EncNet - CVPR 2018
Contents
EncNet - CVPR 2018#
Information
Title: Context Encoding for Semantic Segmentation, CVPR 2018
Reference
Review By: Junmyeong Lee (가짜연구소 논문미식회 2기)
Edited by: Taeyup Song
Last updated on Jan. 30, 2022
Summary#
channel attention을 통해 scene에 존재하는 label외의 label에 대한 prediction을 suppress해줌.
입력에 대해 CNN을 통해 feature map을 추출하고, 각 channel별로 서로 다른 attention을 주는 방법을 학습함. → input image의 global context를 고려하여 attention이 주어지도록 학습함. → 부수적으로 input image의 classification도 수행
Soft attention: attention를 통한 feature channel의 select가 아닌 weight의 역할을 함.
1. Motivation#
Vanila CNN → Dilated CNN 활용으로 패러다임 전환이 되면서 문제가 생김.
Vanila CNN : Stacked CNN네트워크 구조에서, downsampling을 해가며 global context를 포착할 수 있었음. But 해상도가 낮아져 detail 손실이 일어남.
Dilated CNN : Spatial resolution loss 문제는 해결했지만, 픽셀을 고립(isolates the pixels)시키는 문제가 있기 때문에, global context를 잘 포착하지 못함.
Receptive field가 커지는 것과 global context를 잘 포착하는 것이 꼭 비례할까?
Dilated CNN으로 receptive field를 늘리는 방향으로만 발전하는 것에 대해 질문함.
만약 Global Context를 잘 포착한다면, scene의 search space가 크게 줄어들 수 있다!
침실 → 침대, 의자 등과 연관되어 있다.
위와 같은 Strong correlation을 잘 활용하자.
전통적인 방법에서 사용된 statistical method에서 힌트를 얻음.
BoF(Bag-of-Features), VLAD … : Global feature statistics를 잘 포착한다.
2. Contribution#
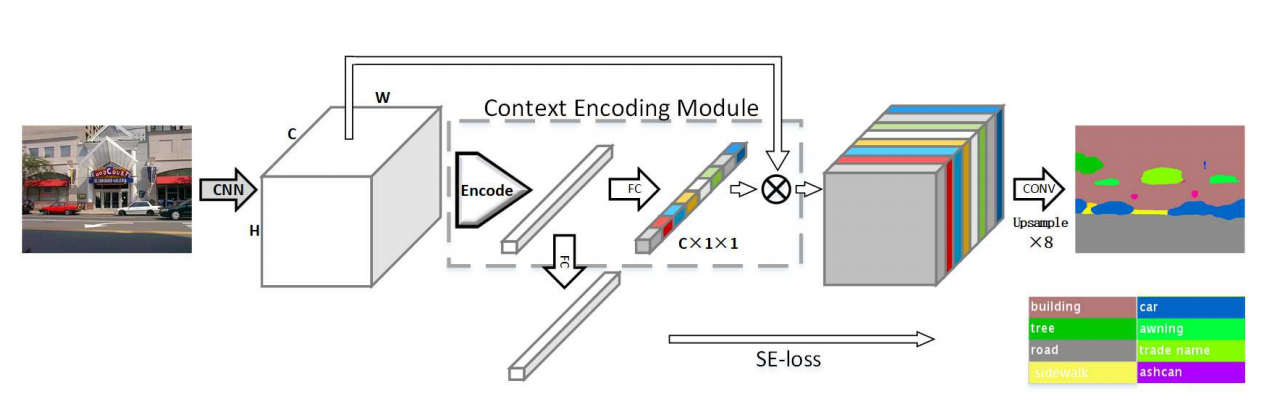
Fig. 18 Overview of the EncNet (source: arXiv:1803.08904)#
Context Encoding Module & SE-loss#
(i) Context Encoding Module
Global Context를 포착
각 채널에 대해 가중치 부여, 강조할 채널을 강조한다. (Attention Scheme)
식 설명
\(C\times H \times W\) 크기의 입력을 C 채널의 입력 N개로 나눌 수 있음.( \(N = H\times W\))
\[X=\{x_1,...,x_N\}\]K개의 codewords(visual center)들과 smoothing factor 정의
\[\begin{split}D=\{d_1,...,d_K\} \\ S=\{s_1,...,s_K\}\end{split}\]Encoding module의 출력
\[e_k=\sum_{i=1}^{N}e_{ik}\]\(r_{ik}\)와 \(e_{ik}\)의 식
\[e_{ik}=\frac{\exp \left( -s_k ||r_{ik}||^2\right)}{\sum_{j=1}^{K}\exp \left( -s_j||r_{ij}||^2\right)}r_{ik}\]\[r_{ik}=x_i-d_k\]\(e_{ik}\)는 입력의 잔차(residual) 에 가중치를 곱한 벡터이다.
\(e_k\)는 weighted sum한 C차원 결과 벡터가 되는데, 이는 각 channel 별 중요도를 잘 mapping할 수 있도록 만든다.
\(s_i\)는 smoothing해주는 역할을 하는데, \(||r_{ik}||^2\)항의 크기에 따른 영향을 반감시켜 조금 더 안정적인 학습이 가능하게 한다.(실험 결과, 보통 학습 시 0.5 근처로 수렴한다고 한다.)
벡터 크기의 분산을 줄이기 때문에 안정적인 학습(수렴)이 가능해질 것이다.
어텐션 적용
나온 output 벡터를 FC레이어에 통과시켜 Encoding 전의 feature map에 channelwise product한다.
output벡터는 각 채널에 대한 가중치이다.
직관적 해석
직관적으로 생각하면, cluster의 center를 찾는 알고리즘이라고도 볼 수 있을 것 같다.
따라서, 우리는 \(e_k\)라는 벡터로 각 채널과 \(d_k\)(visual center)사이의 거리를 aggregation한 것이라고 볼 수 있다.
각 위치가 있을 때, 각 위치에서 \(d_k\)라는 center의 비중을 곱해 더한 것이다.
한마디로, 각 channel이 어떤 global context에 가까운지 통계적으로 구할 수 있다.
⇒ 따라서 \(d_k\)는 \(x_i\)가 임베딩된 context 공간상에서, context를 나타내는 클러스터의 중심이라고 할 수 있다.
어텐션 또한, context 공간에서 찾은 최적 벡터를 fc레이어를 통해 가중치 벡터로 바꿔준 것으로 생각할 수 있다.
(ii) SE Loss(Semantic Encoding Loss)
Per-pixel cross entorpy는 isolated되어 있기 때문에(분리되어 있기 때문에), 작은 물체를 segmentation하는 데는 효과적으로 동작하지 못할 수 있다.
SE Loss는 Context Encoding Module에서 구한 output vector를 바탕으로, 어떤 물체들이 있는지 binary classification으로 학습한다.
물체가 있는지/없는지에 대해서만 예측한다.
작은 물체에 대해서 성능 개선 효과를 보인다.
Context Encoding Network(EncNet)#
앞서 제시한 module들을 기반으로 제시한 Segmentation architecture
Backbone : Dilated FCN(ResNet 기반)
3번, 4번 블록에 Context Encoding module + SE Loss적용
이런 auxiliary loss는 PSPNet보다 저렴하다.
기존 pixelwise crossentropy loss와 가중합을 통해 total loss를 구한다
3. 실험 결과#
Segmentation#
PASCAL context, PASCAL VOC 2012, ADE20K 사용
K = 32
Final loss : 두 loss의 가중합으로 정의
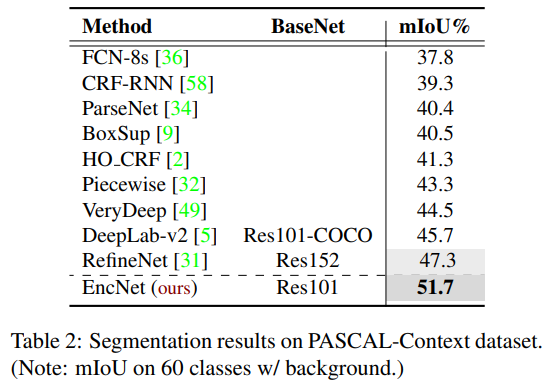
Ablation study#

SE-loss를 통해 성능 향상을 이룰 수 있다는 것을 검증하였다.
또한, K를 증가시킬수록 mIOU가 높아지기 때문에, 성능 향상이 이루어진다는 것을 알 수 있다.
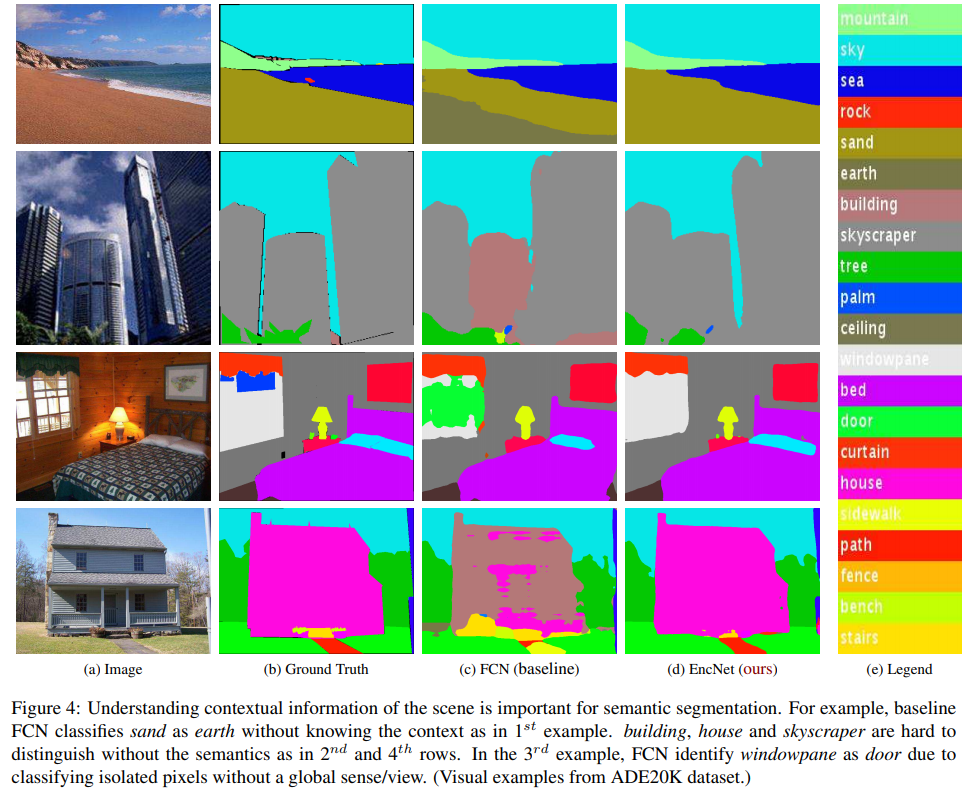
Other datasets#
PASCAL VOC 2012
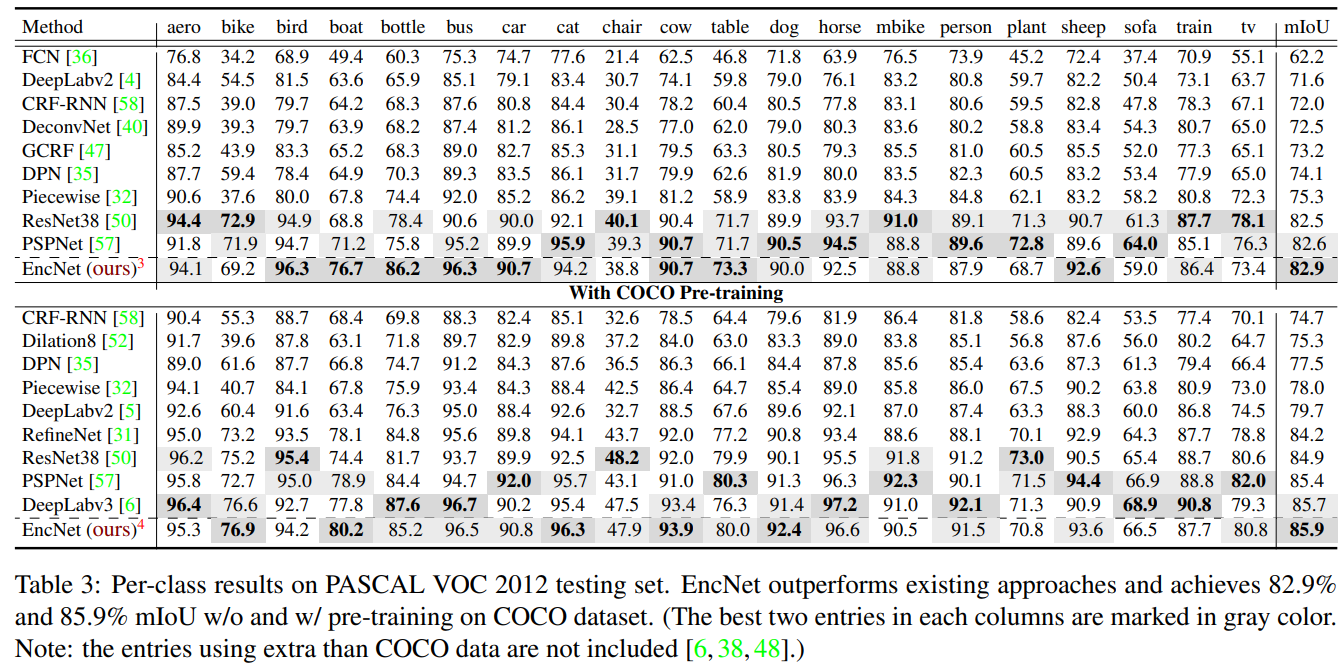
- 대부분 좋은 성능을 보였고, 다른 무거운 모델들(PSPNet, DeepLabv3)들과도 비교할만한 좋은 성능을 얻었다.
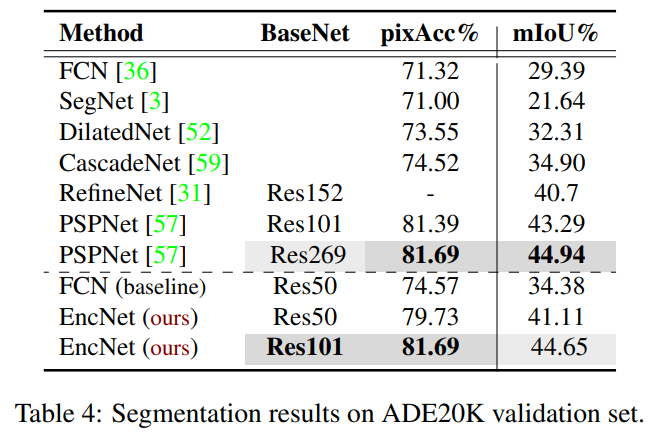
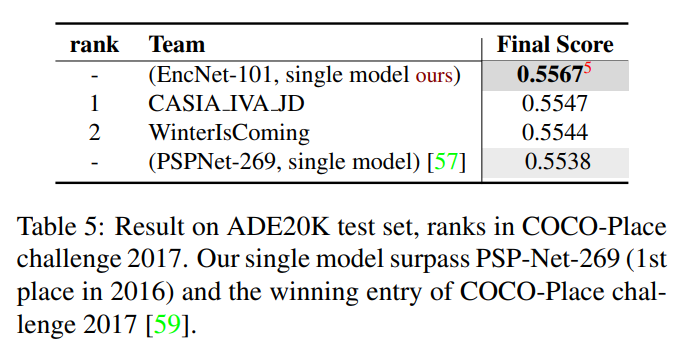
ADE20K
PSP(Res-269)에 비해 shallow한 네트워크 구조(Res-101)로 비슷한 성능을 얻어냈다.
Classification#
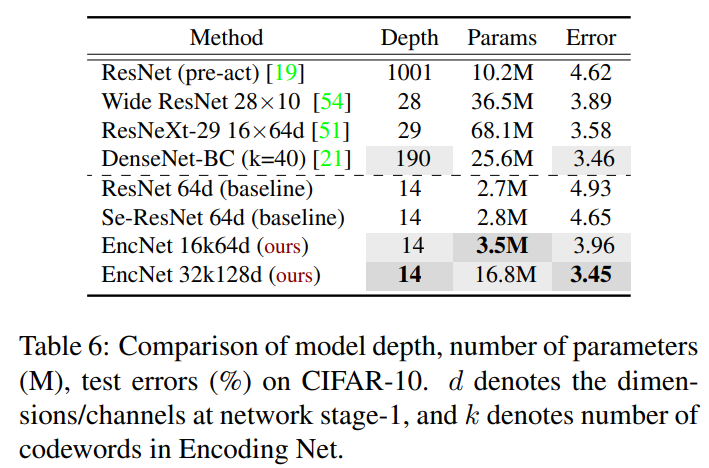
Context Encoding Module을 classification에 적용해 보았다.
SE-Net의 SE 모듈을 Context Encoding Module로 교체하여 적용했다.
s는 0.5로 고정했다.
학습 시, 0.5에 가깝게 \(s_k\) 가 수렴했기 때문이다
기존 네트워크와 비교하여 큰 성능향상을 달성하였다.
4. 정리#
Global Context를 잘 포착하기 위해 저자들은 여러 방법들을 생각해냈다.
Context Encoding module
SE-loss
⇒ EncNet을 만들었다.
실험 결과, 가볍고 효과적인 Segmentation architecture임을 검증하였다.
앞서 제시한 두 가지 모듈 또한 성능 향상에 확실히 기여함을 밝힐 수 있었다.
Classification에도 적용해본 결과, Context Encoding module이 효과적으로 scene의 context를 잘 포착하여 classification 정확도 또한 올라가는 것을 관찰했다.