Information
Title: Muse: Text-To-Image Generation via Masked Generative Transformers
Reference
Code: X
Author: Jun-Hyoung Lee
Last updated on Mar. 25. 2024
Muse#

Fig. 451 Figure 1#
Muse: T2I transformer model + Masked Modeling
diffusion, autoregressive model 보다 효과적인 성능을 냄
discrete token space 에서 masked modeling 방식으로 학습
pretrained LLM(T5-XXL) 으로 부터 추출된 text embedding이 주어지고, 랜덤하게 masked image token 을 예측하는 방식으로 학습
Imagen, DALL-E 2 와 비교할 때, sampling iteration이 적어 빠른 inference 수행 가능
LLM 을 사용해 fine-grained 한 정보를 추출하여 high-fidelity 이미지 생성을 할 수 있고, 시각적 concept(object, spatial 관계, 자세, 등)을 더 잘 이해할 수 있음
Muse-900M, CC3M 에서 SOTA 달성, FID 6.06
Muse-3B, zero-shot COCO 에서 FID 7.88 달성, CLIP score 0.32
따로 파인튜닝 없이 inpainting, outpainting, mask-free editing 이 가능함
1. Masked modeling#
[22.02] MaskGIT: Masked Generative Image Transformer
CVPR 2022, Google Research
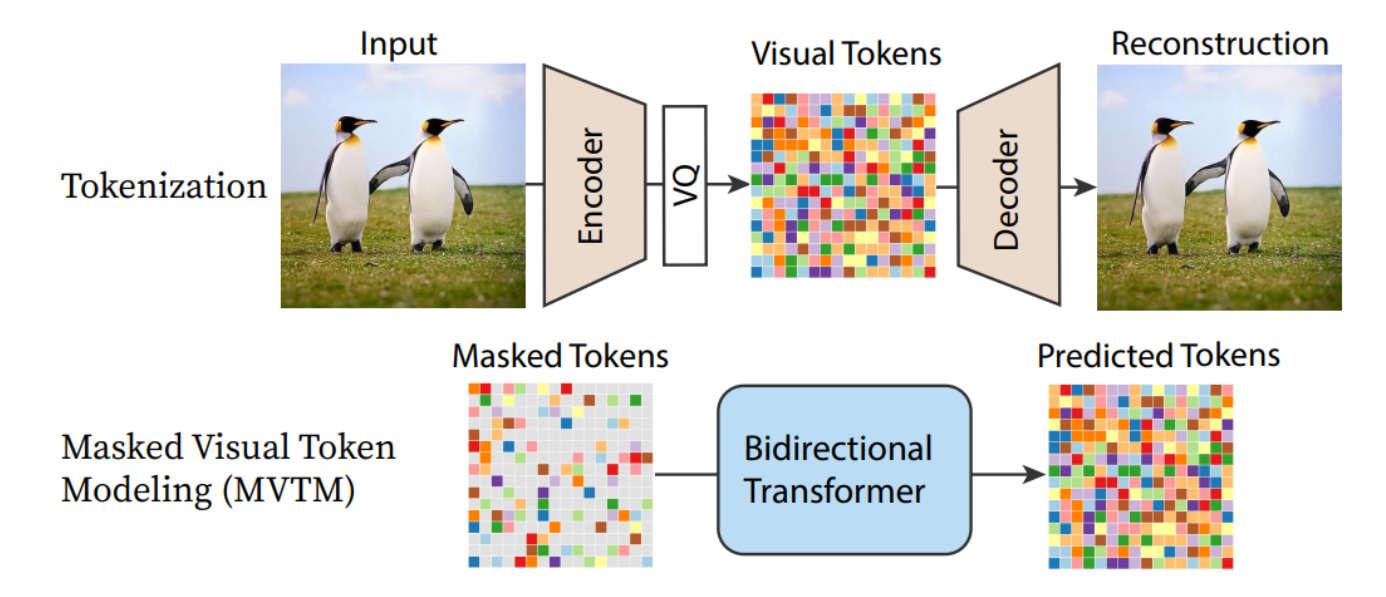
Fig. 452 maskgit 1#
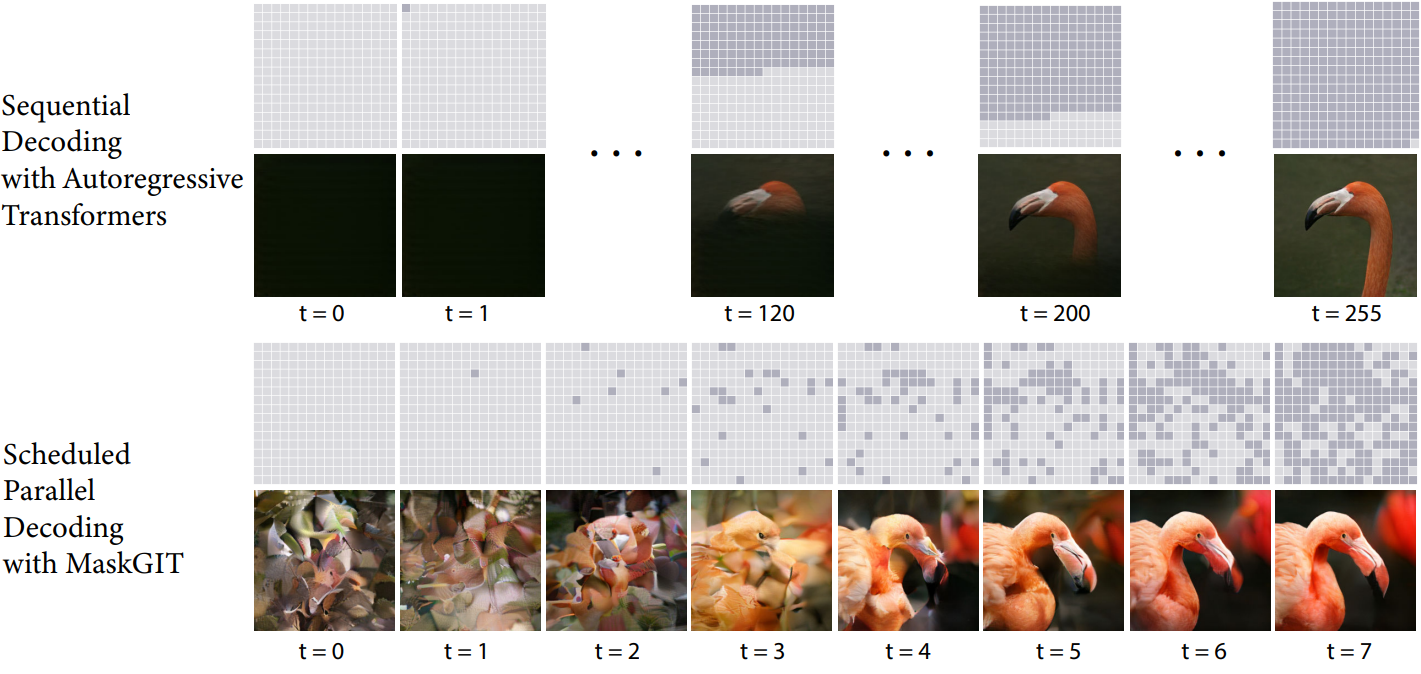
Fig. 453 maskgit 2#
VQGAN 사용, non-autoregressive 디코딩 방식
inference 시에 모든 마스킹된 토큰을 예측하지만, 신뢰도가 높은 토큰만 실제 디코딩됨
따라서 autoregressive 모델의 256 step → 8 step 으로 줄여 inference 속도가 향상
2. Model Architecture#
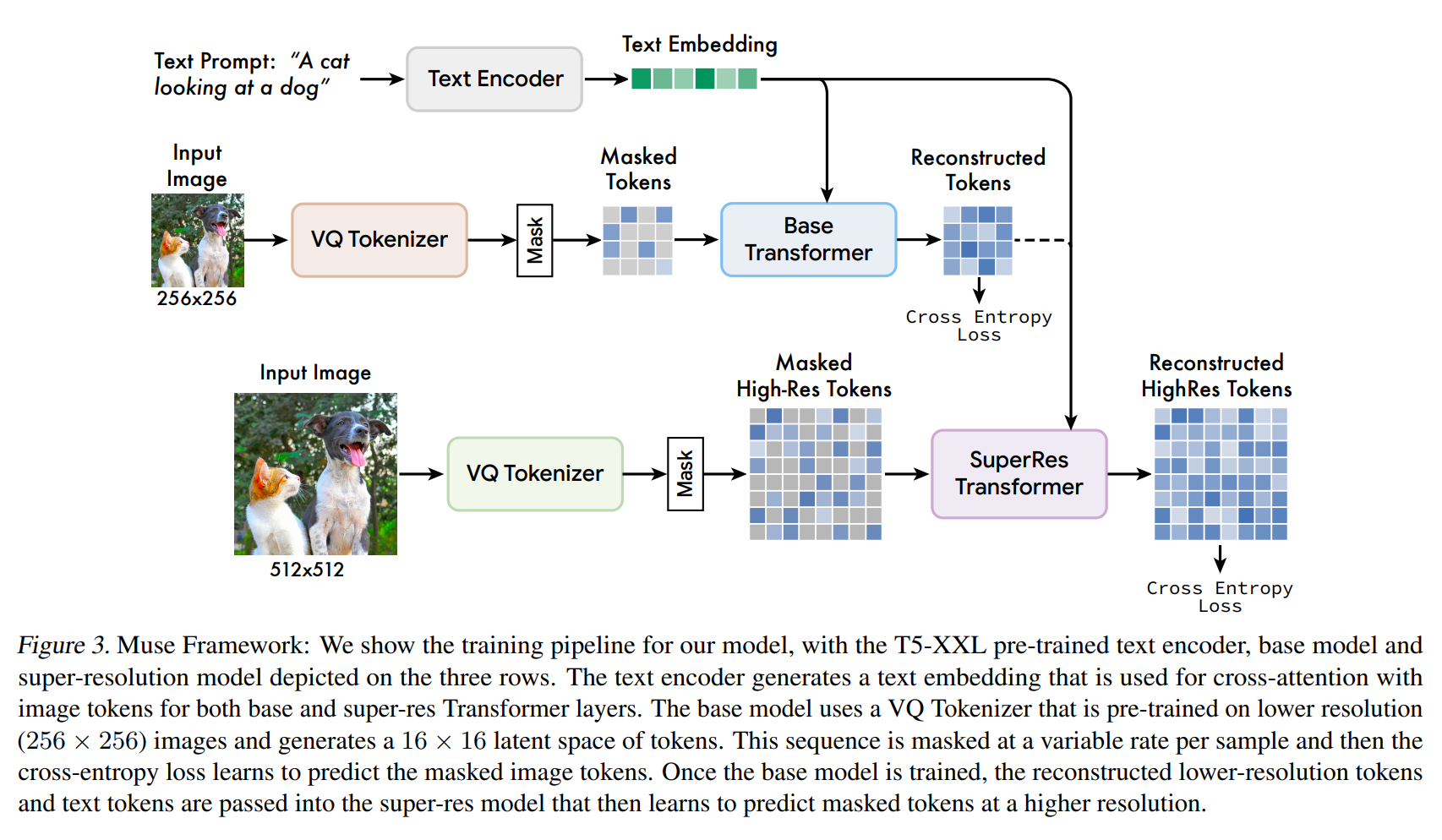
Fig. 454 Figure 3#
VQGAN tokenizer model 사용
input image 가 discrete token 으로 인코딩되고, 그 후 디코딩되어 input 이미지와 유사하게 잘 복원되는 모델
두 개의 VQGAN 사용 (256x256 저해상도 + 512x512 고해상도)
첫 학습은 256x256 저해상도(16x16 latent) 학습
이후 512x512 고해상도(64x64 latent) 학습 진행
Masked image model 사용
Muse 파라미터의 대부분이 masked image model 파라미터로 구성
unmaked 토큰과 T5XXL text embedding 을 condition으로 masked 저해상도 토큰에 대해 예측 진행
“Super-res” transformer model 사용
T5XXL text embedding 을 condition으로 저해상도 토큰을 고해상도 토큰으로 바꾸는데 사용
2.1. Pre-trained Text Encoders#
Imagen 에서 pretrained LLM 사용하면 효과적인 high-quality 의 이미지 생성 가능
풍부한 visual, semantic 정보를 추출할 수 있는 T5-XXL 사용
objects (nouns), actions (verbs), visual properties (adjectives), spatial relationships (prepositions)
Muse 가 이러한 정보를 이미지 생성을 위한 LLM embedding 에서 잘 mapping 을 할 수 있을 것이라고 가정
Linearly mapping from image to text space 에서 선행 연구 진행
인코딩 과정
4096 차원의 embedding vector를 얻음
linearly projection 진행되어 base, super-res transformer에 입력되게 차원을 맞춤
2.2. Semantic Tokenization using VQGAN#
VQGAN
encoder + decoder
encoder feature 를 vector quantization 이 진행된 후, codebook 으로 부터 매핑을 통해 디코딩이 진행
다른 해상도의 이미지를 인코딩할 수 있도록 encoder와 decoder 모두 convolutional layer 로 구성
256x256 픽셀 이미지에 맞는 VQGAN 모델(base model)과 512x512 픽셀 이미지에 맞는 VQGAN 모델(super-res model) 구성
Taming transformers for high-resolution image synthesis 에서 인코딩된 discrete 토큰이 low level noise를 무시하면서 high level semantic 함을 더 잘 capture 한다는 것을 연구 진행
이 때문에, cross-entropy loss 를 통해 masked 토큰을 예측하는데 사용할 수 있게됨
2.3. Base Model#
base model
projected T5 embedding + 이미지 토큰을 입력으로 한 masked transformer 로 구성
text embedding 은 unmasked, 이미지 토큰은 랜덤하게 masking 진행 → [MASK] 토큰으로 교체
이미지 토큰을 embedding 으로 선형적으로 mapping 진행(transformer 의 input/hidden 사이즈에 맞게) + positional embedding 도 포함
transformer layer는 self-attention, cross-attention, MLP 블럭이 포함
MLP 는 masked image embedding 을 logit 값으로 변경하는데 사용되고
cross-entropy loss 는 ground truth 토큰과 함께 오차를 계산함
학습 때, base model은 각 step 마다 모든 masked tokens를 예측하지만,
inference 에서는 퀄리티를 증가하기 위한 iterative 방식으로 mask 예측 진행
2.4. Super-Resolution Model#
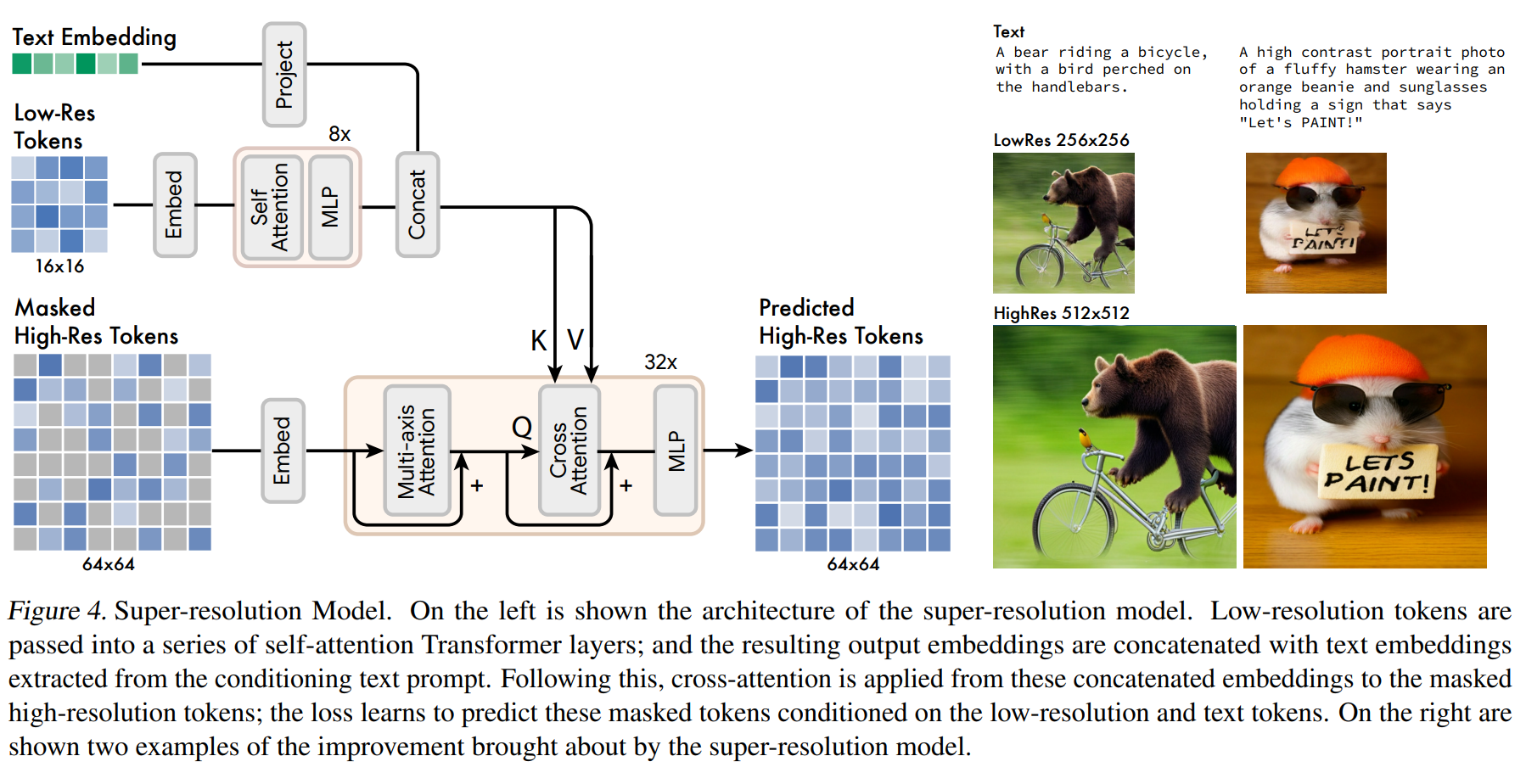
Fig. 455 Figure 4#
바로 512x512 로 예측하도록 모델을 구성했을 때, low level detail 에 더 포커싱되어 학습이 진행됨. → 따라서 위의 그림과 같이 계층적으로 설계했음
base model은 16x16 latent map 을 생성하고, super resolution 모델이 base latent map 을 64x64 latent map 으로 upsampling 함
base 모델이 학습이 완료되면, 그 이후에 super resolution 모델 학습 진행
Architecture
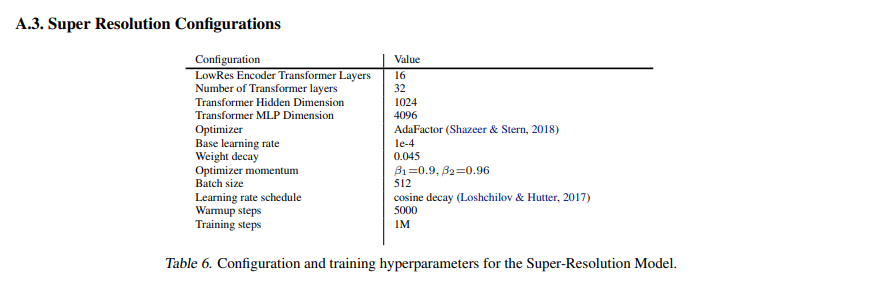
Fig. 456 Table 6#
2.5. Decoder Finetuning#
디테일을 높이기 위해 residual layer를 더 추가하고 channel 늘림
residual layer: 2개 → 4개, channel: 128 → 256
encoder weight, codebook, base, super-res transformer 모델은 freezing

Fig. 457 Figure 13#
해당 그림에서는 표지판이 더 finetuned decoder 가 복원이 잘 됐음
2.7. Classifier Free Guidance#
이미지 생성 퀄리티와 text-image alignment 향상을 위해 도입
학습 때, 랜덤하게 10% 만 text conditioning 을 제거
inference
\(\ell_g=(1+t) \ell_c-t \ell_u\)
\(l_c\): conditional logit / \(l_u\): unconditional logit / \(t\): guidance scale
CFG 는 diversity ↔ fidelity 의 trade-off 관계
Muse 에서는 t 를 선형적으로 증가시키는 샘플링 과정을 거쳐 diversity 의 한계를 극복
초반에는 guidance 가 없거나 낮게 해서 logit 값을 설정하고, 후반에는 conditional prompt 가 가능하게 많은 가중치를 주게 된다.
unconditional logit → negative prompt 로도 사용 가능
2.8. Iterative Parallel Decoding at Inference#
Muse 의 시간 효율성
parallel decoding 으로 인해 한 번의 foward 연산으로 multiple token 을 예측하는 방식으로 동작함
Markovian 속성: 많은 토큰이 주어진 다른 토큰에 대해 conditionally independent 함 → parallel decoding 가능
Maskgit 논문 에서 Decoding 은 cosine schedule 에 의해 수행됨
해당 step 에서 예측되는 가장 높은 신뢰도의 masked 토큰을 선택해 decoding 진행됨
그 후 decoding 된 것은 masking 이 해제되는 방식
이러한 절차를 따라서, Muse 에서는 base 모델의 256 토큰은 24 step 을 사용하고, super-res 모델의 4096 토큰은 8 step 만 사용
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation 에서는 256 or 4096 step 이 필요하고,
diffusion 모델에서는 수백번의 step 이 필요한 것에 비해 Muse 가 빠른 inference 를 수행 가능

Fig. 458 Figure 5#
3. Results#
Imagen dataset
460M text-image pairs
train step: 1M
train time: 1 week
batch size: 512 on 512-core TPU-v4 chips
Adafactor optimizer

Fig. 459 Figure 6#
cardinality: 동일한 객체를 여러 번 생성할 때, Muse 는 크기, 색상, 회전된 모습

Fig. 460 Figure 7#
정량적 평가
:::{figure-md}
 Table 6
:::
Table 6
:::
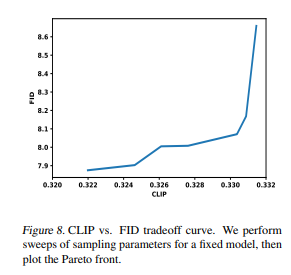

Contribution#
FID, CLIP score 기반으로 text-to-image 모델에 대한 SOTA 를 달성
이미지 생성 퀄리티, 다양성, text prompt와의 alignment 측정했음
quantized 이미지 토큰과 parallel decoding 으로 인해 빠른 inference 가 가능
inpainting, outpainting, mask-free editing 을 포함한 zero-shot editing 가능
Q&A#
Muse 와 같은 transformer 기반의 generation 모델에서는 어떻게 diversity 한 결과를 가져올 수 있나요?
아무래도 Muse 는 random latent 에서 생성하는 것이 아니라 text-to-image 모델이라, text 에 따라서 다양한 이미지 생성 결과가 나타날 수 있을 것 같습니다.
Muse 는 결국 GAN 모델인가요?
기준점이 어떻냐에 따라 GAN 이다, 아니다, 라고 정하기 어려울 것 같습니다. VQGAN을 사용해서 GAN이라고 생각할 수 도 있고, GAN 처럼 random latent 결과에 따라 이미지 생성이 달라질 수 있는 관점에서 생각하면 아니다라고 말할 수 있을 것 같습니다.
Token 은 어떤 의미를 갖나요?
VQGAN에서 input 이미지를 인코딩하고, vector-quantization 과정을 거쳐 압축 후, codebook의 값을 가져와 feature를 구성하는데요, 이때 feature에 포함되어 있는 하나의 포인트에 해당하는 것이 token이라고 생각하시면 될 것 같습니다.
텍스트 프롬프트를 넣었을때 실제 이미지 생성은 어떻게 이뤄지나요? Inference에서는 입력 이미지가 없는데 base transformer에 입력 이미지에 대한 masked token대신 뭐가 들어가게 되나요?
실제 inference 과정에서는 input 이미지가 없기 때문에 모두 마스크된 형태로 입력되게 됩니다. text prompt 의 condition 에 따라 각 step을 거쳐 decoding 이 수행됩니다.
text embedding이 어떻게 objective function 수식에 들어가나요?
base transformer 에 대해 text embedding 값이 key, value로 입력되어 cross-attention 이 수행되게 됩니다. 그렇게 예측된 feature와 GT의 feature 끼리 cross entropy loss를 통해 마스크 예측할 수 있는 base transformer 가 학습이 됩니다.