Information
Title: StyO: Stylize Your Face in Only One-Shot
Reference
Author: Seunghwan Ji
Last updated on Aug. 6, 2023
StyO#
Abstract#
“Stylize the face in only One-shot.”
한장의 이미지만으로 다른 이미지로 스타일을 Transfer!
1. Introduction#
현재 다양한 분야에서 이미지에 특정 스타일을 입히고자하는 연구들이 활발히 진행중이다.
이전까지의 연구들은 대부분 각각의 source 이미지, target 이미지 한장씩을 사용해 GAN based model을 활용하려는 식이 주를 이루었다.
단 이러한 방식에는 한계가 있는데,
Real Face를 학습한 pre-trained GAN 모델의 의존도가 너무 커서 Style을 입히기 힘들다.
latent space안에서 Content 정보와 Style 정보가 Entangle 되어있다.
StyO는?
GAN 대신 Data의 Distribution을 더 잘 포용하는 Latent Diffusion Model을 Base모델로 채용한다.
총 2 Stage로 구성되는데
Identifier Disentanglement Learner(IDL)
이미지의 content 정보와 Style 정보를 분리
Fine-grained Content Controller(FCC)
IDL로부터 분리된 Content와 Style을 원하는대로 재조합
추가로 src 이미지의 detail한 정보(head-pose, hair color 등)를 유지하기위해 Generate 과정에서 src 이미지의 attention map을 재사용하는 trick을 제안했다.
이러한 StyO는 GAN based 모델에 비해 더 좋은 퀄리티의 이미지를 생성해내고, one-shot face stylization 분야에서 SOTA를 기록했다.
3. Method#
3.2. Framework of StyO#
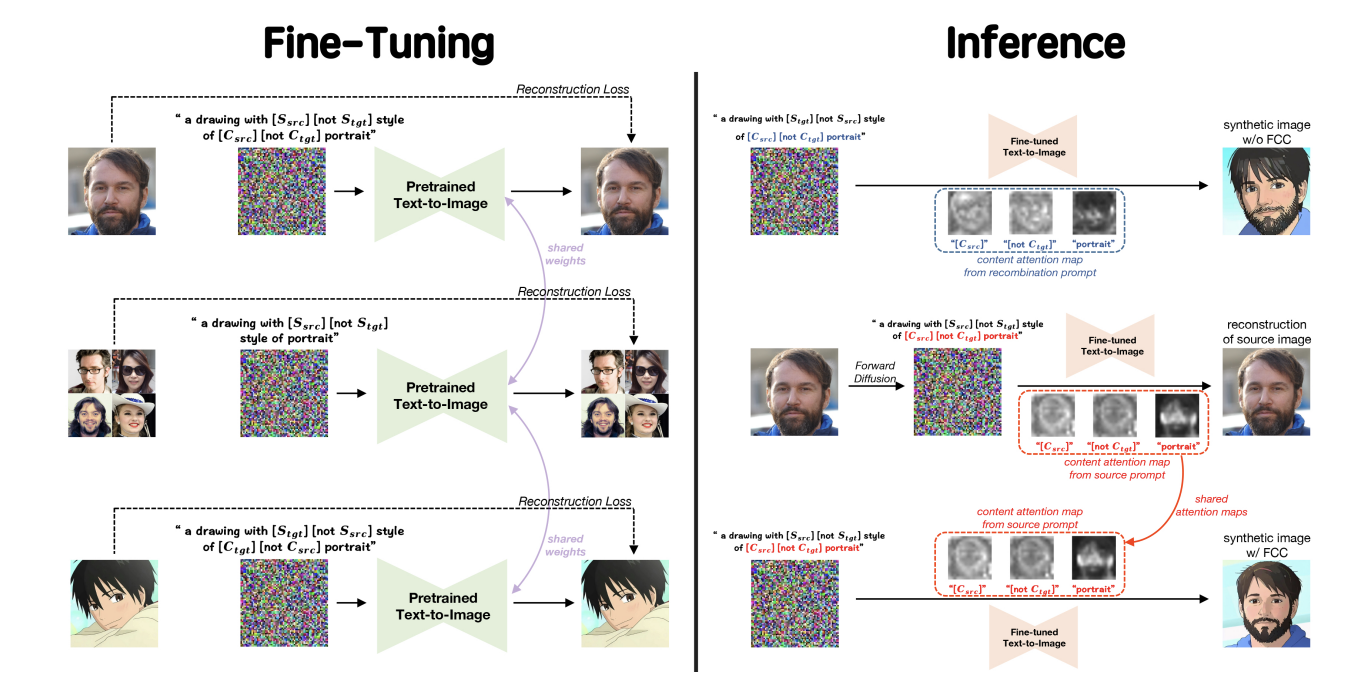
Fig. 203 Figure 1#
image 간의 style transfer를 위해 identifier disentaglement learner과 fine-grained content controller를 제안한다.
IDL
image의 content 정보와 style 정보를 분리하는 방향으로 학습이 진행
src 이미지는
"a drawing with $S_{src}$ not $S_{tgt}$ style of $C_{src}$ not $C_{tgt}$ portrait"prompt로 학습 (tgt 이미지는 반대)
⇒ 이미지 간의 Style 정보와 Content 정보가 Disentangle 되고, \(S_{src}\)안에 이미지 A의 Style 정보가, \(C_{tgt}\) 안에 src 이미지의 content 정보가 embedding 되도록 학습
이 때 \(S_{src}\), \(C_{src}\)에 target 이미지의 conext 정보를 배제함과 동시에\(S_{tgt}\), \(C_{tgt}\)에 포함하기위해 앞에 negator(=부정의 의미를 가진 단어)를 사용
e.g. not, without, except …
src, tgt 이미지에 추가로 auxiliary 이미지 셋을 구성해
“a drawing with $S_{src}$ not $S_{tgt}$ style of portrait”prompt로 학습\(X_{aux}\) : FFHQ dataset에서 임의로 200장의 데이터를 sampling
효과
auxiliary 이미지를 학습함으로써 key prompt간 disentanglement를 향상
auxiliary 이미지에는 없는 src 이미지만의 정보를 \(C_{src}\) 에 주입
src 이미지의 style과 tgt 이미지의 style을 구별하는데 도움을 줌
Full Loss
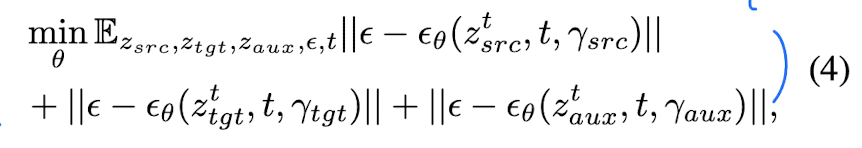
Fig. 204 Equation 1#
이러한 IDL의 학습만으로 src 이미지와 tgt 이미지의 style transfer가 가능하다.
“a drawing with $S_{tgt}$ not $S_{src}$ style of $C_{src}$ not $C_{tgt}$ portrait”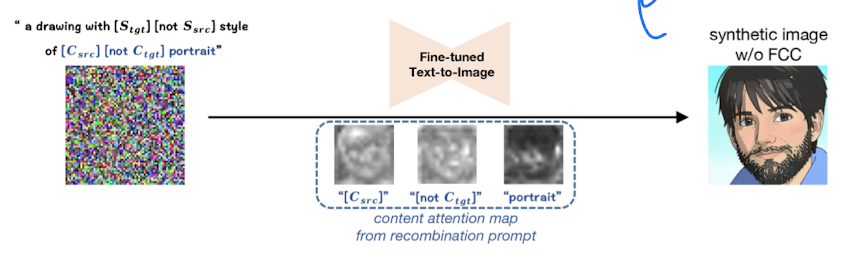
Fig. 205 Figure 2#
하지만 위 이미지처럼 src 이미지의 content 정보(head-pose, facial feature)를 잃어버리는 경향이 있다.
이러한 문제점을 개선하기위해 FCC를 추가로 도입하였다.
FCC
IDL로 분리된 content 정보와 style 정보를 원하는 방식으로 조합(Recombination)할 때 A의 Content 정보를 유지하도록 하는 Trick
Cross Attention Control
LDM은 기본적으로 Text 정보를 생성 이미지에 주입하기위해 cross attention mechanism을 사용
\(Attn(z, r) = M(z, r)V\), z : image latent, r : text embedding
이 때 “prompt-to-promt” paper에서 attention map M의 값이 생성 이미지의 Layout에 강한 영향을 미친다는 점을 확인
따라서 src 이미지의 attention mask를 generate 과정에 주입합으로써 content 정보를 좀 더 잘 유지하도록 유도
단, attention map의 모든 값을 replace하지않고, content에 관한 Index만 선택적으로 replace
content index : ‘\(C_{src}\)
,not,\(C_{tgt}\),portrait`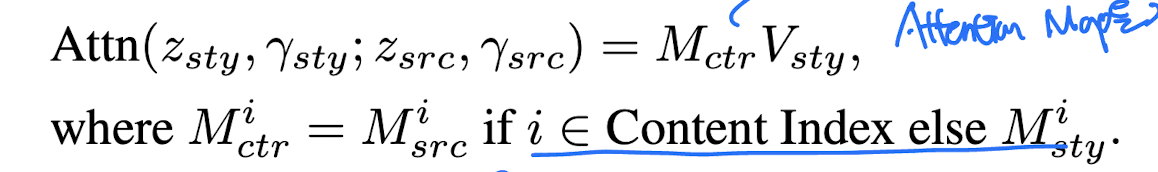
Fig. 206 Equation 3#
Augmented Text Prompt
training time에서 key prompt를 n번 사용함으로서 생성되는 이미지에 context 정보를 강하게 주입
src 이미지는
“a drawing with ($S_{src}$ not $S_{tgt}$) * $n_{s}$ style of ($C_{src}$ not $C_{tgt}$) * $n_{c}$ portrait”(tgt 이미지는 반대)
실험상 hyperparameter \(n_{s}\)와 \(n_{c}\)는 3 이하의 값을 추천
4. Experiments#
Implementation Details
base model : Pretrained LDM model checkpoint (trained by LAION-5B)
hyper parameter
key prompt : “ak47”, “aug”, “sks”, m4a1”
Learning rate : 1e-6
Optimizer : Adam
train step : 400
\(n_{s}\) : 3, \(n_{c}\) : 1
나머지는 LDM과 동일
Comparison with SOTA methods

Fig. 207 Figure 3#
StyO가 src 이미지의 face identity와 local detail 모두 잘 유지함과 동시에, style 정보를 자연스럽게 입힌 결과물을 생성해낸다.
User Study도 다른 모델들에 비해 좋은 결과를 보였다.
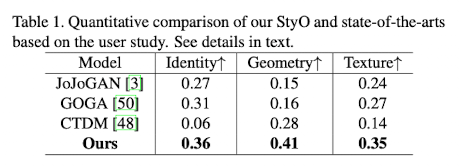
Fig. 208 Table 1#
Ablation Study
Effect of Contrastive Disentangled Prompt Template
negative prompt 없이 positive prompt만 넣고 학습할경우 학습 이미지의 overfitting이 심하고, style과 content 정보의 분리에 어려움을 보인다.

Fig. 209 Figure 4#
또, source 이미지의 local detail을 유지하기위해 auxiliary set의 trick도 적용하는것이 Best Quality의 결과물을 생성해냈다.
Effect of Fine-grained Content Controller
FCC 없이 Inference할 경우 generated 이미지의 높은 diversity를 보이지만, FCC를 포함할 경우 src 이미지의 fidelity가 높아져 좀더 significant한 이미지가 생성되는것을 보여주었다.

Fig. 210 Figure 5#
Hyper-parameters in Augmented Text Prompt
\(n_{s}\) 값이 커질수록 이미지가 photorealistic에서 artistic하게 바뀌고, \(n_{c}\)도 마찬가지로 값이 커질수록 src 이미지에 overfitting된 이미지가 나오는 경향을 보여주었다.
5. Conclusion#
StyO는 IDL과 FCC를 사용해 기존 GAN을 이용한 SOTA 모델들보다 더 자연스럽고 Quality 좋은 style transfered 이미지를 생성해낼 수 있었다.
단, style 하나의 transfer를 위해 single GPU로 10분이 걸리므로 time-efficiency가 좋지 못하다는 단점이 있다.