FCN - CVPR 2015
Contents
FCN - CVPR 2015#
Information
Title: Fully Convolutional Networks for Semantic Segmentation, CVPR 2015
Reference
Code:
Review By: Yejin Kim (가짜연구소 논문미식회 2기)
Edited by: Taeyup Song
Last updated on Jan. 5, 2022
Problem Statement#
VGG, ResNet과 같은 classification task를 위한 network는 입력영상에 대해 convolution layer와 pooling layer를 단계적으로 거치며, feature를 추출한 후 fully connected layer(FCL)를 이용 one-hot encoding을 통해 최종 classification 결과를 도출하는 과정을 거친다.
이 과정에서 위치 정보가 소실되기 때문에 semantic segmentation에 적용 시 pixel level classification을 수행할 수 없으며, 입력 영상의 크기에 제약을 받는다.
Proposed Method#
1. Architecture#
Classification을 위한 Convolutional Neural Network(CNN)에서 마지막 FCL을 1x1 Convolutional layers로 변경하여 위치에 따른 class activation을 도출한다.
모든 layer가 convolution layer로 구성되게 되며, input image 크기에 제약이 없어진다.
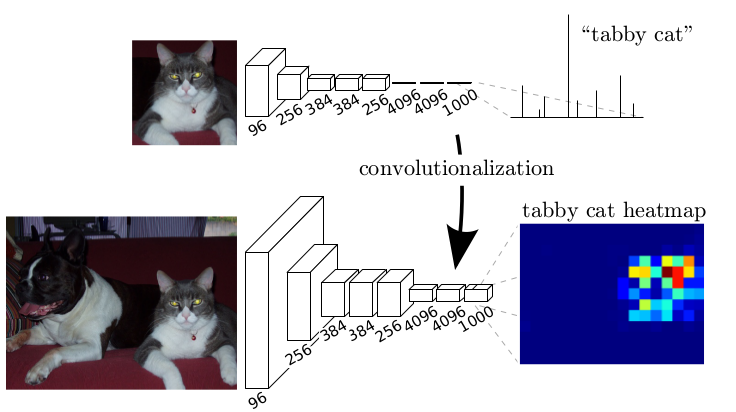
Fig. 4 Classification Network의 output을 heatmap으로 변환할 수 있도록 FCL을 convolution layers로 변경
(source: arXiv:1411.4038)#
하지만 여전히 output heatmap의 크기(resolution)가 input 크기와 일치하지 않으므로, Upsampling을 통해 output prediction의 크기를 확대하여 input과 동일하게 만들어준다.
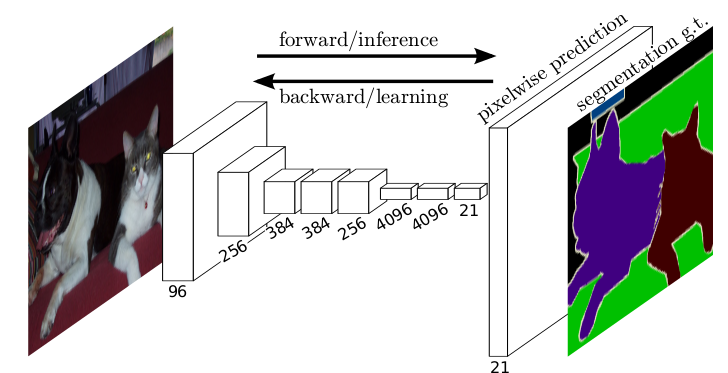
Fig. 5 Fully Convolutional Networks (source: arXiv:1411.4038)#
2. Improvement of segmentation#
Input image과 비교하여 feature map의 resolution이 작고, 이를 upsample 한 pixelwise prediction 결과 역시 coarse한 정보들을 담고 있다.
하지만 spatial location information을 늘리기 위해 layer 개수를 줄이게 되면 고수준의 features를 얻을 수 없는 한계가 존재한다.
Receptive field는 유지하면서(layer 수 유지) 더 정밀하고 상세한 segmentation을결과를 얻기 위해 마지막 layer의 feature 뿐 아니라 middle layers의 feature를 fusion을 함으로써 Deep feature와 accurate segmentation가 가능해진다.
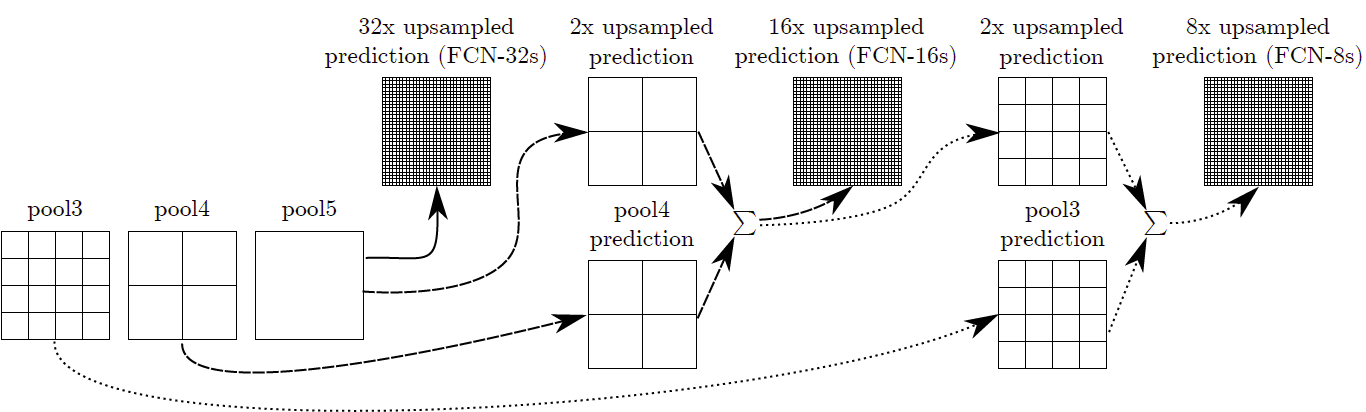
Fig. 6 High/low layer의 정보를 함께 사용하여 segmentation 결과 개선 (source: arXiv:1411.4038)#
Experimental Result#
다양한 형태로 High/low layer의 정보를 융하여 network를 구성한다.
FCN-32s: final layout의 output prediction을 stride32로 upsampling
FCN-16s: fianl layout의 output prediction을 stride2로 upsampling + pool4 layer의 output prediction → 결과물을 stride16로 upsampling
FCN-8s: finaly layer와 pool4의 output prediction의 합 + pool3의 output prediction → 결과물을 stride8로 upsampling

PASCAL VOC2011 validation set을 이용하여 비교한 결과 Lower layer의 output prediction을 이용하여 final prediction을 계산하므로써 점점 더 정밀한 segmentation이 가능함을 확인할 수 있다.