Information
Title: Magic3D: High-Resolution Text-to-3D Content Creation (CVPR 2023)
Reference
Author: Sangwoo Jo
Last updated on Sep. 24, 2024
Magic3D#
1. Introduction#
Pre-trained 된 text-to-image diffusion model 을 활용하여 NeRF 를 optimize 하는 DreamFusion 모델의 두 가지 단점을 명시합니다.
Extremely slow optimization of NeRF
Low-resolution image (64x64) space supervision on NeRF, leading to low-quality 3D models with a long processing time (1.5 hours per prompt on average using TPUv4)
따라서, 논문에서는 이러한 단점을 해결하기 위해 two-stage optimization framework 제시합니다. 첫번째 단계로 DreamFusion 과 동일하게 coarse 한 NeRF representation 을 optimize 하는데, hash grid 를 활용하여 memory 그리고 computationally efficient 하게 최적화합니다. 두번째 단계로 high resolution diffusion prior 를 기반으로 mesh representation 를 최적화합니다. 3D mesh 로 rasterizing 함으로써 graphics software 에 유동적으로 전환하여 사용할 수 있다는 장점이 있습니다.
정리하자면, Magic3D 는 다음과 같은 contribution 을 제공합니다.
Synthesizes 3D content with an 8× higher resolution supervision, is also 2× faster than DreamFusion
3D object editing
3. Background: DreamFusion#
DreamFusion 을 크게 두 가지 component 로 구성되어있다고 할 수 있습니다.
Neural scene representation
Volumetric renderer \(g\) 와 3D volume 을 나타내는 parameter \(\theta\) 를 입력받아 rendered image 를 생성하는 scene model \(x=g(\theta)\) 를 정의합니다. DreamFusion 에서는 scene model 로 Mip-NeRF 360 에서 shading model 를 추가하여 사용합니다.
Pre-trained text-to-image diffusion-based generative model \(\phi\)
DreamFusion 에서 diffusion model 로 Imagen 모델을 사용합니다.
이를 기반으로, 다음과 같은 Score Distillation Sampling (SDS) 을 통해 parameter \(\theta\) 를 update 합니다.
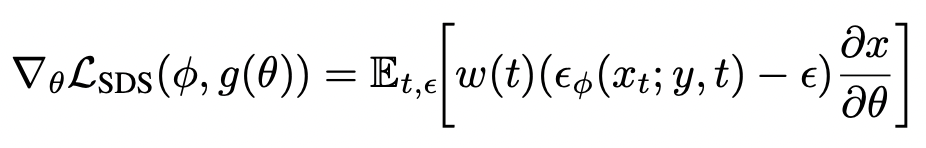
Fig. 723 Score Distillation Sampling#
4. High-Resolution 3D Generation#
Magic3D 에서 high-resolution text-to-3D synthesis 를 위한 two-stage coarse-to-fine framework 를 다음과 같이 소개합니다.
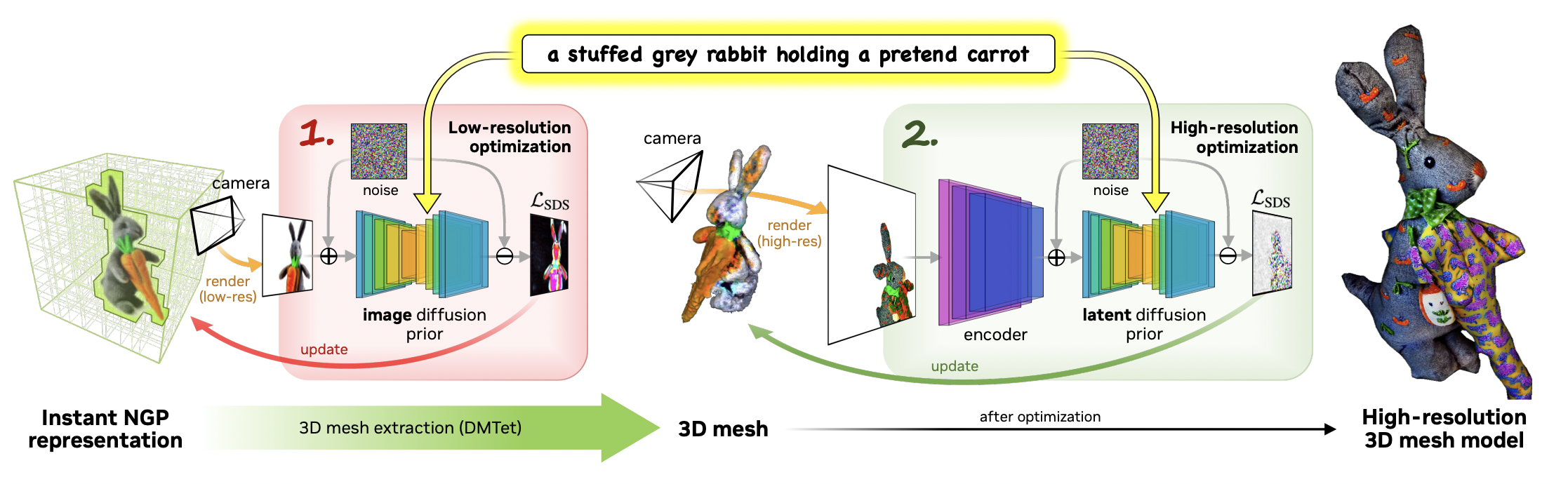
Fig. 724 Magic3D Framework#
4.1. Coarse-to-fine Diffusion Priors#
64x64 rendered image 에 대한 rendered loss 를 계산하기 위해 Imagen 과 유사한 eDiff-I 를 base diffusion 모델로 사용합니다.
512x512 high resolution rendered image 를 기반으로 backpropagation 할 수 있도록 Stable Diffusion model 을 LDM 으로 사용합니다. 다음과 같이 SDS 를 계산하는 과정에서 \(\partial{x}/\partial{\theta}\) 와 \(\partial{z}/\partial{x}\) 를 계산하는데 시간이 다소 소요된다고 합니다.
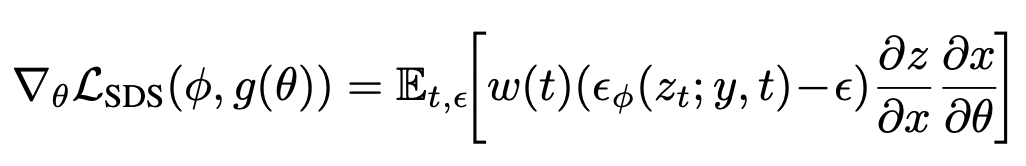
Fig. 725 SDS in high resolution 512x512#
4.2. Scene Models#
Neural fields as coarse scene models
기존에 DreamFusion 에서 scene model 로 사용하였던 Mip-NeRF 360 모델이 3D geometry 에 대한 정보를 scratch 로부터 담아내는데 유용하다는 것을 보였지만, MLP 네트워크를 통해 dense 하게 sampling 하여 rendering 하는 과정이 computation cost 가 높다고 말합니다.
이를 해결하기 위한 방법으로 InstantNGP 에서 소개하는 hash grid encoding 을 사용한다고 합니다. Hash grid 를 활용하여 두 개의 single layer neural network 를 학습하는데, 하나는 albedo 와 density 그리고 나머지 하나는 normal 을 예측합니다. 또한, density-based voxel pruning (empty space 에 대한 처리) 과 octree-based ray sampling/rendering 기법을 활용하여 computation cost 를 줄였다고 합니다.
Textured meshes as fine scene models
Fine stage 에서도 high resolution image 를 기반으로 동일한 scene model (neural field) 을 학습하는 방식도 있지만, 아래 예시처럼 메모리와 연산적인 제한이 있어 좋은 성능을 내기가 어렵다고 합니다.
따라서, Magic3D 에서는 textured 3D mesh 를 scene representation 으로 사용합니다. 더 자세하게는, 다음과 같은 tetrahedral grid \((V_T,T)\) 형태로 3D mesh 를 표현합니다. 이때, \(V_T\) 는 grid \(T\) 에 존재하는 vertices 를 의미하고, 각 vertex \(v_i \in V_T \subset \mathbb{R}^3\) 는 signed distance field (SDF) \(s_i \in \mathbb{R}^3\) 그리고 deformation \(\Delta v_i \in \mathbb{R}^3\) 값을 가집니다.
이로부터 differentiable 한 marching tetrahedra 알고리즘을 통해 SDF 로부터 surface mesh 를 생성할 수 있으며, texture 에 대한 정보는 neural color field 로 정의할 수 있다고 합니다.
4.3. Coarse-to-fine Optimization#
Neural field optimization
Instant NGP 와 동일하게 \(256^3\) resolution 의 occupancy grid 로 initialize 하고, 10 iterations 마다 grid 를 업데이트하며 empty space skipping 을 위한 octree 를 생성합니다. 매 업데이트마다 Instant NGP 와 동일한 파라미터 값을 설정하였다고 합니다.
또한, DreamFusion 과 동일하게 background 를 표현하는 environment map MLP 를 사용하는데, 이때 Mip-NeRF 360 에서 사용하는 scene representation 을 사용할 수 없어, 모델이 background 로부터 object 에 대한 정보를 학습할 수 있어 이를 방지하기 위해 MLP 사이즈를 작게 하고 learning rate 를 10배 증가시켰다고 합니다.
Mesh optimization
Mesh 에 대한 optimization 을 진행하기 위해, 앞서 최적화한 coarse neural field 를 non-zero constant 를 차감함으로써 SDF 로 전환하고, texture field 는 coarse stage 에서 최적화된 color field 로 초기값을 설정합니다.
최적화 단계를 진행할때, differentiable rasterizer 를 사용하여 surface mesh 를 rendering 하는 작업을 진행합니다. 각 vertex \(v_i\) 에 대해 앞서 정의한 high resolution 에서의 SDS gradient 를 통해 \(s_i\) 와 \(\Delta v_i\) 를 최적화하게 됩니다. 이때, rendering 하는 과정에서 각 pixel 에 해당하는 3D coordinate 를 추적하여 texture field 도 동시에 최적화합니다.
5. Experiments#
DreamFusion 과 397 개의 text prompt 에 대한 성능을 비교합니다.
Speed evaluation
Coarse stage : 5000 iterations / 1024 samples / batch size 32 와 같은 설정으로 학습하였고, 하나의 객체를 생성하는데 8 NVIDIA A100 GPU 기준 15 분 소요된다고 합니다.
Fine stage : 3000 iterations / batch size 32 와 같은 설정으로 학습하였고, 하나의 객체를 생성하는데 8 NVIDIA A100 GPU 기준 25 분 소요된다고 합니다.
Qualitative comparisons
3D 객체에서의 geometry 와 texture 에 대한 생성을 잘하는 부분을 확인할 수 있습니다.

Fig. 726 Qualitative comparisons#
User studies
397 개의 text prompt 을 입력받아 생성한 Magic3D 와 DreamFusion 로 생성한 3D 객체들에 대해 설문조사해본 결과, 61.7% 의 유저들이 Magic3D 모델을 더 우세하게 평가하였습니다.

Fig. 727 User studies#
Can single-stage optimization work with LDM prior?
LDM prior 를 활용한 single-stage optimization setup 으로 scene model 을 최적화할 시에 대한 ablation study 를 진행해본 결과, 성능이 좋지 않은 부분을 확인할 수 있었다고 합니다.

Fig. 728 Single-stage vs Coarse-to-fine#
Can we use NeRF for the fine model?
NeRF 를 scratch 로부터 single-step 으로 최적화하는 것은 어렵지만, fine stage 에서 scene model 을 NeRF 로 변경하는 것은 가능합니다. 위 그림의 하단 4개 그림 중 좌측, 우측 사진이 각각 coarse stage 그리고 fine stage 에서 NeRF 를 학습한 결과입니다.
Coarse models vs. fine models
동일한 coarse model 에 대해서 NeRF 와 Mesh 모델을 모두 fine-tuning 한 결과, 모두 좋은 성능을 보이고 fine-tuned 된 mesh 모델이 특히 3D 객체 퀄리티를 실사적으로 잘 표현하는 것을 확인할 수 있습니다.

Fig. 729 Coarse models vs. fine models#
6. Controllable 3D Generation#
Personalized text-to-3D
사전에 diffusion model (eDiff-I, LDM) 을 DreamBooth 을 통해 학습하고, unique identifier \([V]\) 와 함께 3D scene model 을 학습합니다. 아래 사진과 같이, subject 에 대한 정보를 유지한 채 3D model 을 잘 생성하는 부분을 확인할 수 있습니다.
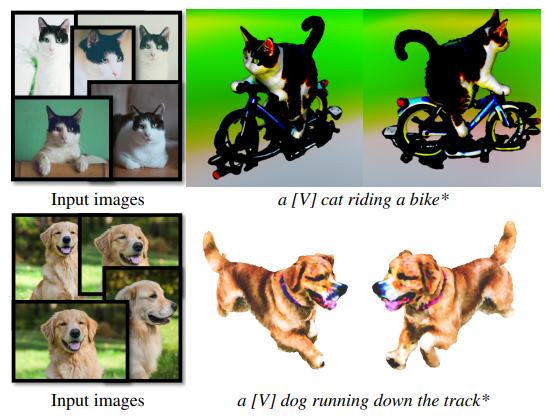
Fig. 730 Controllable 3D Generation#
Prompt-based editing through fine-tuning
다음과 같은 3단계로 prompt-based editing 으로 fine-tuning 을 진행합니다.
우선, coarse model 을 base prompt 로 학습합니다.
Base prompt 를 수정한 후, coarse NeRF 모델을 학습하고 이와 LDM 을 기반으로 high resolution NeRF 모델을 만듭니다.
마지막으로, NeRF 모델을 기반으로 high-resolution fine-tuning 을 진행합니다.

Fig. 731 Prompt-based editing through fine-tuning#
7. Conclusion#
정리하자면, 논문에서 Magic3D 의 coarse-to-fine optimization 방식을 소개하고, mesh 형태의 scene model 과 고해상도 이미지에 대한 diffusion prior 를 활용함으로써 high resolution 에 대해서도 좋은 성능을 보여줄 수 있었습니다. 추가적으로, 주어진 text prompt 에 대해 3D mesh model 을 40분 만에 생성이 가능하고, 그래픽 소프트웨어와 호환이 바로 가능하다는 장점이 있습니다.