embedding code로 변환.
Quantization: Encoding output \(z_{e}(x)\) representation 과 유사한 codebook embedding \(e_j\) 를 찾아서 \(k\) 값을 부여함.
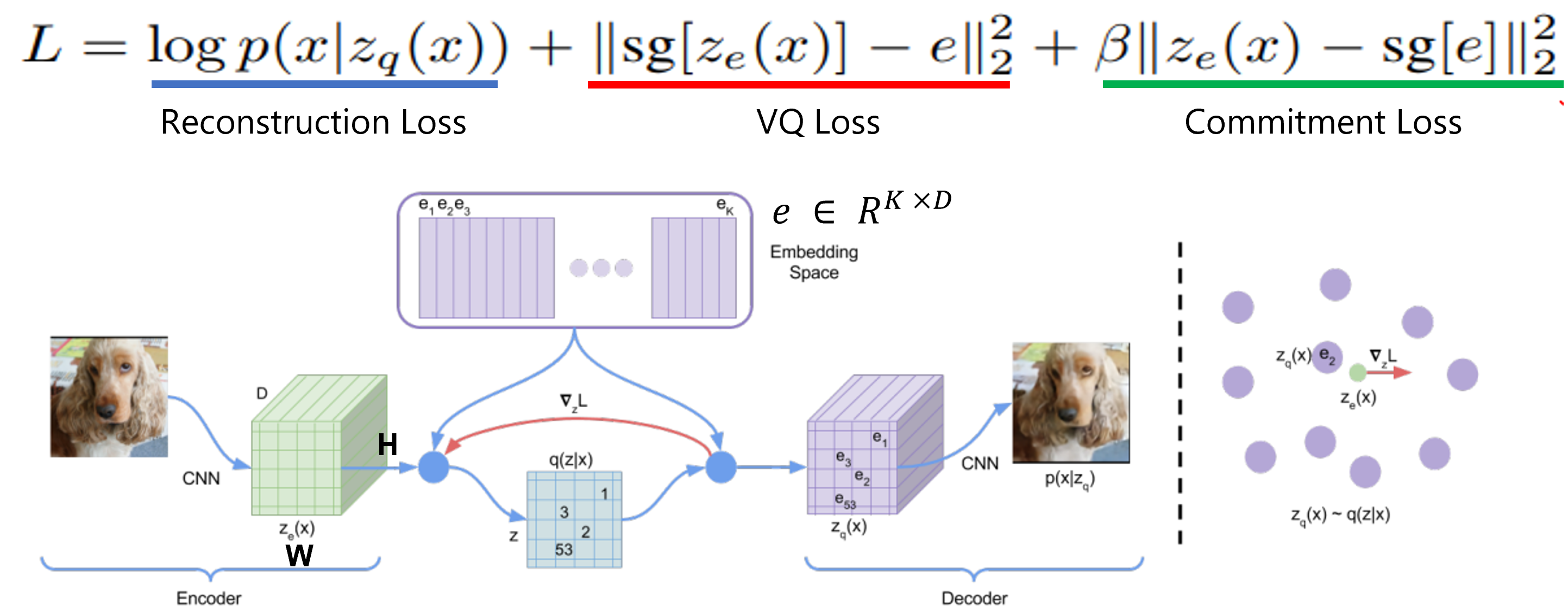
Fig. 90 VQ-VAE 아키텍쳐, Loss 함수 \ (source: https://velog.io/@p2yeong/Understanding-VQ-VAE-DALL-E-Explained-Pt.-1)#
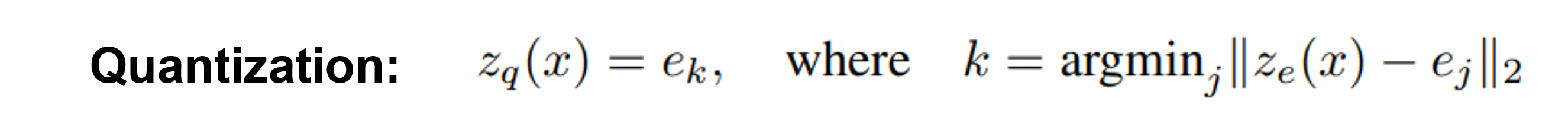
Fig. 91 Quantization of VQ-VAE#
3. Methodology#
Limitation of Previous Works#
Memory/Bottleneck Issue
각 Image에서 나오는 pixel을 직접적으로 image token을 사용하면 고화질 이미지일수록 너무 많은 메모리량이 필요해서 “비효율적”
Short-range dependence modeling between pixels
Model들 중 Likelihood function을 objective function으로 사용하면 short-range dependency를 우선적으로 볼 것이며 low-frequency 보다 high-frequency detail에 더욱 집중하게 됨.
Low frequency 는 visually recognizable해서 시각적으로 더 도움이 되는 부분
이 2가지 문제점을 극복하고자 Two-stage training process 제안
DALL-E Overview#
Stage 1: Training VQ-VAE#
Discrete VAE를 이용하여 \(256 \times 256\) RGB image \rightarrow \(32 \times 32\) 이미지 토큰으로 압축
각 이미지 토큰은 8,192개의 code 값 중에 하나 배정
이미지의 quality 손실 없이 \(8 \times 8 \times 3\) 배 만큼 context size를 적게 만들 수 있음.
Stage 2: Training an Autoregressive Transformer#
최대 256 BPE-Encoded text tokens들과 1024 image tokens (\(32 \times 32\)) 를 연속적으로 입력함 (concatenate)
Text token과 Image Tokens 들의 joint distribution (결합 분포)를 모델링하여 autoregressive transformer을 학습
DALL-E Pipeline 예시#

Fig. 92 DALL-E 시각화 \ (source:https://jiho-ml.com/weekly-nlp-40/)#
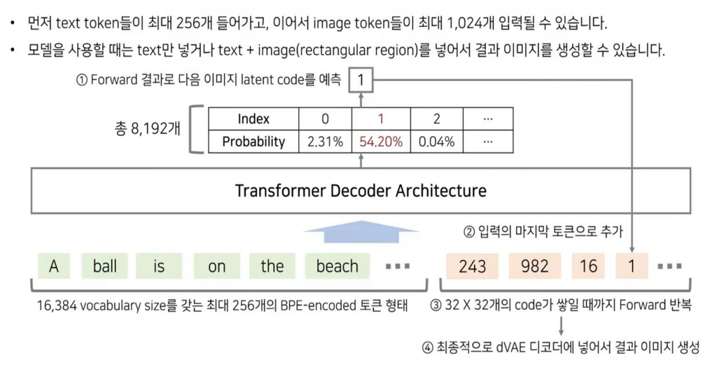
Fig. 93 DALL-E 파이프라인 \ (source:https://www.youtube.com/watch?v=CQoM0r2kMvI&t=1729s)#
Methodology Details#
DALL-E Equations#
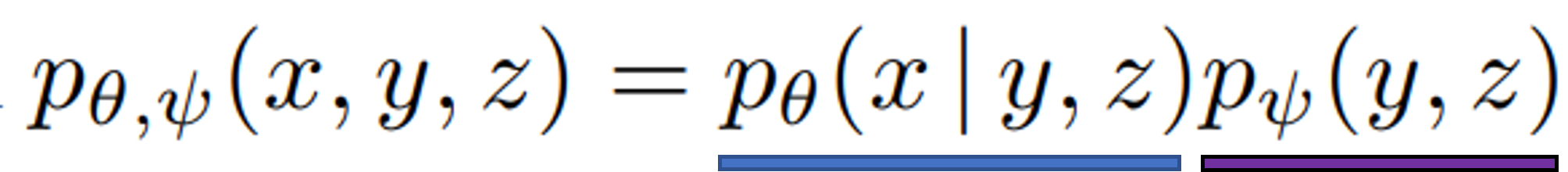
Fig. 94 equation 1#
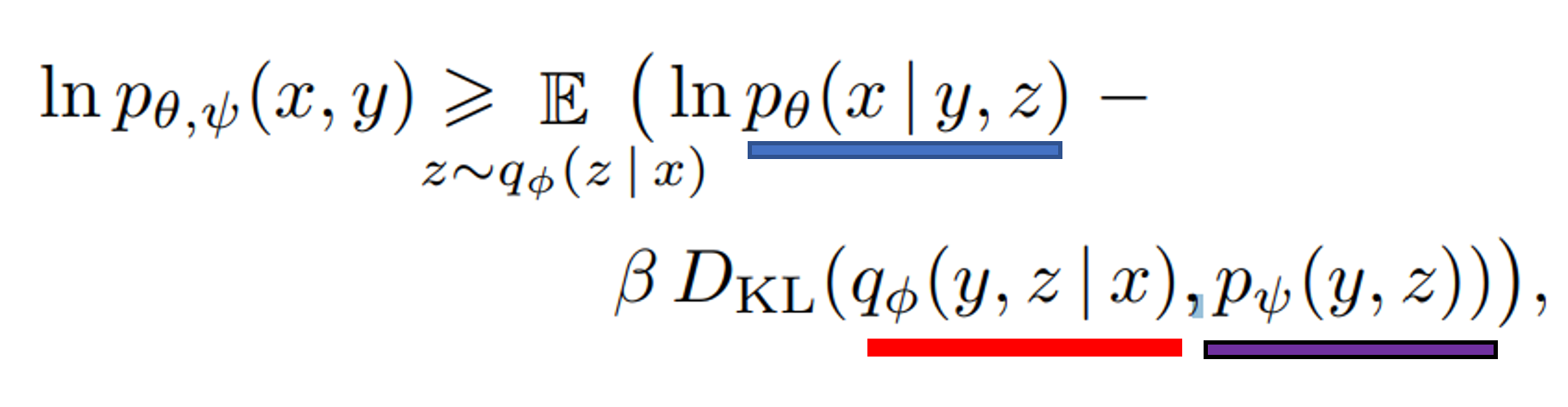
Fig. 95 equation 2: Maximizing ELBO#
x: images, y: captions , z: encoded RGB image tokens
𝑞Φ (red) : input image에서 dVAE encoder에서 생성한 32 x 32 image token를 예측
𝑝𝜃 (blue): image token에서 dVAE decoder에서 생성한 RGB image를 예측
𝑝ψ (purple): transformer 모델로 모델링한 text와 image token들의 결합 분포 (joint distribution)
DALL-E 학습과정 Stage 1: Learning the VIsual Codebook#
Transformer을 고정하고 dVAE encoder & decoder (𝑞_Φ , 𝑝_𝜃) 을 학습함
즉, ELB (Evidence Lower Bound를 maximize 함)
K = 8,192 codebook (embedding space)로 설정
ELB를 optimize 하기 위해서는 discrete distribution을 continuous를 바꿔야 함
학습시에는 결국, argmax를 사용해서 codebook vector 인덱스를 선택하여 계산하면 Reparameterization gradient를 연산 X
argmax 대신 gumbel softmax를 사용하여 해결
평가를 진행할 때에는 \(z = codebook[\underset{i}{argmax}[g_i+log(q(e_i|x))]]\)
Gumbel Softmax Relaxation를 사용하여 해결! \(q_\phi \rightarrow q_{\phi}^{\tau}\), temperature \(\tau \rightarrow 0\), relaxation을 tight하게 잡아줌.
DALL-E 학습과정 Stage 2: Learning the Prior#
Transformer을 고정하고 dVAE encoder & decoder (\(q_{phi}\) , \(p_{\theta}\)) transformer의 prior distribution \(p_{\psi}\)를 학습함.
이때, \(p_{\psi}\)의 ELB를 maximize 하며 120억개의 parameter를 가진 sparse transformer 구조를 사용함
Image token은 dVAE Encoder logit에서 Argmax sampling을 통해 생성
Text token은 소문자화 후 16,384 개의 vocabulary를 BPE-encoding 통해 한번에 최대 256 token을 활용

Fig. 96 Text-to-text attention: causal attention mask Image-to-image attention: row/column/convolutional attention mask 적용#
Results#
추론 시에는 text에 대하여 N개의 이미지를 생성.
Best of N개는 N개 생성 후 best를 골라서 선택 함.
우수한 이미지를 고르기 위해 CLIP (Contrastive Language-Image Pretraining, 2021) 논문에서 제시한 text 와 k 번째로 similarity 점수가 높은 이미지를 선택함 (k=1)

Fig. 97 DALL-E 결과물. Best를 고를때 N 수가 증가할수록 주어진 text prompt랑 더 유사한 결과물이 나옴.#
생성한 512개 이미지 중 CLIP 알고리즘을 통해 similarity score이 제일 높은 이미지를 뽑음.
Ours (DALL-E) vs 다른 baseline method 와 비교 시 text에 더욱 알맞은 이미지를 생성한 것을 확인 할 수 있음.

Fig. 98 선택하는 이미지 개수에 따른 성능 향상#
DF-GAN 이랑 비교해서 MS-COCO dataset에 대하여 정성적 평가를 진행.
Best-of-Five votes 중에 DF-GAN보다 매번 압도적인 차이로 투표 수를 받았음.
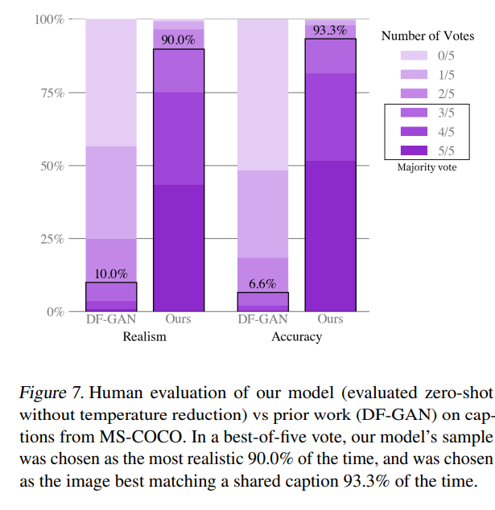
Fig. 99 DF-GAN 이랑 Qualitative Results 비교#
FID (Frechet Inception Distance)는 값이 낮을수록 좋으며 / IS (Inception Score)는 높을수록 좋음
MS-COCO 랑 CUB (새 특화 데이터셋) 기준, DALL-E는 MS-COCO에서는 뛰어난 성능을 보여줬음.
CUB에서는 SOTA를 찍지 못하였고 Inception score에서는 낮은 점수를 기록함.
저자들은 Fine-tuning 으로 CUB에 성능 계선을 할 수 있다고 생각함.
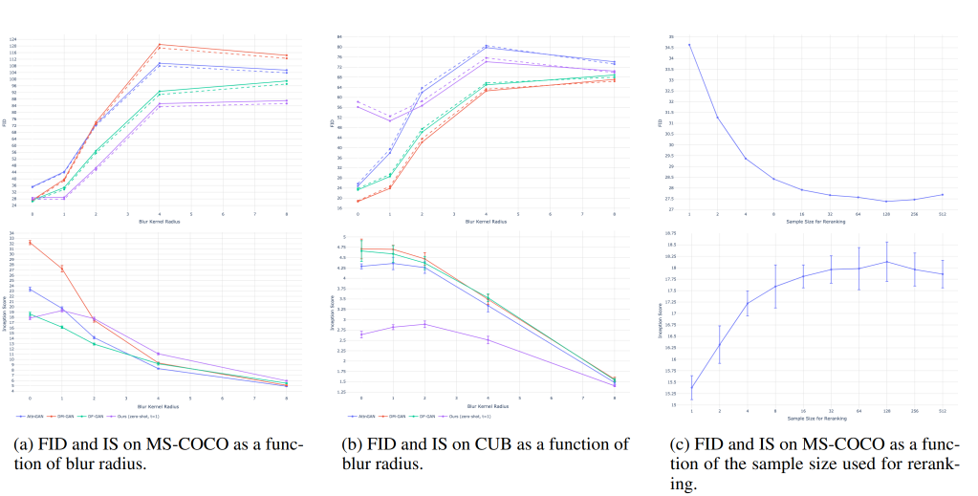
Fig. 100 MS-COCO 와 CUB dataset에서 FID/IS 결과값 비교#
Conclusion#
GPT-3의 확장 모델로 120억개의 parameter과 autoregressive Transformer (Decoder only) 기반 모델링을 통해 text-to-image generation task를 뛰어나게 해결함.
Zero-shot learning에서 다른 모델보다 훌륭한 일반화 성능을 보임
정량적 / 정성적 평가에서 준수한 성능을 보이고 있으며 다양한 이미지 생성이 가능함.
** Limitations: **
생성하고 싶은 이미지에 다양한 객체가 포함되면 어려움을 겪음
(b)에 보면 고슴도치가 2마리거나 강아지와 고슴도치 둘다 크리스마스 스웨터를 입고 있음.
CUB dataset 처럼 다소 아쉬운 성능을 보인 데이터셋이 있지만 fine-tuning으로 해결

Fig. 101 Limitation을 보여주는 결과물.#