Information
Title: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning (SIGGRAPH 2024)
Reference
Code: zju3dv/Coin3D
Project Page : https://zju3dv.github.io/coin3d/
Author: Donggeun Sean Ko
Last updated on January. 07, 2025
Coin3D#
1. Introduction#

Fig. 809 Overview of Coin3D#
“사용자 친화적인” & “제어 가능”한 3D assets 생성 프레임워크는 3가지 특성을 가져야 한다고 주장함
3D Controllable: Basic shape를 이용해서 간단하고 쉽게 원하는 형태를 만들 수 있어야 됨
Flexible: Interactive하게 (UI 등)을 활용하여 다양한 결과물을 만들 수 있어야 됨 (간단)
Responsive: 중간 결과물 및 빠른 결과물을 만들 수 있게 해야 됨 (fast inference time)
Overall#
Coin3D Input Condition (전처리)
3D-Aware Conditioned Generation
Preview and Reconstruction
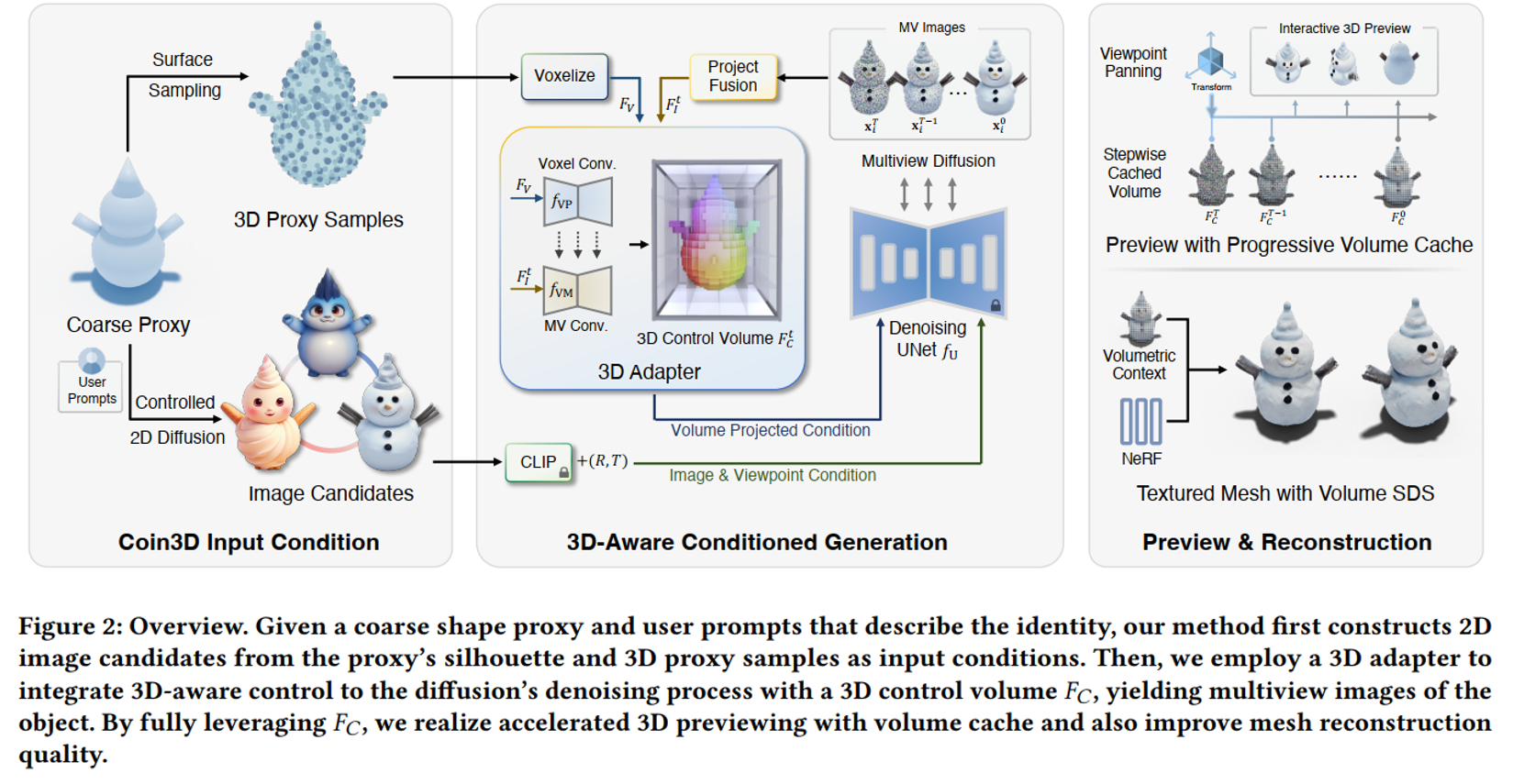
Fig. 810 Overview of Coin3D Main Architecture#
3. Method#
3.1: Proxy-Guided 3D Conditiong for Diffusion#
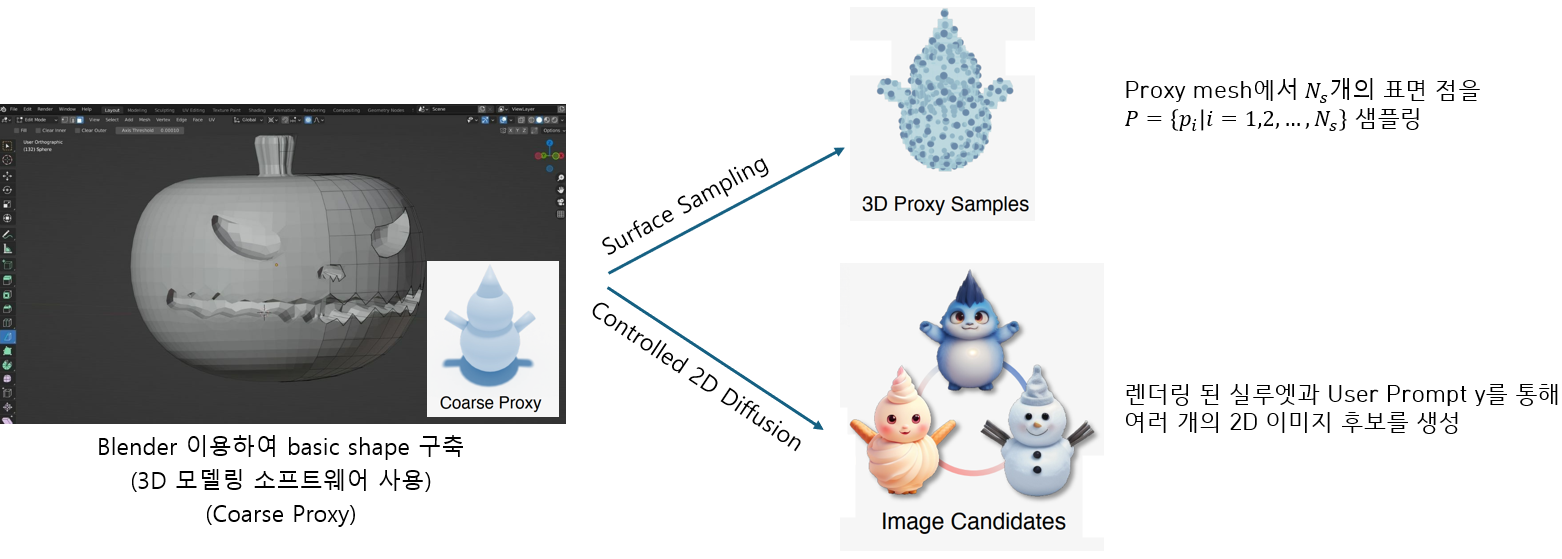
Fig. 811 Proxy-based Initial Condition Generation#
3D Proxy as an initial condition (Preprocessing)
Coarse shape \(P\)와 prompt \(y\)로 \(N_v\)를 다양한 camera pose에 대하여 예측
Where:
\(N_v\): consistent image
\(P\): coarse shape
\(f\): Multiview diffusion-based generator
\(y\): prompt
\(\mathbf{c}\): camera poses
3.2 3D Aware Conditioned Generation#

Fig. 812 3D-Aware Conditioned Generation#
3D Proxy Sample을 Voxelize를 통해 Voxel Grid \(F_v\) 생성
Multiview Image 생성
2-1. Image Candidates를 Clip + (Rotation, Translation)로 Denoising U-Net condition input으로 입력
2-2. Volume Projected Condition도 입력 (학습)
MV Images → Project Fusion을 통해
multiview feature volume, \(F_l^t\) 생성3D Convolution (\(f_{VP}\))을 통해 intermediate feature를 MVConv
(3DConv intermediate layer)에 계층적으로 추가\(F_c^t = f_{VM(1 \dots N)}(F_l^t) + f_{VM(1 \dots N)}(f_{VP}(F_v)_{1 \dots N})\)
3D control volume 완성!
3D Control Volume을 다시 \(f_u\)에 넣어 MV image 생성
3.2.1 Training Pipeline of 3D Aware Conditioned Generation#
(Preprocess) 각 학습 데이터를 MV image와 균일하게 샘플링된 coarse proxies로 변환
(Training) \(B\)개의 condition 및 target image를 무작위로 sampling하고, 대응하는 coarse proxy points를 샘플링함
(Training) \(B\) timestamp with Gaussian Noise도 샘플링
\(\epsilon_{(1:B)} \sim \mathcal{N}(0, 1)\)아래의 loss를 이용하여 추가된 noise를 network \(\epsilon_\theta\)를 통해 예측
Loss Equation#
3.3. Interactive Generation Workflow#
3.3.1. Proxy-bounded part editing#
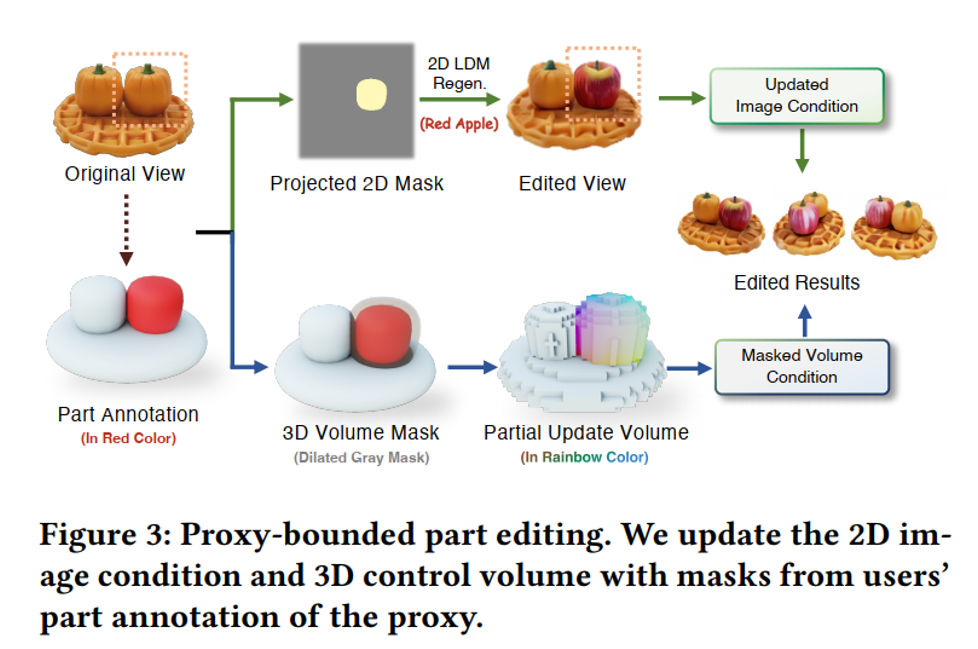
Fig. 813 Proxy-bounded Part Editing#
MV diffusion은 3D volume & 2D image에 conditionin이 되어 있기 때문에,
이런 condition을 고려해서 편집을 해야하는 게 간단하지 않음.따라서, two-pathway condition editing scheme을 구성함:
Projected 2D Mask → 2D Latent Diffusion Model
3D Volume Mask → Partial Update Volume
2D Image condition + 3D masked volume condition으로 “3D image editing”을 진행
Where:
\(\hat{F}_C^t\): updated volume
\(\tilde{F}_C^t\): predicted volume at \(t\)
\(F_C^t\): cached original volume
3.3.2. Interactive Preview with Progressive Volume Caching#
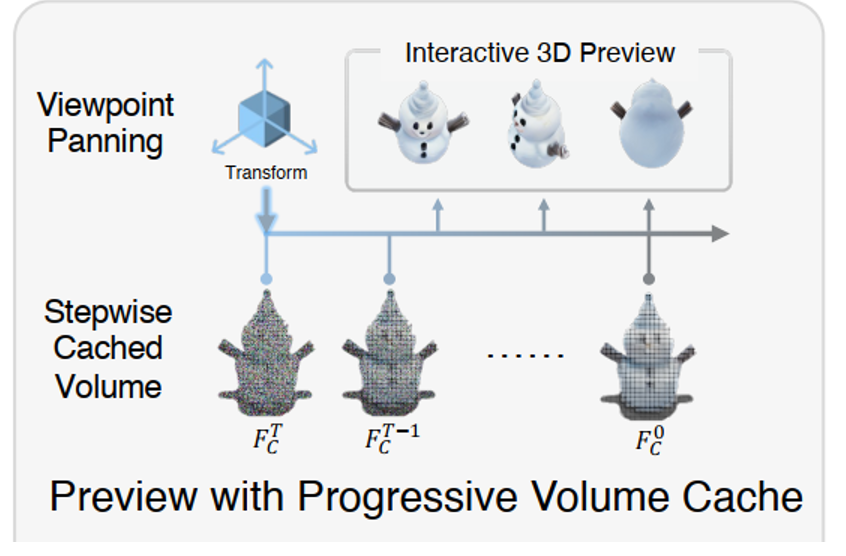
Fig. 814 Interactive Preview with Progressive Volume Caching#
목표: Interactive preview를 통해 수정된 결과를 몇 초 내에 확인하고
임의의 시점에서 효과를 검사 및 수정이 가능Progressive Volume Caching
각 timestamp \(t\)에서 최신 3D Control Volume, \(F_C^t\)를 캐싱함
이를 \(F_C^t\)를 반복적으로 계산할 필요가 없음
Viewpoint Panning
Preview 단계에서 user’s viewpoint poses \(c'\)를 MV diffusion viewpoint condition에 전달
이를 통해 원하는 시점 (arbitrary viewpoints)에서 프리뷰 이미지를 렌더링할 수 있음
핵심
Cache를 이용하여 불필요한 연산을 제거하고 Cache에서 저장된 3D adapter rendering output을 이용하여 여러 preview를 생성
3.4 Volume-Conditioned Reconstruction#
3.4.1. Preview & Reconstruction#

Fig. 815 Preview and Reconstruction#
기존 Multiview images를 활용한 3D Reconstruction은
viewpoint가 적어 unexpected geometry가 만들어져 결과물이 뭉개지거나 한계점이 보임3D-aware context from 3D control volume을 활용해 3D Reconstruction quality를 올림
개인적인 의견: 더 정교한 3D 물체 + Multiview가 있으니 더 정교한 결과물이 만들어진다? 라고 보여짐…
Propose Volume SDS
integrating 3D control prior from voxelized feature \(F_C^t\) to the field’s backpropagation
where \(w(t)\) is the weighting function from DreamFusion.
4. Results#

Fig. 816 Qualitative Results#
프록시 기반 생성 방법 비교#
Wonder3D와 SyncDreamer 디테일 비교:
더 높은 품질의 멀티뷰 이미지:
Coin3D 결과물은 다양한 시점에서 일관성 있는 이미지를 생성하며, 왜곡이나 아티팩트가 최소화됨.
반면, Wonder3D와 SyncDreamer는 복잡한 객체(예: 거북이와 오리)에서 기하학적 불일치 또는 텍스처 불일치를 보임.
더 나은 텍스처 메쉬:
Ours는 더욱 현실적이고 세밀한 텍스처를 재구성하며, 부드러운 전환과 정밀한 정렬을 유지.
Wonder3D는 텍스처 불일치가 나타나고, SyncDreamer는 단순화된 텍스처를 생성하는 경향이 있음.
객체 형태의 보존:
Ours는 입력된 coarse shape를 정확히 보존하면서 세부 정보를 강화함.
다른 방법론은 재구성 중 형태 왜곡(예: 의자가 휘거나 일그러짐)이 나타남.
더 자연스러운 출력:
Ours의 출력은 미적 품질이 높고 자연스러운 결과물을 제공하며, 복잡한 텍스처(예: 도넛)에서도 특히 돋보임.
Wonder3D와 SyncDreamer는 인공적이거나 세부 사항이 부족한 경우가 많음.
주요 관찰점#
Coarse Shapes: 모든 방법이 비슷한 코스 쉐이프에서 시작하지만, Ours는 이를 가장 잘 개선함.
멀티뷰 이미지: Ours는 명확하고 일관된 멀티뷰 이미지를 생성하여 정확한 3D 재구성을 가능하게 함.
텍스처 메쉬: Ours는 현실적인 텍스처를 생성하며, 경쟁 방법론보다 높은 수준의 사실성을 보여줌.
요약:#
(a) Ours: 멀티뷰 이미지의 일관성과 텍스처 메쉬 품질에서 우수함.
(b) Wonder3D: 기하학적 일관성과 텍스처 세부 정보에서 어려움.
(c) SyncDreamer: 텍스처가 단순화되고 형태가 불일치함.
4.2 Quantitative Results#
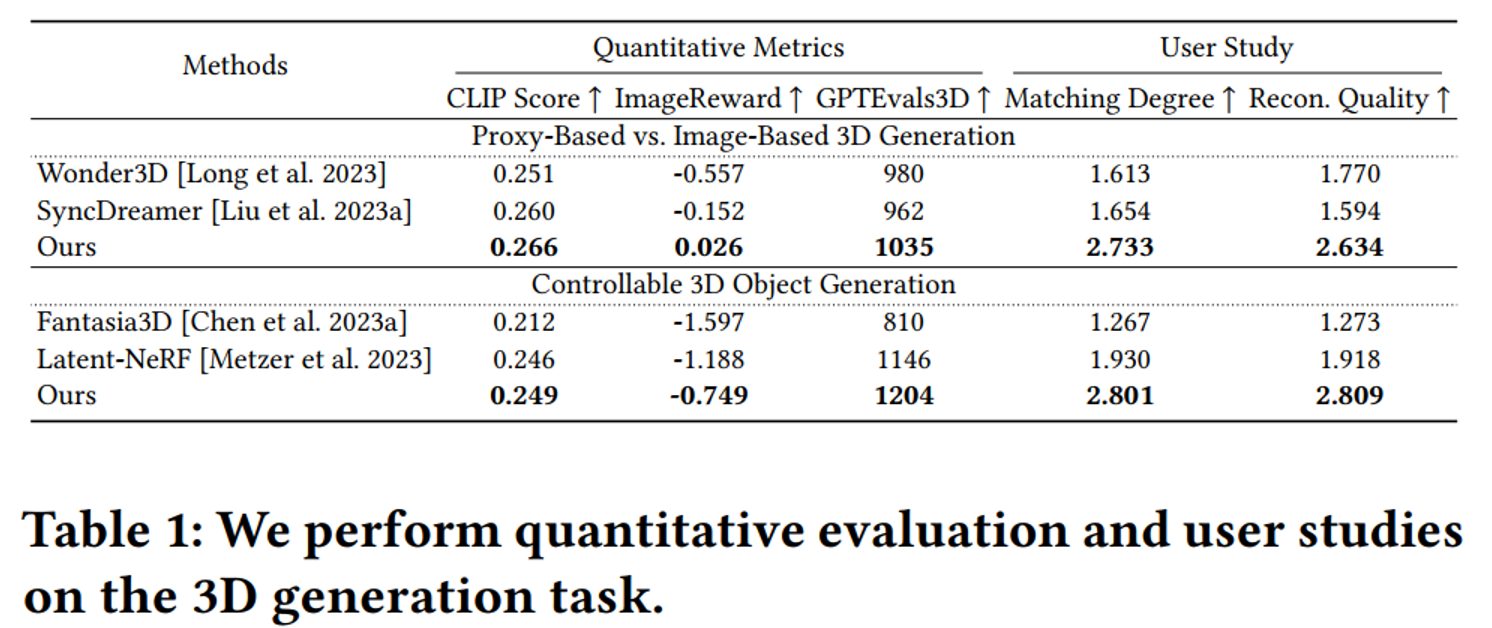
Fig. 817 Quantitative Results#
TEXTure (Richardson et al., 2023) user study guideline 채택
30명 사용자에게 35개의 test case를 무작위 순서로 제시한 후
perceptual quality & content matching degree (w.r.t the given image or text prompts)를 기준으로 정렬 및 점수 배정3점 Best 기준으로 함.
5. Ablation Study#
Volume SDS#

Fig. 818 Ablation Study on Volume SDS#
Volume SDS Loss를 추가시 렌더링에 artifacts가 없으며 더 스무스하고 자연스러운 텍스쳐를 바탕으로 생성함
Proxy Condition & 3D Mask Dilation#
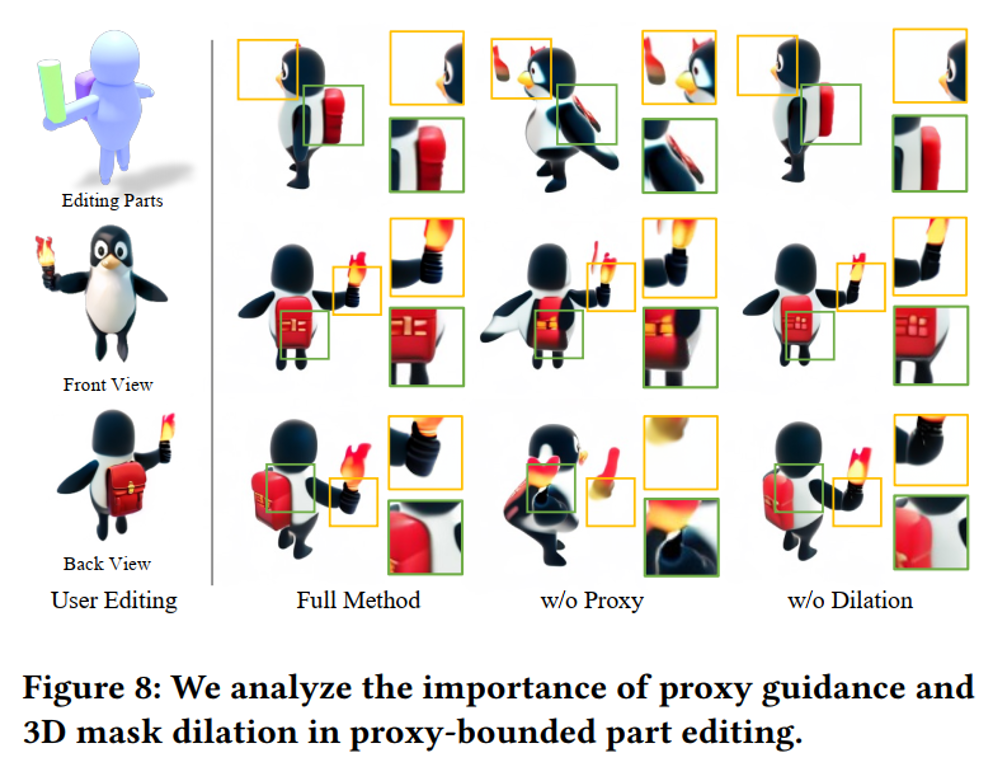
Fig. 819 Ablation Study on Proxy Condition and 3D Mask Dilation#
Proxy 하고 Dilation이 없을 시 rendering이 고르게 안되는 현상이 생김.
Full method는 proxy와 dilation을 둘다 사용했으며
6. Conclusion#
Basic block만 있으면 원하는 3D 생성을 할 수 있음
Flexible 하고 UI-friendly 함 (ComfyUI 등)
타 모델들에 비해 3D 결과물이 더 좋음