Information
ConceptLab#
Introduction#
본 논문에서는 Creative Generation의 일환으로, 새롭고 창의적인 개념을 생성하는 내용을 다룹니다. 최근 text-to-image 생성 기술과 Personalization 기술이 크게 발전함에 따라 이미지 생성 뿐만 아니라 개인화된 개념을 생설할 수 있게 되었습니다. 이러한 강력한 모델을 사용하여 모델에 명시적으로 설명되지 않은 새로운 창의적 개념을 생성할 수 있을까요?

Fig. 419 ConceptLab#
Related Work#
Text-Guided Sysnthesis
대부분의 text-guided 생성 기술은 pretrain 된 텍스트 인코더에서 추출한 임베딩을 diffusion 모델에 직접 conditioning합니다. 즉, 텍스트 데이터를 처리하여 이미지 생성 과정에 통합하는 방식입니다. 본 논문에서는 Latent Diffusion Model과 Diffusion prior model을 활용해서 creative generation에서의 이점을 보입니다.
Diffusion Prior
Diffusion Prior 모델은 입력된 텍스트 임베딩을 CLIP의 latent space에서 해당하는 이미지 임베딩으로 매핑합니다. 이후 디코더는 CLIP의 이미지 임베딩에 condition이 부여된 이미지를 생성하기 위해 훈련됩니다.
Personalization
Personalization은 text-guided synthesis 맥락에서 사용자가 입력한 텍스트 프롬프트에 맞는 주제나 스타일을 표현하는 새로운 이미지를 생성하는 것을 목표로 합니다. 일반적으로 새로운 개념을 학습시키기 위해 임베딩을 최적화하거나 denoising 네트워크를 finetuning 하는 방법을 활용합니다. 하지만 본 연구에서는 Creative Generation에 초첨을 맞추고 새로운 개념을 생성하고 기발한 장면을 생성하는 것을 목표로 합니다.
Creative Generation
창의적 내용을 생성하는 것은 다양한 접근 방법이 있습니다. Xu et al 에서는 set-evolution 방법을 활용해 3D 형태의 모델링을 제안했습니다. Elgammal et al 에서는 GAN의 맥락에서 창의적 생성을 탐구하며, 기존 스타일에서의 편차를 극대화하는 방식으로 새로운 스타일을 학습했습니다. Sbai et al 에서는 새로운 손실 함수를 도립했습니다. 본 연구에서는 주어진 카테고리와 일치하도록 최적화하면서도 그 카테고리의 기존 개념들과 다른 새로운 개념을 찾는 방식으로 창의적 생성에 접근했습니다. 본 방법을 통해 새로운 개념들은 서로 혼합될 수 있으며 더 유연한 생성 과정을 갖게됩니다.

Fig. 420 Text-guided generation (top left), personalization methods (bottom left), creative generation method (right)#
Prelimiaries#
Latent Diffusion Models
Latent Diffusion Model에서는 오토인코더의 latent space 내에서 diffusion 과정이 진행됩니다. 먼저, 인고더 \(E\)는 주어진 이미지 \(x\)를 latent code \(z\)로 매핑하는 것을 목표로 합니다. 이때, z=E(x)가 됩니다. 동시에 디코더 D는 원본 입력 이미지를 재구성하도록 합니다. DDPM의 경우 아래 주어진 손실을 최소화하도록 학습합니다.
denoising network \(\epsilon \theta\) 는 잠재 코드 \(zt\)에 추가된 잡음 \(\epsilon\)을 제거합니다. 이 과정에서 현재 시간 단계 t와 조건 벡터 c도 고려됩니다.
Diffusion Prior
일반적으로 Diffusion model은 CLIP 텍스트 인코딩에서 직접 파생된 조건 벡터 \(c\)를 활용하여 주어진 텍스트 프롬프트 \(y\)에 대해 훈련됩니다. \(Ramesh et al\)에서 text-to-image 생성 문제를 2가지 단계로 decompose 합니다. 먼저, Diffusion Prior 모델을 활용하여 주어진 텍스트 프롬프트로부터 이미지 임베딩을 예측합니다. 다음으로, 이 이미지 임베딩에 조건을 부여하여 이미지를 생성하는 diffusion decoder로 보내집니다. 훈련 또한 일반적으로 두 독립적인 단계로 이루어집니다.
Diffusion 디코더는 이미지 임베딩을 조건 \(c\)와 위 Latent Diffusion Model에 정의된 손실을 활용하여 훈련됩니다. 그 다음 diffusion prior model \(P\theta\)는 임베딩 \(e_{t}\)로부터 denoise 된 이미지 임베딩 \(e\)를 직접 예측합니다. 이 두 단계 접근법은 이미지 다양성을 향상시키며 중간 CLIP 이미지 임베딩에 직접 접근하고 해당 공간에서 직접 제약을 할 수 있게 합니다.
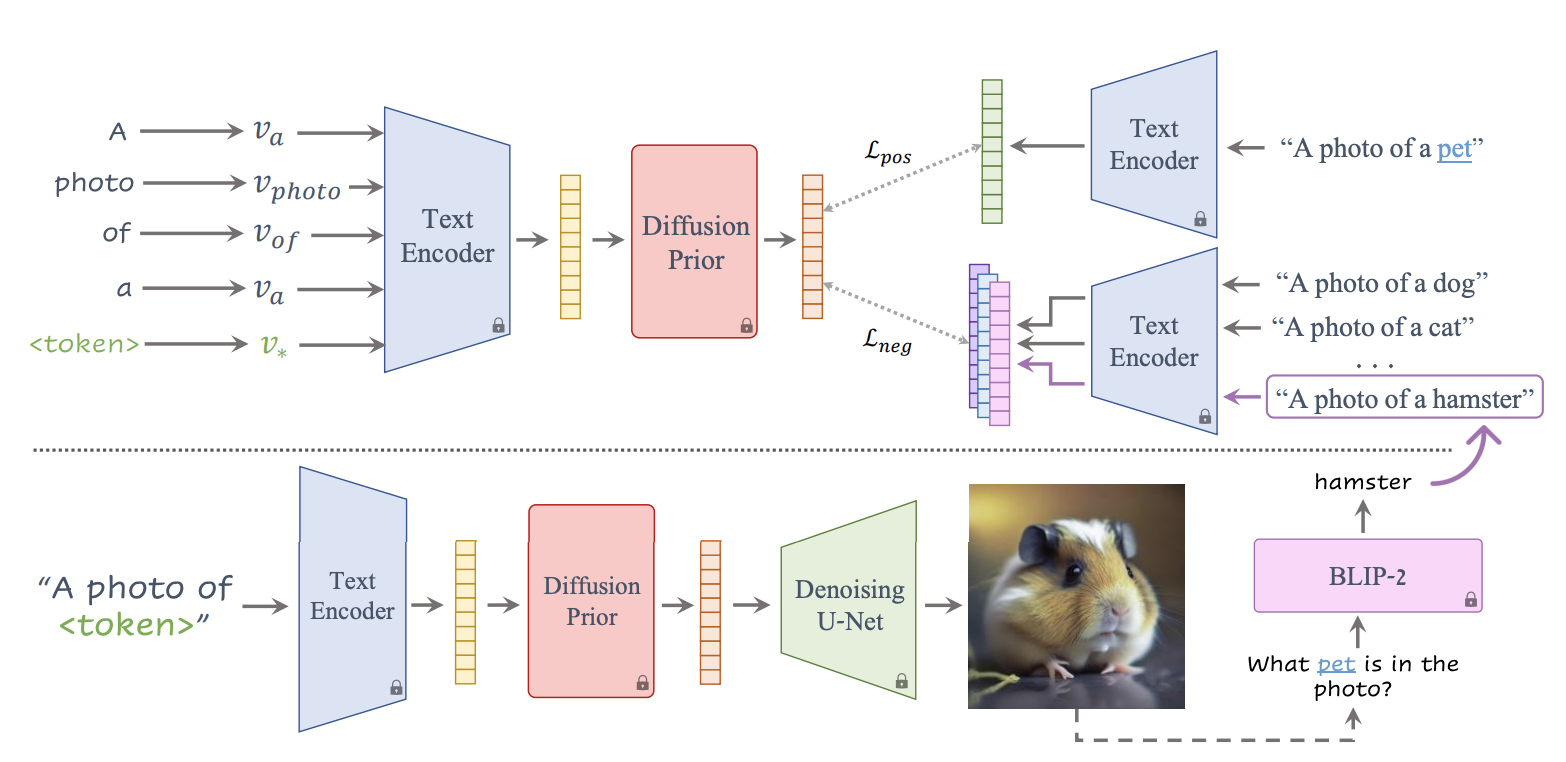
Fig. 421 ConceptLab#
Method#
ConceptLab은 생성하고자 하는 새로운 개념을 대표하는 단일 임베딩 \(v_{*}\)를 최적화합니다. 이후 주어진 카테고리에 유사하면서도 기존 멤버들과 다른 특성을 가지도록 손실 집합을 계산합니다. 훈련하는 동안, 현재 생성된 새로운 개념을 바탕으로 negative contraints를 더하기 위해 pretrained BLIP-2 VQA 모델을 활용합니다.
The Constraints#
본 연구에서는 긍정적 제약 \(C_{pos}\)와 부정적 제약 \(C_{neg}\) 두 가지를 활용합니다. 각 제약 조건은 텍스트 토큰을 활용하여 정의됩니다.
The Objective#
본 연구에서는 두가지 제약 조건을 바탕으로 하여 새로운 개념을 대표하는 임베딩 \(v_{*}\)와 각 제약 조건 간의 유사도를 측정합니다. 우선, \(v_{*}\)와 각 제약 단어 \(c\)를 동일한 무작위 샘플링된 프롬프트 y에 통합합니다. 각 문장은 CLIP 텍스트 임베딩으로 인코딩되며, 이것이 텍스트 제약 조건을 정의합니다. 텍스트 프롬프트를 diffusion prior 모델에 통과시키면, 프롬프트의 특정 인스턴스가 생성됩니다. 이러한 방식으로 \(E_{y}(v_{*}\)가 diffusion prior를 통과하면 모든 \(v_{*}\)가 텍스트 제약 조건과 일치하도록 일관된 생성을 얻을 수 있습니다. 반면, 긍정 및 부정 제약 조건은 가능한 광범위하게 유지하고자 diffusion prior를 통과하지 않습니다. 이에 따라 본 연구에서의 손실 함수는 다음과 같이 정의됩니다:
즉, 학습된 임베딩 v에서 생성된 샘플링된 이미지 임베딩 \(P(E_{y}(v_{*}))\)이 \(C_{neg}\)에 의해 정의된 텍스트 제약 조건에서 멀어지고 \(C_{pos}\)의 제약조건에 가까워지도록 합니다.
Regularization#
정규화는 제약 조건 집합이 클 때 특정 멤버로의 collapsing을 방지하는 데 사용됩니다. 부정적 제약에 대한 최대 유사도를 측정하는 추가 손실 함수를 사용하는데 아래와 같이 정의됩니다:
이 유사도 측정 방식은 전체 손실 함수에 통합되며, \(S(C,v_{*})\)와 평균 냄으로써 \(v_{*}\)에 가장 가까운 제약 조건에 더 큰 패널티를 부여합니다.

Fig. 422 훈련 과정 중 BLIP-2 모델을 사용하여 현재 개념에 가장 가까운 단어를 추론하고, 이를 제약 조건에 추가하는 과정을 거칩니다.#
Adaptive Negatives#
많은 부정적 제약 조건을 수동으로 적용하는 것은 힘들고, 광범위한 카테고리의 가장 관련성 높은 멤버들을 정확하게 대표하지 못할 수도 있습니다. 이를 해결하기 위해, 훈련 중 부정적 제약 조건 집합을 점진적으로 확장하는 adaptive scheme을 제안합니다. 생성된 이미지를 사전 훈련된 BLIP-2 VQA 모델에 질의하여 이미지에 현재 존재하는 카테고리의 멤버가 무엇인지 식별하도록 합니다. 이후 결과로 나온 인스턴스를 훈련의 나머지 부분에 대한 부정적 제약 조건에 추가합니다.

Fig. 423 여러 단계에 걸쳐 생성된 이미지 결과를 보여줍니다. 훈련 과정에서 부정적 제약 조건이 지속적으로 조정되고 확장되었음을 보여줍니다.#
Evolutionary Generation#
주어진 개념 셋에 대해 개념을 혼합하기 위해 먼저 각 개념에서 이미지를 생성하여 이미지 제약 조건 \(C_{im}\) 을 만듭니다. 각 이미지는 CLIP 이미지 인코더 \(E_{im}(c)\)를 통과하여 임베딩 세트를 생성합니다. 학습 가능한 개념 \(v_{mix}\)를 주어진 임베딩에 더 가깝게 만드는 수정된 손실 함수를 적용합니다.:
이 손실 함수는 생성된 개념이나 실제 이미지에 적용될 수 있으며, 창의적인 생성물의 계층ㅇ적 생성을 위해 반복적으로 적용될 수 있습니다. 또, 생성된 결과물에 대한 각 개념의 영향을 더 잘 제어하기 위해 가중치 항목이 추가적으로 적용될 수 있습니다.

Fig. 424 그림에는 훈련에 사용된 긍정적 개념이 왼쪽에 표시되어 있습니다. 이는 모델이 어떤 개념을 기반으로 창의적 이미지를 생성했는지를 알 수 있습니다. 모든 결과는 Adaptive Negative 기법을 활용했습니다.#

Fig. 425 ConceptLab이 제안한 다양한 이미지로 프롬프트와 Adaptive Negative 기법을 적용했습니다.#

Fig. 426 ConceptLab은 생성된 개념들을 혼합하여 새롭고 독특한 창조물을 반복적으로 학습할 수 있습니다. 그림의 가장 윗줄에서는 Adaptive Negative 기법을 적용하여 학습된 개념들을 보여줍니다. 이어지는 줄에서는 Evolutionary Generation 과정을 통해 얻어진 개념들을 보여줍니다.#
Experiments#
ConceptLab의 효과를 입증하기 위해 정성적 및 정량적 평가를 진행했습니다.
Result#
Creative Generation#
위 그림들에서 볼 수 있듯이 모든 결과는 Adaptive Negative를 적용하였고 훈련 시드를 달리하며 다양한 개념을 생성할 수 있는 능력이 있음을 볼 수 있습니다. 또, ConceptLab은 학습된 창의적 개념을 새로운 장면에 배치할 수 있습니다. 이 생성물들은 배경 변경, 스타일 변경, 새로운 창조등 다양하게 활용 가능합니다.

Fig. 427 ConceptLab을 활용한 Concept Mixing의 결과를 보여줍니다.#
Concept Mixing#
Concept Mixing은 다양한 실제 개념들의 독특한 특성을 합쳐 하이브리드 개념을 형성하는 방법을 보여줍니다. 이 방법은 오직 긍정적 제약 조건만을 활용합니다. 예를 들어, 첫 번째 줄에는 랍스터의 주요 특징(생상과 집게발)을 거북이의 특징(등껍질)과 융합하는 것을 볼 수 있습니다.

Fig. 428 위 그림은 ConceptLab에 의해 학습된 개념들이 여러 세대에 걸쳐 어떻게 발전하는지 보여줍니다.#
Comparisons#
Evaluation Setup#
ConceptLab은 Stable Diffusion2와 Kandinsky 2.1 두 모델과 함께 평가했습니다. Kandinsky의 경우, 더 유리한 결과를 위해 부정적 프롬프트는 Latent Diffusion Model이 아닌 Diffusion Prior Model에 적용했습니다.
Qualitative Comparisons#
ConceptLab은 긍정적 토근과 부정적 제약 조건 모두에 일관되게 맞춰질 수 있습니다. 즉, ConceptLab은 다중 제약 조건을 효과적으로 처리하고, 특정 개념에 대한 일관된 표현을 학습할 수 있는 능력을 갖추고 있습니다.
Quantitative Comparisons#
정량적 평가를 위해 각 방법이 긍정적 개념을 포함하며, 주어진 부정적 개념과 닮지 않은 이미지를 생성하는 능력을 측정했습니다. 평가에는 애완동물, 식물, 과일, 가구, 악기의 5가지 카테고리를 활용했습니다. 각 도메인에 세 가지 다른 부정적 개념 쌍을 고려하고, 각 조합에 대해 ConceptLab을 5개의 랜덤 시드로 훈련하여 총 75개의 학습된 개념을 얻었습니다. 각 학습된 개념에 대해 “A photo of a \(S_{*}\) 프롬프트를 활용하여 32개의 이미지를 생성했습니다. Stable Diffusionr과 kandinsky 모델에서는 부정적 프롬프트를 사용하고, 같은 긍정적 및 부정적 개념 쌍에 대해 160개의 이미지를 생성합니다. 측정 기준으로는 먼저 각 개념의 긍정적 유사성을 타겟 카테고리와의 CLIP 공간 유사성 계산을 통해 특정됩니다. 다음으로는 긍정적 제약과 부정적 제약 사이의 거리를 측정합니다. 이는 생성된 이미지와 모든 부정적 개념 사이의 최대 유사성 계산을 통해 이루어집니다. 결과적으로 ConceptLab은 5가지 모든 도메인에서 긍정적 CLIP 유사성에서 일관되게 우월한 성능을 보였고 타겟 카테고리에 속하는 이미지를 신뢰성 있게 생성했습니다. 또한, 부정적 거리 측정에서 ConceptLab은 모든 카테고리에서 Stable Diffusion을, 4가지 카테고리에서 Kandinsky를 능가했습니다.

Fig. 429 User Study#
Limitations#
Personalization과 유사하게, 학습된 개념을 포함하는 프롬프트를 사용하여 새로운 이미지를 생성하는 것이 항상 개념의 특성을 다양한 프롬프트에 걸쳐 유지하지는 못합니다. 또, 최적화 과정 자체가 항상 원하는 결과를 가져오지는 않습니다. “비행기”나 “물고기”와 같은 일부 클래스의 경우 ConceptLab은 창의적 개념을 생성하는데 여전히 어려움이 있습니다. 이는 BLIP-2에 의해 생성되는 부정적 제약과 관련이 있습니다.

Fig. 430 Limitations#
Conclusion#
본 논문에서는 text-to-image diffusion model을 활용하여 창의적 생성을 위한 새로운 접근 방법을 소개했습니다. 주어진 광범위한 카테고리에 속하는 새로운 개념을 학습하기 위해 Diffusion Prior 모델 사용을 제안했습니다. 또, Prior Constraints라는 긍정적 및 부정적 제약 조건들을 diffusion prior 출력에 적용했습니다. 최적화 과정에서는 VQA 모델을 활용하여 독특하면서도 기존 멤버들과의 명확한 구별을 보장했습니다. 이후 실험을 통해 본 방법의 효과성을 입증했으며 시각적으로 다양하고 매력적인 개념을 생성할 수 있었습니다.