Information
Title: LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Reference
Code: Official
Project Page: https://me.kiui.moe/lgm/
Demo: HuggingFace Spaces
Author: Donghyun Han
Last updated on Jan. 13, 2025
LGM#
Summary#
3D Content 생성은 계산 cost가 크기 때문에 고해상도 영상에 대해 아직까지 한계점을 가지고 있다. 그러나 본 논문에서 제안하는 Large Multi-View Gaussian Model(LGM)은 single-view image or text를 고해상도 3D Content로 변환이 가능하다.
Feature:
3D Representation: gaussian 기반의 효율적이면서도 강력한 3D representation + NeRF등과 같은 differentiable rendering.
3D Backbone: single-view image 나 text를 입력받아 multi-view image를 생성하는 Diffusion + Gaussian Model의 backbone으로 asymmetric(비대칭) U-Net을 제안.
효율적이고 강력한 성능을 가지고 있음. 5초 이내에 3D Content 생성이 가능하면서 512 resolution으로 훈련이 가능하다.
1. Introduction#
3D Content 생성 분야는 다양하게 연구되어 왔으며, 최근에는 single-view나 few-shot 영상을 3D object로 변환하는 연구가 발전하고 있다. 이같은 방법은 Transformer 기반 모델을 통해 triplane-based NeRF를 직접 예측하는 방식으로 이루어지고 있다.
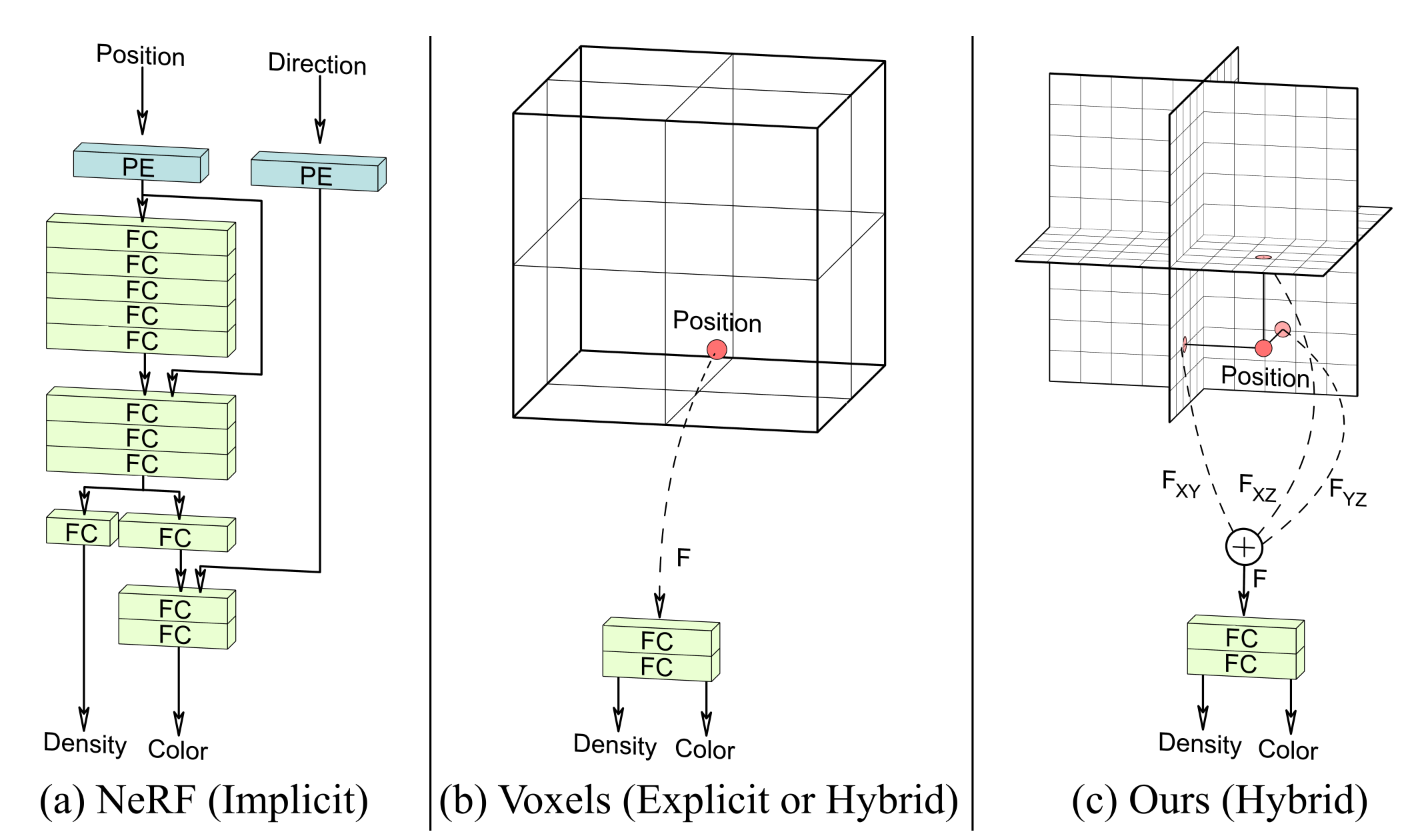
Fig. 820 Triplane-based representation#
그러나 기존 연구는 저해상도에서 훈련되어 상세한 텍스쳐나 복잡한 표현이 힘들다. 이는 3D representation이 비효율적이고 3D backbone이 너무 무겁기 때문이다. 예를들어 LRM은 triplane representation의 해상도가 32인 반면, rendering image의 해상도는 128로 병목이 생기게 된다. transformer 기반 백본 모델이 너무 cost가 크기 때문에 해상도에 대한 한계점이 생길 수 밖에 없다.
따라서 본 연구는 triplane-based rendering이나 transformer 기반 모델을 사용하지 않는다. 대신 asymmetric U-Net을 통해 3D Gaussian Splatting을 예측하는 방식으로 문제를 해결했다.
LGM의 목표는 고해상도 + 적절한 representation을 학습하는 것인데, Gaussian Splatting은 triplane에 비해 간결한 representation을 가지고 asymmetric U-Net은 Multi view pixel에 대해 충분한 3D Gaussian을 생성할 수 있기 때문에 적합한 방법이라고 한다. 또한 LGM은 빠르고 image-to-3D, text-to-3D를 모두 지원한다.

Fig. 821 LGM - i23, t23 results#
방법은 Instant3D와 비슷한 방식을 사용한다. (2D Diffusion Model을 통해 Multi-view Image를 생성하고 3D reconstruction.)
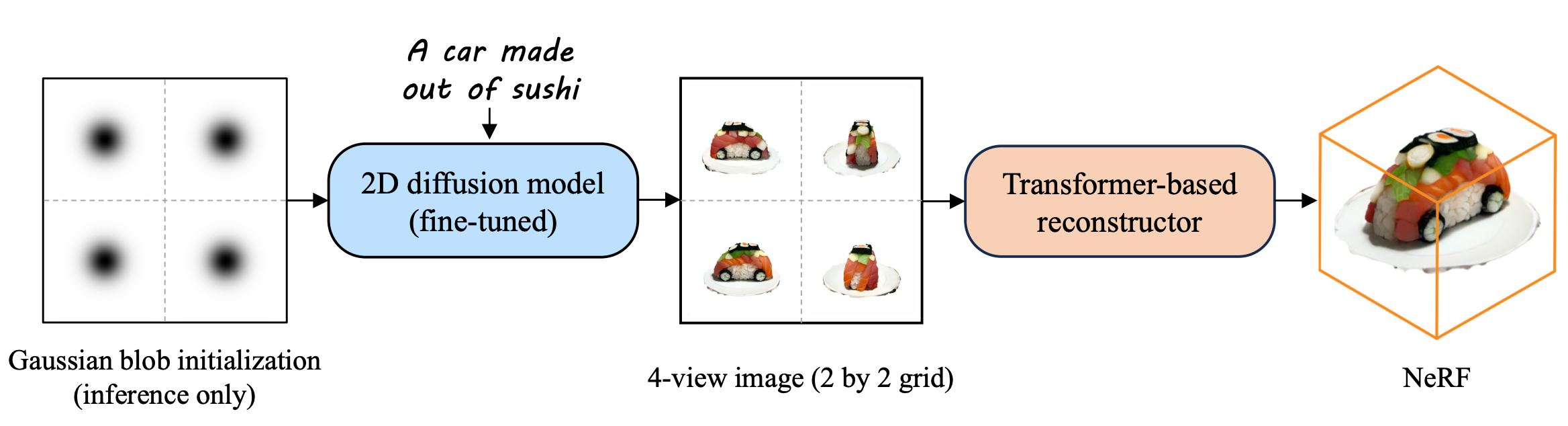
Fig. 822 Instant3D#
Contribution Summary:#
text나 single-view image를 통해 생성된 multi-view image를 융합해 고해상도 3D Gaussian을 생성하는 프레임워크를 제안.
고해상도에 대한 효율적인 end-to-end 학습을 위해 asymmetic U-Net 아키텍쳐 + Robust한 학습을 위한 데이터 증강 기술 + 3D Gaussian의 mesh 추출 방식 제안.
실험을 통해 text-to-3D / image-to-3D에서 높은 품질, 고해상도, 효율성을 입증.
3. Large Multi-View Gaussian Model#
3.1 Preliminaries#
Gaussian Splatting#
Parameter \(\Theta_i=\{x_i, s_i, q_i, \alpha_i, c_i\}\)로 각 Gaussian을 표현할 수 있으며 각각 center \(x\in\mathbb{R}^3\), scaling factor \(s\in\mathbb{R}^3\), rotation quaternion \(q\in\mathbb{R}^4\), opacity value \(\alpha\in\mathbb{R}\), color feature \(c\in\mathbb{R}^C\)을 의미.
Multi-View Diffusion Models#
2D Diffusion Model을 single-view image의 object를 multi-view image로 변환할 수 있도록 fine-tuning하여 사용.
3.2 Overall Framework#
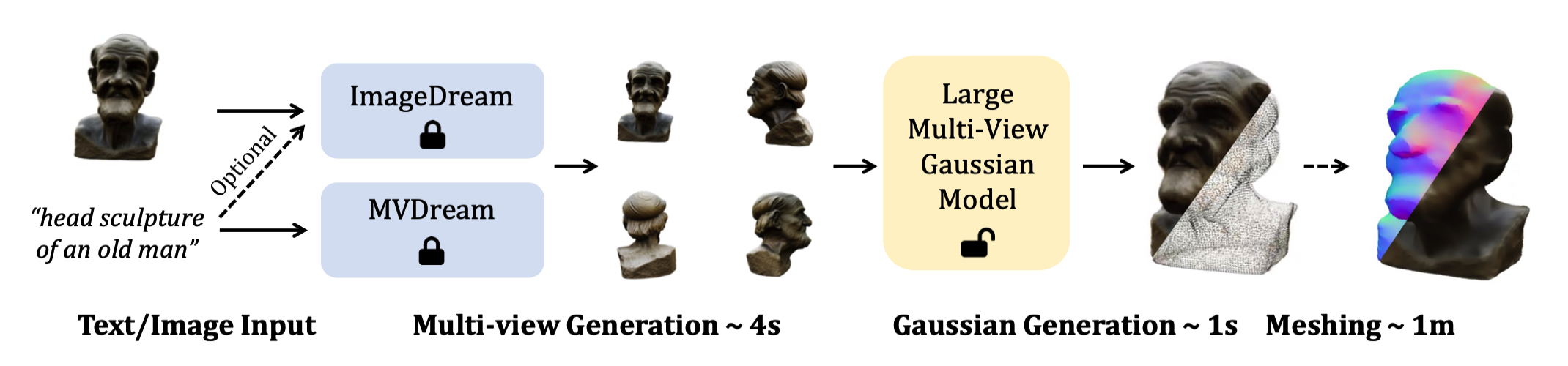
Fig. 823 LGM framework#
LGM은 2step으로 진행되며 먼저 2D Diffusion model을 통해 single-view image 또는 text를 multi-view image로 변환한다. 이때 MVDream은 text, Image Dream은 image를 입력받아 변환한다. 두 모델 모두 직교 방위각에 따른 multi-view image를 생성한다.
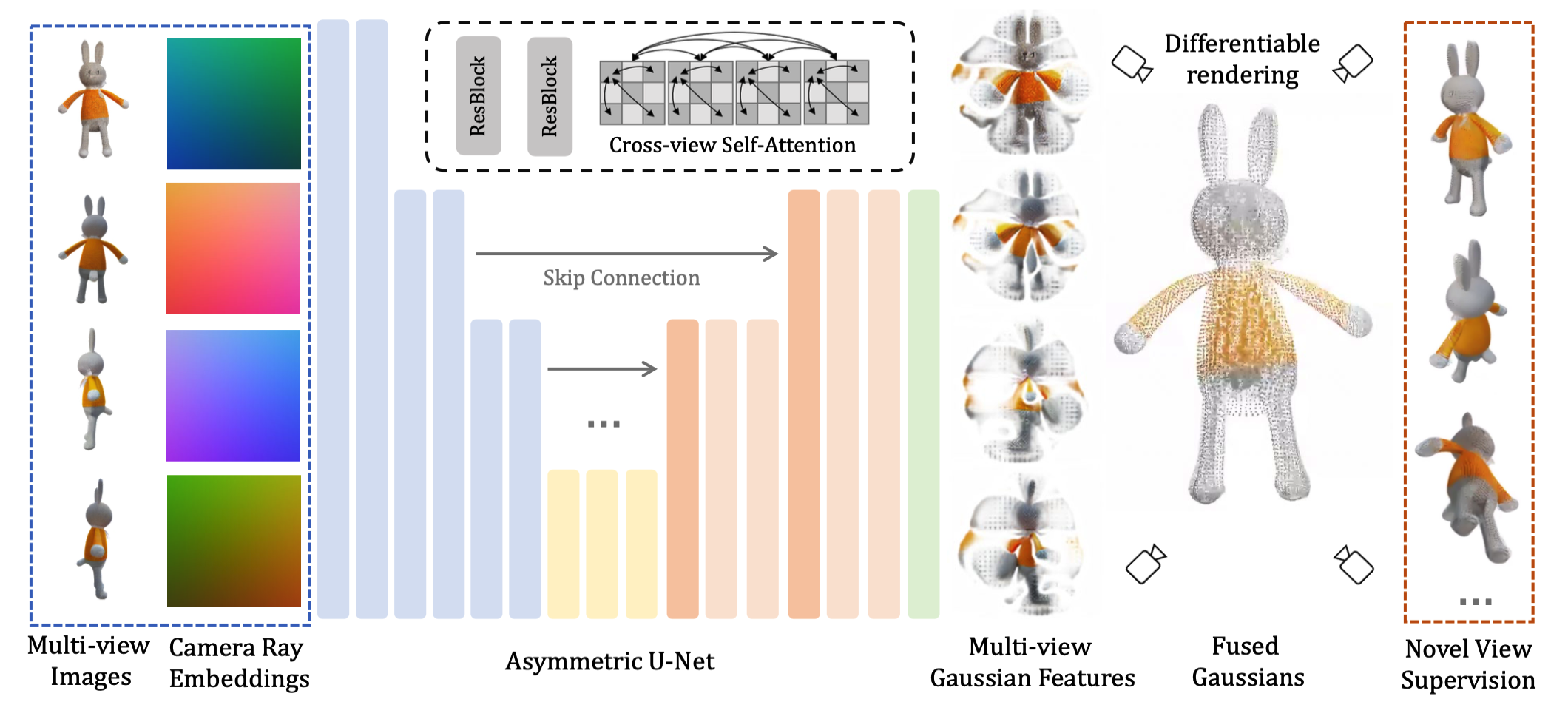
Fig. 824 Asymmetric U-Net#
생성된 multi-view image는 U-Net기반 3D Gaussian을 예측하도록 학습된다. 생성한 Gaussian은 추가적인 변환 작업을 통해 폴리곤 형태로 변환이 가능하다. (downstream task)
3.3 Asymmetric U-Net for 3D Gaussians#
위 그림과 같이 Gaussian 예측 모델은 Asymmetric U-Net을 사용하며 기존과 같이 Plücker ray embedding을 사용해 인코딩값 + multi-view image에 대한 RGB 값을 합친 총 9차원 feature map을 입력받는다.
(RGB + 3차원 ray direction + 3차원 ray origin==9)
각 pixel i에 대한 feature map \(f_i\)에 대해 \(c_i,o_i,d_i\)는 각각 RGB value, ray origin, ray direction을 의미한다. U-Net 구조는 residual layer와 self-attention layer로 이루어져 있으며 메모리를 효율적으로 사용하기 위해 deeper layer에서만 self-attention을 사용하였다.
4가지 이미지에 대한 feature는 self-attention 전 flatten 후 concatenation을 통해 정보를 융합한다. (MV-Dream, Image-Dream과 유사한 방식)
U-Net 구조를 비대칭적으로 구성한 이유는 입력 영상의 크기보다 더 작은 크기의 출력을 예측하도록 하기 위함이다. 즉 더 큰 입력 영상을 사용할 수 있으며 출력 gaussian의 수를 제한할 수 있다는 장점을 가진다. 최종 출력 feature map은 14개의 channel을 포함하는 Gaussian \(\Theta_i\) 이다.
학습의 안정화를 위해 기존 gaussian splatting과 activation function을 다르게 사용했다. 먼저 예측 position \(x_i\)를 \([-1,1]^3\)에 클램핑하고 softplus activation scale \(s_i\)에 0.1을 곱하여 훈련이 시작될 때 생성되는 Gaussian이 scene의 중심에 가깝도록 조정했다. 최종 출력된 Gaussian 집합은 3D Gaussian으로 융합된다.
3.4 Robust Training#
Data Augmentation#
Diffusion model과 Gaussian splatting은 학습 데이터셋에 대해 각각 따로 학습되지만 실제 inference time에는 두 파이프라인이 함께 동작해야 하기 때문에(Diffusion output == Gaussian splatting input) 간극을 좁혀줄 수 있는 강력한 augmentation 기법이 필요하다. LGM은 2가지의 augmentation 기법을 제시했다.
Grid Distortion.
2D Diffusion model을 통해 3D multi-view image를 합성하는 연구는 많지만, 기존 연구들은 3D representation에 대한 고려가 없기 때문에 각 view들의 미묘한 inconsistency가 생긴다. 따라서 Gaussian splatting을 훈련할 때 첫 입력 view를 제외한 나머지 입력 view에 일부러 Grid Distortion(왜곡)을 주어 Gaussian splatting 모델이 Robust하게 학습될 수 있도록 한다.
Orbital Camera Jitter.
Grid Distortion의 이유와 비슷한데 multi-view Image의 각도나 camera의 위치가 항상 정확하게 일치하지 않기 때문에 random rotation을 통해 좀더 Robust 하게 학습될 수 있도록 Augmentation을 추가한다.
Loss Function#
학습은 Gaussian을 결합하여 입력 4개의 view를 포함한 총 8개의 view에 대한 rendering image를 만들고 각 RGB와 \(\alpha\)에 대한 몇가지 손실 함수를 사용하였다.
4. Experiments#

Fig. 825 Quantitative results#

Fig. 826 Qualitative results#

Fig. 827 LRM vs LGM#

Fig. 828 text-to-3D results#

Fig. 829 Diversity results#

Fig. 830 Ablation study#
Limitations#
기본적으로 Multi-view reconstruction 모델이기 때문에 4개의 입력 view의 품질에 대한 의존도가 높다.
그러나 multi-view를 생성하는 diffusion model이 완벽하지 않기 때문에 (낮은 resolution, inconsistency 등) 한계점을 가지고 있다.
5. Conclusion#
기존 NeRF 및 Transformer 기반 모델과 달리 Gaussian Splatting 과 U-Net 기반 구조를 사용하여 높은 메모리 cost 문제를 해결했다. 또한 고해상도 영상에 대한 학습을 통해 고품질의 3D content를 생성할 수 있었다.