Information
Title: Make-A-Video: Text-to-Video Generation without Text-Video Data
Reference
Author: Jeonghwa Yoo
Last updated on Nov. 26, 2023
Make A Video#
1. Introduction#
Make-A-video 제안 배경#
T2I 모델링을 할 수 있는 데이터는 인터넷을 통해 확보될 수 있으나, 비슷한 규모의 텍스트 비디오 데이터셋을 수집하기는 어렵다.
T2I 모델이 존재하는데 T2V 모델을 처음부터 학습 시키는 것은 낭비일 수 있다.
비지도 학습을 사용하여 더 많은 데이터를 학습할 수 있다.
Make-A-video 특성#
T2I 모델을 활용하여, 레이블이 지정되지 않은 비디오 데이터에 대해 비지도 학습을 사용하여 학습한다 → 페어링된 텍스트-비디오 데이터 없이도 텍스트에서 비디오를 생성할 수 있다.
텍스트 없이도 비지도 비디오만으로 세상의 다양한 개체가 어떻게 움직이고 상호 작용하는지 학습할 수 있다.
Contribution#
디퓨전 기반의 T2I 모델을 T2V로 확장하는 효과적인 방법인 Make-A-Video를 소개한다.
Text-to-image 를 prior로 사용하여 text-video 데이터의 필요성을 우회한다.
고화질, 고프레임률 비디오를 생성하는 super-resolution 전략을 제안한다.
Make-A-Video를 기존 T2V 시스템과 비교하여 평가한다. 또한, 제로샷 T2V human evaluation을 위해 300개의 프롬프트 테스트 세트를 수집하여 공개할 계획이다.
2. Previous Work#
3. Method#
Make-A-Video의 주요 요소
텍스트-이미지 쌍으로 학습된 base T2I 모델
신경망의 블록을 시간 차원으로 확장하는 시공간 convolution 및 attention layer
두 시공간 layer로 구성된 시공간 신경망과 높은 프레임 속도 생성을 위한 frame interpolation network
Make-A-Video의 최종 inference 수식
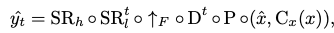
Fig. 589 최종 inference 수식#
\(SR_h\): spatial super-resolution network
\(SR^t_l\): spatiotemporal super-resolution network
\(\uparrow_{F}\): frame interpolation network
\(D^t\): spatiotemporal decoder
\(P\): prior network
\(\hat{x}\): BPE-encoded text
\(C_x\): CLIP text encoder
\(x\): input text
3.1. Text-To-Image Model#
“Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding(Imagen)”와 연구 내용을 공유하였다.
Imagen
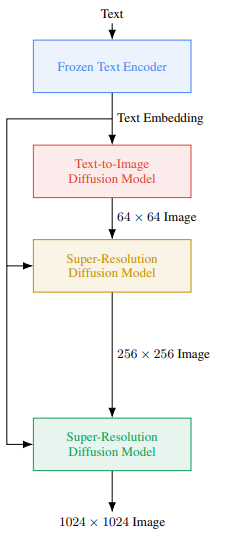
Fig. 590 Imagen 구조#
고해상도 이미지를 만들기 위해 사용한 네트워크
A prior Network \(P\): 텍스트 임베딩 \(x_e\)와 BPE encoded text tokens \(\hat{x}\)이 주어졌을 때 이미지 임베딩 \(y_e\)를 생성하는 네트워크
Decoder Network \(D\): 이미지 임베딩 \(y_e\)로부터 저해상도 64X64 RGB 이미지 \(\hat{y}_l\)를 생성하는 네트워크
Super-resolution network \(SR_l\), \(SR_h\): D에서 생성된 이미지 64X64 저해상도 이미지 \(\hat{y}_l\)를 256X256, 768X768 픽셀로 증가시켜 최종 이미지 \(\hat{y}\)를 만드는 네트워크
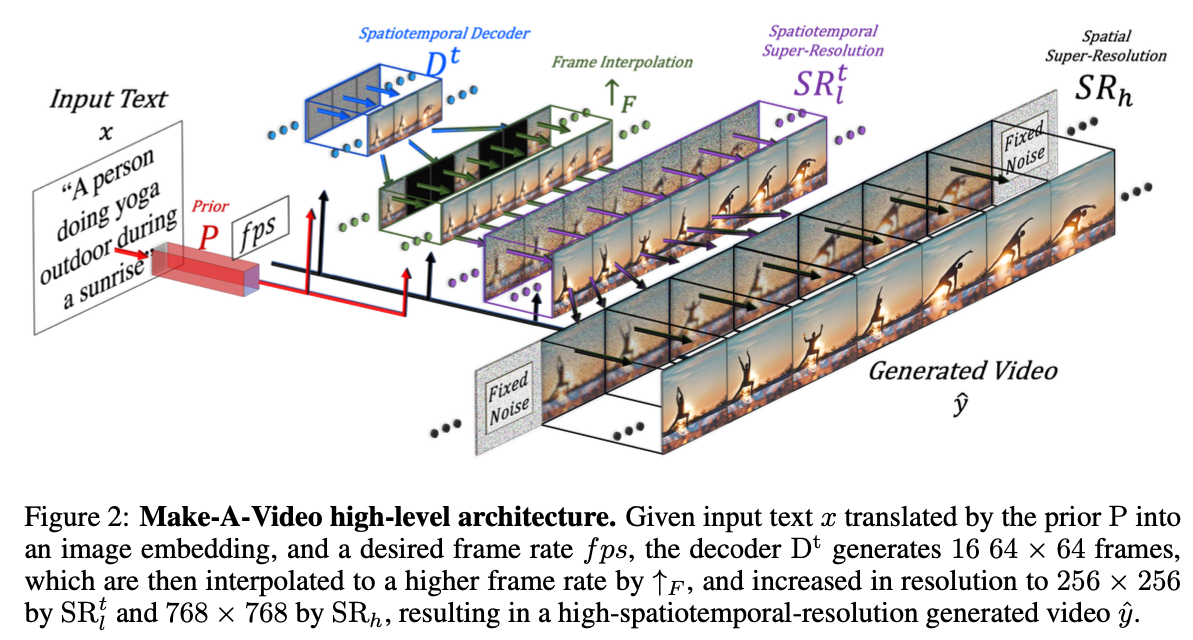
Fig. 591 text \(x\)가 prior \(P\)를 통해 image embedding 변환된다. fps: desired frame rate#
3.2. Spatiotemporal Layers#
2차원 조건부 네트워크를 시간적 차원으로 확장하기 위해 다음의 구성 요소를 수정한다.
Convolutional layers
Attention layers
Fully-connected layers는 특별한 수정을 할 필요 없이 시간 정보만 추가해주면 된다.
구성 요소 수정 결과 \(D^t\)는 64X64 사이즈의 16 RGB frame을 만들게 된다.
Frame interpolation network \(\uparrow_{F}\)가 생성된 16개의 프레임과 super-resolution 네트워크 \(SR^t_l\) 사이를 보간하여 프레임 속도를 증가시킨다.
Super-resolution 네트워크에는 hallucinating information(환각 정보)가 포함 된다. 깜박이는 잔상이 생기지 않으려면, 환각이 프레임 전체에 걸쳐 일관성을 유지해야 한다.
Hallucinating information
실제로 존재하지 않는 정보나 세부 사항을 생성하거나 가상으로 추가하는 것
프레임당 super resolution을 수행하는 것보다 spatiotemporal 모듈인 \(SR^t_l\)가 더 좋은 성능을 보였다.
하지만, \(SR_h\)를 위와 같은 모듈로 만들기엔 메모리 및 컴퓨팅 제약과 고해상도 비디오 데이터의 부족으로 \(SR_h\)를 위와 같이 시간적 차원으로 확장하는 것은 어려웠다 → \(SR_h\)는 공간적 차원에서 작동한다.( 각 프레임에 대해 동일한 노이즈 초기화를 사용하여 프레임 전반에 걸쳐 일관된 환각을 제공함)
3.2.1 Pseudo-3D convolutional layers#
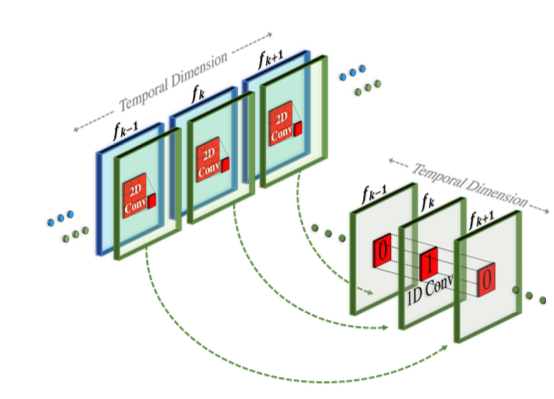
Fig. 592 Architecture of Pseudo-3D convolutional layers#
2D 컨벌루션 레이어 다음에 1D 컨벌루션을 쌓는다 (Cf:separable convolution)
3D 컨벌루션의 계산 load를 줄일 수 있다.
사전 학습된 2D 컨볼루션 레이어와 새로 초기화된 1D 컨벌루션 레이어 사이에 명확한 경계를 생성하여, spatial information을 유지한 채 temporal convolution을 처음부터 학습할 수 있게 한다.
Pseudo-3D convolutional layer
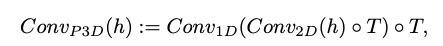
Fig. 593 Pseudo-3D convolutional layer#
\(h\): 입력 텐서 (dimension: \(B\)(batch),\(C\)(channels),\(F\)(frames),\(H\)(height),\(W\)(width))
\(\text{o}T\): transpose operator (spatial ↔ temporal)
\(Conv_{2_D}\)는 pretrained T2I 모델에서 초기화 되고, \(Conv_{1_D}\)는 identity 함수로 초기화 된다.
3.2.2. Psuedo-3D attention layers#
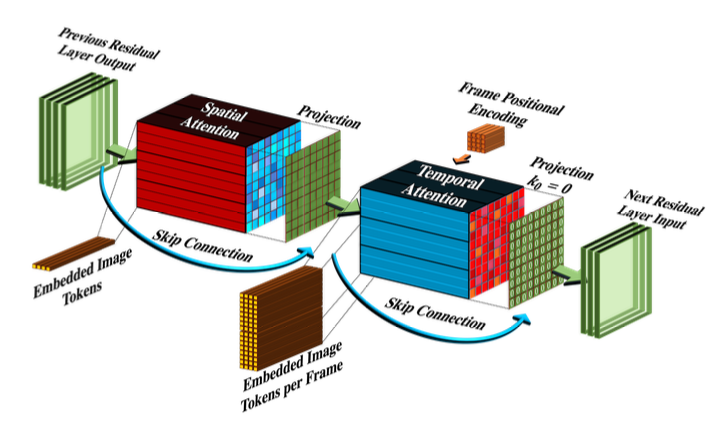
Fig. 594 Architecture of Pseudo-3D attention layers#
“Video Diffusion Models**”**에 영감을 받아 dimension decomposition 전략을 attention layer에 확장하였다.
Pseudo-3D convolutional layer처럼 각각의 spatial attenion layer를 쌓아, 전체 spatiotemporal attention layer를 근사화하는 temporal attention layer를 쌓는다.
Pseudo-3D attention layer
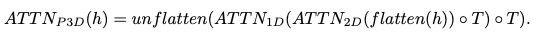
Fig. 595 Pseudo-3D attention layer#
\(h\): 입력 텐서 (dimension: \(B\)(batch),\(C\)(channels),\(F\)(frames),\(H\)(height),\(W\)(width))
flatten: spatial dimension 축에 대해 flatten하는 연산 (결과 dimension: \(B\),\(C\),\(F\),\(HW\))
\(ATTN_{2D}\)는 pretrained T2I 모델에서 초기화되고, \(ATTN_{1D}\)는 identity function으로 초기화 된다.
Code
class SpatioTemporalAttention(nn.Module): def __init__( self, dim, *, dim_head = 64, heads = 8, add_feed_forward = True, ff_mult = 4, pos_bias = True, flash = False, causal_time_attn = False ): super().__init__() assert not (flash and pos_bias), 'learned positional attention bias is not compatible with flash attention' self.spatial_attn = Attention(dim = dim, dim_head = dim_head, heads = heads, flash = flash) self.spatial_rel_pos_bias = ContinuousPositionBias(dim = dim // 2, heads = heads, num_dims = 2) if pos_bias else None self.temporal_attn = Attention(dim = dim, dim_head = dim_head, heads = heads, flash = flash, causal = causal_time_attn) self.temporal_rel_pos_bias = ContinuousPositionBias(dim = dim // 2, heads = heads, num_dims = 1) if pos_bias else None self.has_feed_forward = add_feed_forward if not add_feed_forward: return self.ff = FeedForward(dim = dim, mult = ff_mult) def forward( self, x, enable_time = True ): b, c, *_, h, w = x.shape is_video = x.ndim == 5 enable_time &= is_video if is_video: x = rearrange(x, 'b c f h w -> (b f) (h w) c') #[bXf, hXw, c] else: x = rearrange(x, 'b c h w -> b (h w) c')#[b, hXw, c] space_rel_pos_bias = self.spatial_rel_pos_bias(h, w) if exists(self.spatial_rel_pos_bias) else None x = self.spatial_attn(x, rel_pos_bias = space_rel_pos_bias) + x if is_video: x = rearrange(x, '(b f) (h w) c -> b c f h w', b = b, h = h, w = w) else: x = rearrange(x, 'b (h w) c -> b c h w', h = h, w = w) if enable_time: x = rearrange(x, 'b c f h w -> (b h w) f c') #[bXhXw, f, c] time_rel_pos_bias = self.temporal_rel_pos_bias(x.shape[1]) if exists(self.temporal_rel_pos_bias) else None x = self.temporal_attn(x, rel_pos_bias = time_rel_pos_bias) + x x = rearrange(x, '(b h w) f c -> b c f h w', w = w, h = h) if self.has_feed_forward: x = self.ff(x, enable_time = enable_time) + x return x
Frame rate conditioning
비디오의 초당 프레임 수를 나타내는 추가 컨디셔닝 파라미터 \(fps\)를 추가한다.
3.3 Frame Interpolation Network#
↑F (Frame Interpolation Network)란?
생성된 프레임 수를 증가시켜, 생성된 비디오를 더 부드럽게 만들고 비디오 길이를 연장 시킬 수 있는 네트워크
프레임을 보간하고 extrapolation을 하는 네트워크
Extrapolation: 주어진 데이터 또는 정보를 사용하여 미래의 값을 예측하거나 확장
↑F (Frame Interpolation Network) 동작
Spatialtemporal decoder \(D^t\)에서 마스크 처리된 입력 프레임을 제로 패딩하고 비디오 업샘플링을 적용하여 masked frame interpolation을 파인 튜닝한다.
파인 튜닝할 때 U-Net의 입력에 4개의 채널을 추가한다.
RGB 마스킹 비디오 입력을 위한 3개의 채널과 마스킹되는 프레임을 나타내는 추가 바이너리 채널
다양한 frame-skips과 \(fps\)에 대해 파인튜닝하여 추론시 여러 temporal upsample rate를 제공한다.
본 논문의 모든 실험에서는 ↑F를 frame skip 5로 적용하여 16프레임 비디오를 76프레임((16-1)X5+1)으로 업샘플링 하였다.
비디오 시작 또는 끝 프레임을 마스킹하여 비디오 추정 또는 이미지 애니메이션에도 사용할 수 있다.
3.4 Training#
위에서 설명한 구성 요소들은 독립적으로 학습 된다.
훈련 과정
Prior \(P\) 훈련 (text-image 데이터 이용)
→ 텍스트를 입력으로 받는 prior \(P\)는 text-image 데이터에 대해서만 학습 되고 비디오에 대해서는 파인 튜닝하지 않는다.
이미지를 이용한 학습
→ Decoder, prior, 두개의 super-resolution 요소들은 먼저 텍스트 없이 이미지 만으로 학습 된다.
→ Decoder는 Clip image embedding을 입력으로 받고, super-resolution 요소들은 학습 중에 입력으로 들어온 downsampled image를 입력으로 받는다.
비디오를 이용한 학습
이미지에 대한 훈련이 끝나면 새로운 시간 레이어를 추가하고 초기화하여 레이블이 지정되지 않은 비디오 데이터에 대해 파인 튜닝한다.
원본 비디오에서 16프레임이 샘플링 되며, 1에서 30 사이의 랜덤 \(fps\)를 사용한다.
디코더를 학습하는 동안 훈련 초기에는 더 높은 \(fps\) 범위(모션이 적은)에서 시작하고, 이후에는 더 작은 \(fps\) 범위(모션이 많은)로 전환한다.
Masked-frame interpolation 네트워크는 temporal 디코더로부터 파인 튜닝된다.
4. Experiments#
4.1 Dataset and Settings#
Datasets#
Image, Text
LAION-5B 데이터셋의 일부 2.3B의 데이터를 사용하였다.
NSFW 이미지, 텍스트의 유해한 단어 또는 워터마크 확률이 0.5보다 큰 이미지가 있는 샘플 쌍을 필터링하였다. ****
NSFW: Not Safe For Work, 선정적이거나 음란하거나 폭력적인 내용을 포함한 콘텐츠
Video
WebVid-10M과, HD-VILA-100M 데이터셋의 일부 10M 데이터를 사용하였다.
Decoder \(D^t\), interpolation 모델 → WebVid-10M을 이용하여 학습
\(SR^t_l\) → WebVid-10M, HD-VILA-100M을 이용하여 학습
Zero-shot test 데이터
UCF-101, MSR-VTT
UCF-101: 액션 인식 연구를 위해 고안되었으며, 다양한 동작 및 환경에서 촬영된 비디오 클립 데이터셋
MSR-VTT: 비디오와 해당 비디오에 대한 텍스트 설명 또는 캡션을 포함하는 데이터셋
Automatic Metrics#
UCF-101
각 클래스에 대해 하나의 템플릿 문장을 작성하고 평가를 위해 수정한다.
10K 샘플에 대해 Fretchet Video Distance(FVD)와 Inception Score(IS)를 측정한다.
Train셋과 동일한 클래스 분포를 따르는 샘플을 생성한다.
MSR-VTT
테스트 세트의 모든 59,794 캡션에 대한 FID와 CLIPSIM(비디오 프레임과 텍스트 간의 평균 CLIP 유사도)를 측정한다.
Human Evaluation Set and Metrics#
Amazon Mechanical Turk(AMT)에서 300개의 프롬프트로 이루어진 평가 세트를 수집하였다.
Annotator들에게 T2V 시스템이 있다면 어떤 것을 생성하고 싶은지 물어봤다.
불완전하거나, 너무 추상적이거나, 불쾌감을 주는 프롬프트를 필터링 하였다.
5가지 카테고리(동물, 판타지, 사람, 자연 및 풍경, 음식 및 음료)를 식별하고 해당 카테고리에 맞는 프롬프트를 선택하였다.
이러한 프롬프트는 동영상을 만드는 데에 사용되지 않고 선택 되었으며, 고정된 상태로 유지했다.
Human evaluation을 위해 Imagen의 DrawBench 프롬프트도 사용하였다.
비디오 품질과 text-vedio faithfulness를 평가하였다.
비디오 품질 → 두 개의 비디오를 랜덤 순서로 보여주고 어떤 비디오의 품질이 더 좋은지 annotator에게 물어본다.
Text-vdeio faithfulness → 텍스트를 추가로 보여주고 어떤 비디오가 텍스트와 더 잘 일치하는지 annotator에게 물어본다.
보간 모델과 FILM의 비디오 모션 사실감을 비교하기 위한 평가도 진행하였다.
5명의 각기 다른 annotator의 다수 득표를 최종 결과로 사용하였다.
4.2 Quantitative Results#
Automatic Evaluaton on MSR-VTT#
MSR-VTT에 대해 성능을 보고하는 GODIVA, NUWA 외에도, 중국어와 영어를 모두 입력으로 받는 CogVideo 모델에 대해서도 추론을 수행하였다.

Fig. 596 Automatic Evaluaton on MSR-VTT#
→ 가장 우수한 성능을 보인다.
Automatic Evluation on UCF-101#
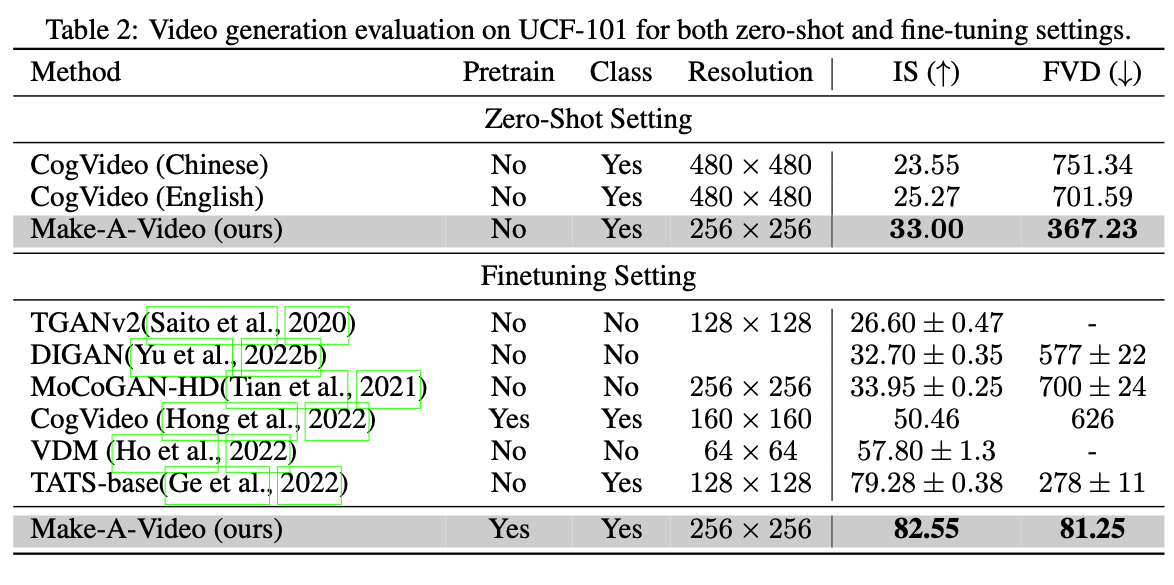
Fig. 597 Automatic Evluation on UCF-101#
→ Make-A-Video의 제로 샷 성능이 다른 방법보다 우수하다. Finetunning을 한 결과에서도 SOTA를 달성하였다.
Human Evaluation#
DrawBench와 테스트셋에 대해서 CogVideo와 성능을 비교한다.
또한, VDM의 웹 페이지에 표시된 28개의 동영상에 대해서도 평가한다.
각 입력에 대해 8개의 동영상을 무작위로 생성하고, 8번 평가하여 평균 결과를 낸다.
사람의 평가를 위해 76x256x256 해상도로 동영상을 생성한다.
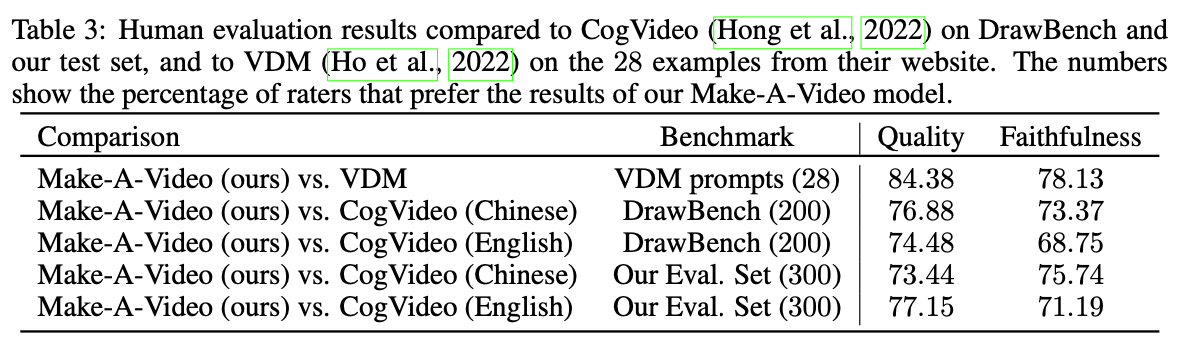
Fig. 598 Human Evaluation#
→ 평가자가 Make-A-Video 모델의 결과가 더 낫다고 투표한 퍼센트 비율. 대부분 평가자가 모든 벤치마크에서 Make-A-Video가 더 낫다고 평가하였다.
Frame Interpolation Network와 FILM을 비교 평가하기
DrawBench의 텍스트 프롬프트와 평가 세트에서 저프레임률 비디오(1 FPS)를 생성한 다음, 4FPS까지 업샘플링한다.
평가자들은 eval set에 대해서는 62%, DrawBench에 대해서는 54%로 Make-A-Video가 더 낫다고 평가하였다.
프레임 간의 차이가 커서 물체가 어떻게 움직이는지에 대한 real-world 지식이 중요한 경우에는 본 논문에 방법이 더 뛰어난 것으로 관찰 되었다.
4.3 Qualitative Results#

Fig. 599 T2V Generation 결과. 맨 위: VDM, 가운데: CogVideo, 맨 아래: Make-A-Video → Make-A-Video가 모션의 일관성을 유지하면서 더 풍부한 콘텐츠를 생성할 수 있다.#

Fig. 600 이미지에 mask frame interpolation 및 extrpolation network ↑F를 적용한 결과. 가장 왼쪽에 입력 이미지가 주어지면, 이를 동영상으로 애니메이션화 함. 사용자는 자신의 이미지를 사용하여 동영상을 생성할 수 있으며, 생성된 동영상을 개인화하고 직접 제어할 수 있음.#

Fig. 601 두 이미지 사이의 interpolation 결과. 왼쪽: FILM, 오른쪽: 본 논문의 approach FILM → 실제 움직이는 object에 대한 이해 없이 프레임을 부드럽게 전환하기만 함. 본 논문의 approach → 의미론적으로 더 의미있는 interpolation을 만듬.#

Fig. 602 비디오 변형 예시. 위: 원본 비디오, 아래: 새로운 비디오#
5. 결론#
주변 세계로부터 지식을 배우는 human intelligence처럼 generative system도 인간의 학습 방식을 모방할 수 있다면, 더욱 창의적이고 유용할 것이다.
연구자들은 비지도 학습을 통해 훨씬 더 많은 동영상에서 세계의 dynamic을 학습함으로써 기존의 한계를 극복할 수 있다.