SOLO - ECCV 20
Contents
SOLO - ECCV 20#
Information
Title: SOLO: Segmenting Objects by Location, ECCV 2020
Reference
Review By: Chanmin Park
Last updated on Jun. 4, 2022
Problem statement#
Instance segmentation의 pixel level로 image내의 모든 object를 segmentation 하는 것이 목적이다.
Detection, classification, segmentation등 여러 기술들이 합쳐져 있다 보니 semantic segmentation보다 challenge 함.
일반적으로 instance segmentation은 크게 두가지 그룹으로 구분할 수 있다.
Top-down(detect-then-segment) Method: Detection을 먼저 수행하고 bounding box에서 각 instance의 instance mask를 구함
Bottom-up method: 각 pixel에 대응되는 embedding vector간의 affinity relation을 학습하는 방법

Fig. 47 Comparison of the pipelines of Mask R-CNN and the proposed SOLO (source: arXiv:1912.04488)#
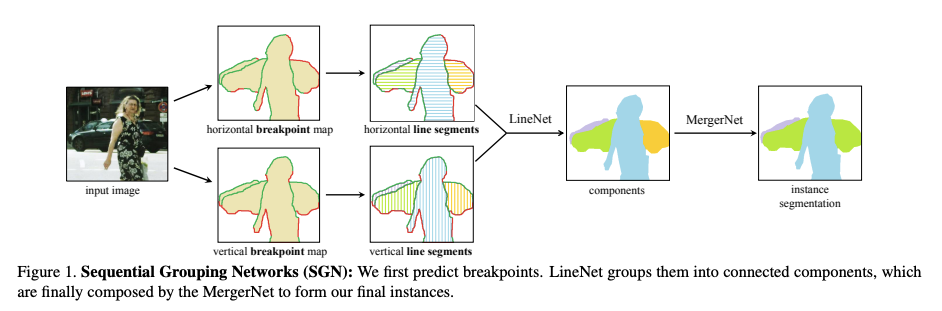
Fig. 48 Sequential Group Networks (SGN) (source: SGN: Sequential Grouping Networks for Instance Segmentation, ICCV 2017)#
하지만 위의 방식들은 여러 step 구성되어 있으며, indirect 한 방법으로 detection의 성능에 의존성이 있거나, embedding learning 또는 group processing에 의존하는 문제가 있다.
Contribution#
별도의 bounding box 및 pixel간의 pairwise relation 정보 없이 full instance mask annotation을 supervision으로 바로(directly) instance mask를 구하는 framework을 제안함.
이는 COCO validation subset에서 instance간의 관계를 분석, 이를 활용하여 SOLO(segment objects by locations) framework 을 제안함.
영상 내의 instance가 서로 다른 center postion을 가지거나 크기가 다름을 확인함 → Instance categories의 개념을 도입
S x S gride cells 생성 후 instance의 center location을 이용한 instance segmentation 수행 (anchor box 사용하지 않음)
Segmentic segmentation에서 주로 사용하는 FCN을 적용하여 각 pixel location의 instance category score를 dense하게 도출함.
Proposed Method#
FPN(Feature Pyramid Network) backbone으로 feature를 추출한 후 각 grid의 probability를 도출하는 Category branch와 각 instance의 mask를 추정하는 Mask branch로 구성됨.
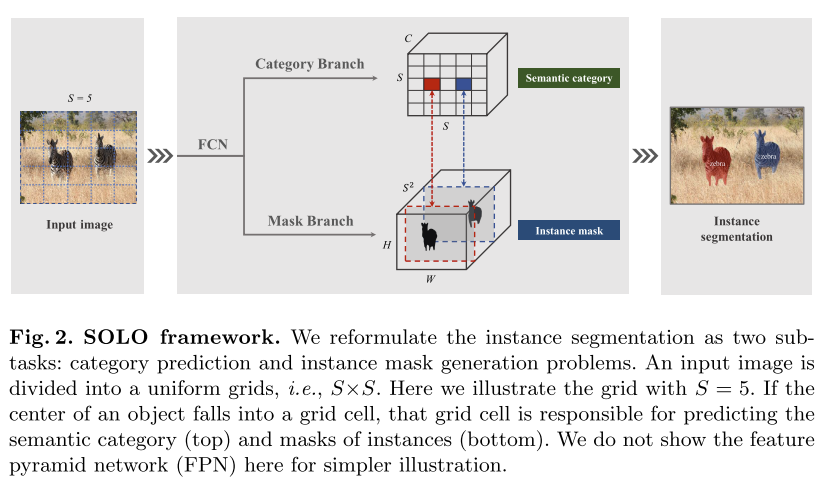
Fig. 49 SOLO framework (source: arXiv:1912.04488)#
1. Semantic Category#
COCO validation subset에 존재하는 36,780개 object 중 98.3% object pair의 center distance가 30 pixel 이상이고, 나머지 1.7%의 40.5%의 size ratio가 1.5배 이상임을 확인
결과적으로 영상에 존재하는 두 instance는 서로 다른 center location을 가지거나, 서로 다른 크기를 가짐을 알 수 있음
Input image를 \(S\times S\)로 분할하였을 때, 각 grid는 개별적인 instance에 속한다고 가정할 수 있음.
Input image를 \(S\times S\) grid로 분할하고 각 grid별로 class probability를 구함. Category branch는 \(S\times S \times C\) 의 output space를 가지도록 구성함.
2. Instance mask#
Semantic category의 positive grid cell의 instance mask를 추정.
Branch의 output은 분할한 각 grid에 대응되는 mask로 구성되어 있음
입력 영상을 \(S\times S\)로 분할하고 semantic category를 구한 경우 mask branch는 \(S^2\) channal의 output으로 구성됨.
k번재 channel의 경우 \((i,j)\) grid의 mask에 대응됨. (k = i * S + j)
Instance mask를 prediction하기 위해 FCN(Fully covolutional network)를 적용하는데, convolution operation은 spatially invariant한 특성을 가짐. (classification task에 적합하나, pooling 또는 stride 연산 과정에서 shift invariant 한 특성을 가짐.)
이를 극복하기 위해 CoordConv을 적용하여 coordinate aware한 instance mask를 추정함. (appendix 1.)
Interpolation, adaptive-pooling, region grid-interpolation를 적용하여 \(S \times S \times C\) resolution의 output을 얻고 대해 loss를 적용함.
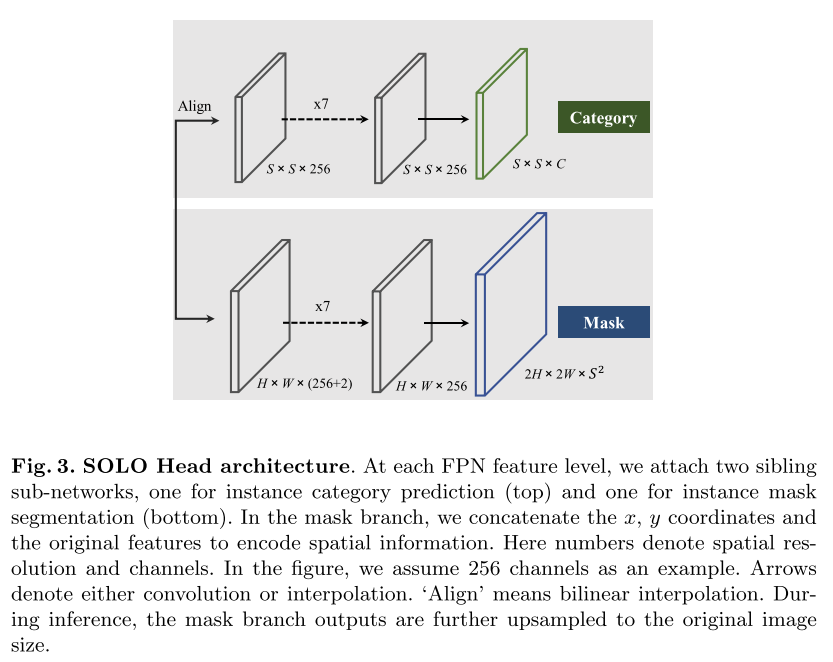
Fig. 50 SOLO Head architecture (source: arXiv:1912.04488)#
3. SOLO learning#
Label Assignment
Category prediction branch의 학습을 위해 \(S \times S\)로 분할된 각 grid의 object category probability가 필요함. 본 논문에서는 만약 \((i,j)\) 번째 grid가 어떤 ground truth mask(한개의 instance만 포함됨) center region에 포함된다면, positive sample로 간주함.
Center sampling은 최근 object detection task에 널리 적용되며, 유사하게 mask category classification에 적용함.
mass center \((c_x,c_y)\), widhth \(w\), height \(h\)가 주어졌을 때, center region은 constant scale factor \(\epsilon\)으로 제어됨
\(\epsilon=0.2\)로 설정 시 평균적으로 3개의 positive sample을 얻을 수 있음.
Positive sample에 대한 binary mask의 경우 각 grid cell에 대해 생성함. mask의 순서는 row-major order로 구성되어도 mask prediction branch 학습에 지장이 없다고 주장함.
Loss Function
\[ L=L_{\text{cate}}+\lambda L_{\text{mask}} \]Semantic Category classification을 위한 loss \(L_{cate}\)는 일반적인 focal loss를 적용함.
Mask prediction 을 위한 loss는 다음과 같이 정의된다.
\[ L_{\text{mask}}=\frac{1}{N_{pos}}\sum_k \mathbb{1}_{\{\mathbf{P}_{i,j}^{*}>0\}}d_{\text{mask}}(\mathbf{m}_k,\mathbf{m}_k^{*}) \]여기서 indices \(i=\lfloor k/S\rfloor\), \(j=k\) mod \(S\) …
\(d_{mask}\)는 Binary Cross Entropy (BCE), Focal Loss, Dice Loss를 적용할 수 있다. 최종적으로 논문에서는 효율적이고, 안정적인 학습을 위해 Dice Loss를 적용한다.
\[ L_{\text{Dice}}=1-D(\mathbf{p}, \mathbf{q}) \]\(D\)는 dice coefficient로 다음과 같이 정의된다.
\[ D(\mathbf{p},\mathbf{q})=\frac{2\sum_{x,y}(\mathbf{p}_{x,y},\mathbf{q}_{x,y})} {\sum_{x,y}\mathbf{p}_{x,y}^2+\sum_{x,y}\mathbf{q}^2_{x,y}} \]여기서 \(\mathbf{p}_{x,u}\)와 \(\mathbf{q}_{x,u}\)는 \((x,y)\) 위치에서의 예측된 softmask \(\mathbf{p}\)와 ground truth mask \(\mathbf{q}\)의 value이다.
4. Inference#
입력 영상에 대해 FPN을 이용하여 category score \(\mathbf{p}_{i,j}\)와 각 grid에 대응되는 mask \(\mathbf{m}_k\)를 얻음
Threshold를 0.1로 적용하여 confidence가 낮은 grid를 제외시킴
추정된 mask(soft mask)를 0.5 threshold 적용하여 이진화 함.
foreground pixel에 대한 soft mask의 평균으로 정의되는 maskness 계산하고,
\[ \text{maskness}=\frac{1}{N_f}\sum_{i}^{N_f}\mathbf{p}_i, \text{ where } N_f \text{ is number of FG pixels} \]classification score와 곱하여 최종 confidence score를 계산함.
Experiments#
1. Implementation Details#
Optimization: Stochastic gradient descent (SDG), synchronized SGD over 8 GPUs
Batch Size: 16
Learning Rate
초기 learning rate는 0.01로 설정되며, 27 epoch에서 10으로 나누고(lr=0.001), 33번때 epoch에서 다시 한번 10으로 나눈 값을 사용함 (lr=0.0001).
Weight decay 0.0001, momentum 0.9를 적용함.
ImageNet Pre-trained weight 적용
짧은 image side의 크기가 640~800 pixel 사이로 random하게 sampling하는 scale jitter를 적용함.
2. Main Result#
Test Dataset: MS COCO instance segmentation benchmark, 5k val2017 split.
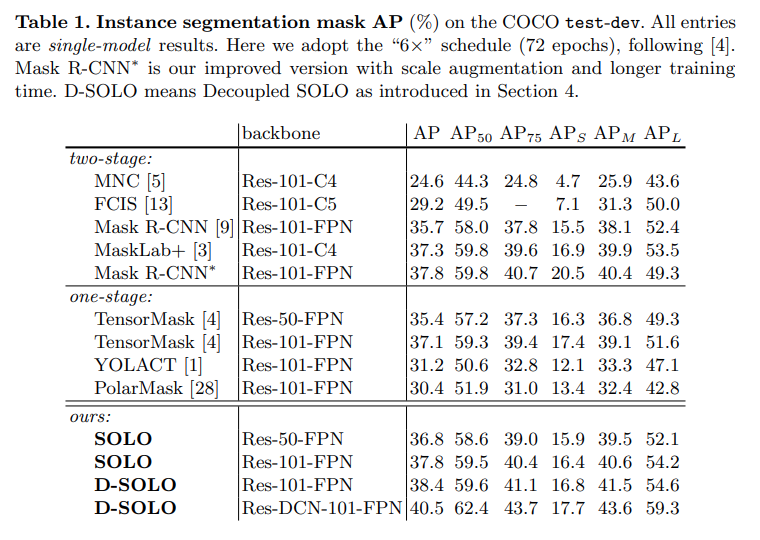
COCO test-dev mask AP(%)에 대한 성능을 비교한 결과 ResNet-101 backbone을 적용한 SOLO model의 mask AP는 36.8%로 two-stage 기반 방법인 Mask-RCNN과 유사하며, one-stage 기반 방법보다 높은 성능을 나타냄.

각 grid에 해당하는 soft mask prediction를 보면 각 instance의 mask를 나타냄을 확인할 수 있음. SOLO framework이 instance segmentation 문제를 position aware classification task로 처리한다는 것을 알 수 있음

3. Ablation Experiments#
Grid 수에 따른 성능을 비교한 결과 single output feature map에 대해 mask AP가 큰 차이가 나지 않음을 알 수 있음. → SOLO framework이 grid 크기에 큰 영향을 미치지 않음을 알 수 있음.
FPN을 적용한 multi-scale output을 적용할 때 큰 폭으로 성능 향상이 있음을 확인할 수 있음.
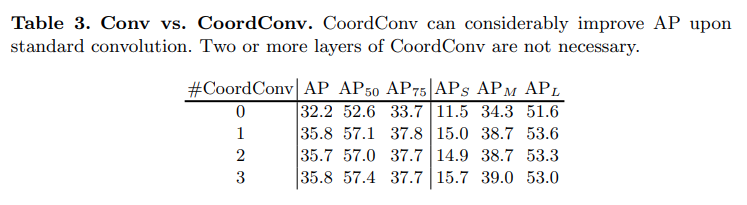
CNN대비 CoordConv 적용시 mask AP 3.6 향상이 있었음. 이는 CNN이 Padding layer 등에 의해 spatial variant 특성을 많이 잃어버리게 되는데, 이를 보완하기 위한 CoordConv를 적용함으로써 segmentation task에서 성능 개선을 확인함
여러번의 CoordConv.를 적용했을 때 유의미한 성능 개선이 나타나지 않음
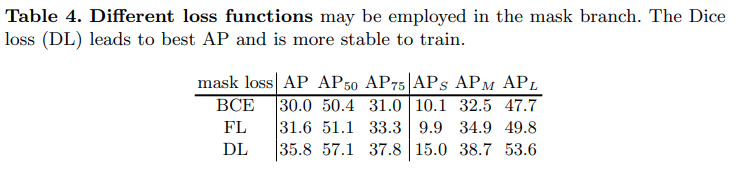
Focal loss의 경우 class inbalance에 잘 대응되되록 설계되어 insrance segmentation task왜서 BCE대비 좋은 성능을 나타냄을 확인할 수 있다 (BGE, mask loss weight 10, pixel weight 2 for positive sample, FL: mask loss weight 20)
Dice Loss가 loss hyper-parameter를 직접 조절하지 않고도 가장 높은 성능을 보였다. Dice Loss는 foreground/background pixel간의 올바른 균형을 잡을 수 있다. BCE와 FL도 hyper-parameter를 잘 조절하고 learning시 트릭을 사용하면 성능이 개선될 수 있지만. Dice loss가 학습이 더 안정적이고, 경험적인 방법을 사용하지 않고도 좋은 결과를 얻을 가성이 높다
