DeconvNet - ICCV 2015
Contents
DeconvNet - ICCV 2015#
Information
Title: Learning Deconvolution Network for Semantic Segmentation, ICCV 2015
Reference
Review By: Yejin Kim, Seongsu Park (가짜연구소 논문미식회 2기)
Edited by: Taeyup Song
Last updated on Jan. 30, 2022
Motivation#
Segmentation 모델인 FCN의 문제점을 지적하면서 논문의 introduction을 구성함
네트워크가 고정된 사이즈의 receptive field(한 결과 픽셀이 참고하는 픽셀 수)가 고정되어 있기 때문에, 이보다 작거나 큰 물체는 fragment되거나 mislabel될 수 있음
큰 물체들은 나뉘어지거나, 작은 물체들은 무시됨
Skip architecture 구조에도 근본적 해결 방식이 될 수 없음

Fig. 22 Limitations of semantic segmentation algorithm based on FCN (source: arXiv:1505.04366)#
Detail structure가 smooth됨.
FCN의 경우 16x16의 결과가 bilinear interpolation되어, deconvolution 레이어 없이는 물체의 경계를 제대로 표현하지 못함
Method#
이 논문에서는 deconvolutional network를 활용해 전체적인 네트워크를 제안함
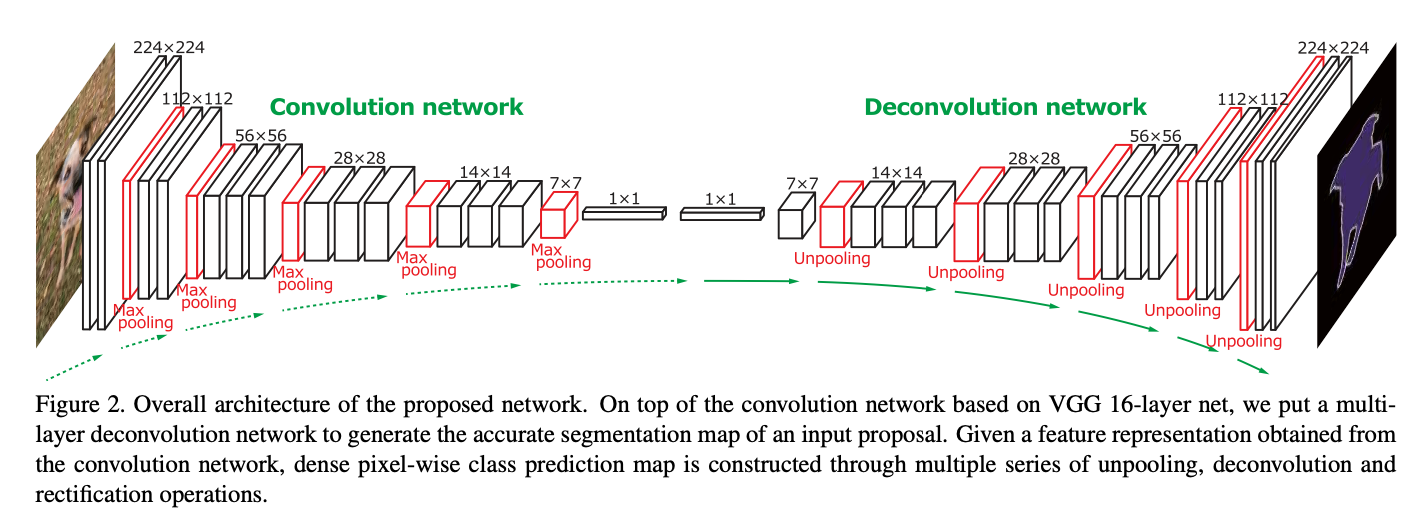
Fig. 23 Overall architecture of the DeconvNet (source: arXiv:1505.04366)#
Deconvolutional network에서는 크게 Unpooling, Deconvolution을 주로 소개함
Unpooling: 하나의 픽셀을 각 축으로 factor만큼 늘림
Pooling의 경우 가장 높은 값을 가진 index를 switch함
Unpooling은 그 때 선택한 index에 그 값을 넣고 나머지는 0으로 둠
결과가 sparse함 (한 번 수행할 때마다 [1/factor**2]의 값들이 채워져 있음)
즉, unpooling을 사용하기 위해서는 convolution/deconvolution 대칭 구조여야 함
Deconvolution: 하나의 입력 픽셀이 근처 결과 패치까지 영향을 미치는 연산자
Convolution의 경우, 하나의 입력 픽셀이 다른 결과 픽셀에 영향을 미치지 않음
Deconvolution의 경우 operator 크기가 3일 때, 총 9개의 deconvolution 결과를 모두 합한 값이 결과값
수학적으로 정확한 정의로는 deconvolution이 아니라, transposed convolution이라는 말이 더 정확함
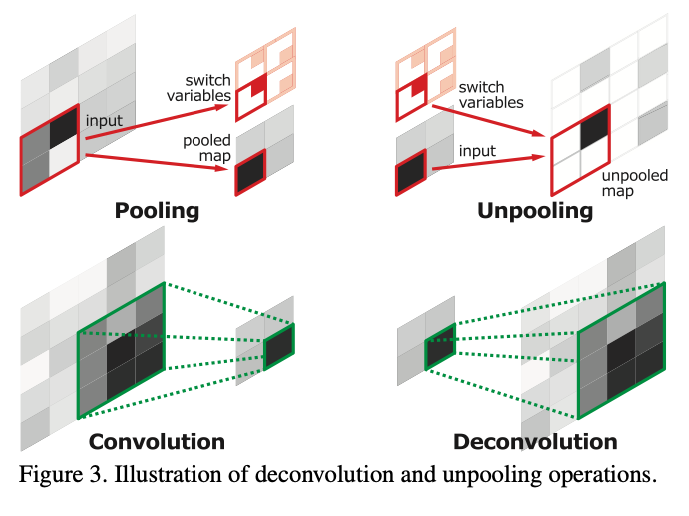
Fig. 24 Overall architecture of the DeconvNet (source: arXiv:1505.04366)#
이를 종합했을 때, Unpooling 연산자에서 0으로 채워진 부분은, deconvolution operator를 통해 정상적으로 복구함을 알 수 있음
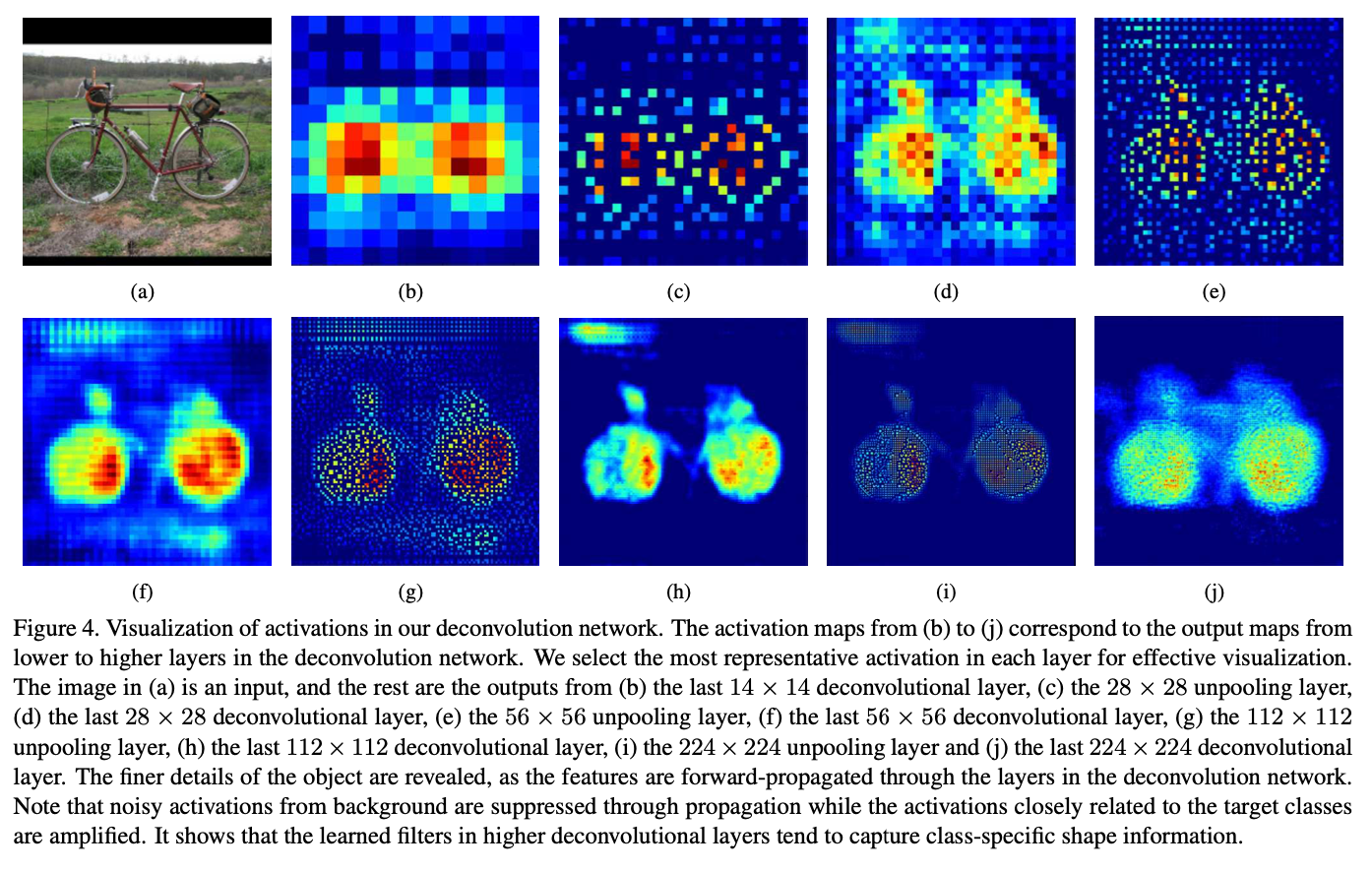
Fig. 25 Visualization of activations in DeconvNet (source: arXiv:1505.04366)#
Unpooling을 통해 resolution이 높아짐. Deconvolution을 통해 중요한 activations는 증폭되고 noisy activations는 억제되면서 배경과 object가 더 뚜렷하게 구분됨.
Instancewise segmentation: input image 전체가 아닌 일부분을 input으로 사용
input: sub-image (instance) of the input image
output: pixelwise class prediction
장점:
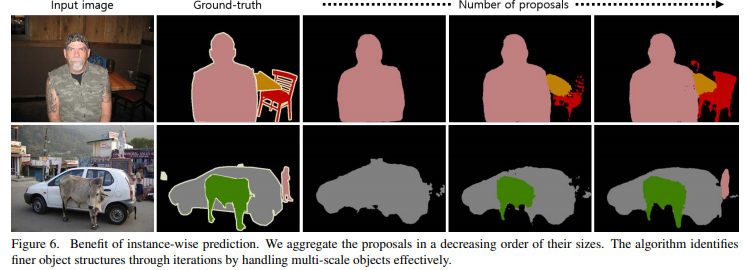
여러 scale을 segmentation함 → 크거나 작은 object를 identify 할수 있음
instance의 크기 > input image의 크기: training complexity↓ & memory requirement↓
Training#
Batch Normalization: reducing internal-covariate-shift
Two-stage training:
first stage: training with the centered easy examples
second stage: training with the partially overlapped examples
장점: misaligned proposals에 더 robust하게 학습됨.
Inference#
input image를 잘라내 candidate proposals를 생성 → 각 proposal을 학습된 네트워크에 적용해 semantic segmentation map을 계산 → 모든 proposals의 output을 aggregate
Aggregation: 각 proposal의 semantic segmentation map을 합쳐서 하나의 output map을 생성
각 semantic segmentation map을 input image 크기만큼 늘리고 빈값은 0으로 채움.
확대된 모든 semantic segmentation maps을 대상으로
pixelwise maximum 또는
average of the score maps corresponding all classes를 계산
이후 softmax function과 fully-connected CRF를 거쳐 최종 pixelwise class prediction 생성
Ensemble with FCN: Deconvolution network와 FCN의 장점을 합침
Deconvolution network의 장점: capturing fine-details에 탁월, 다양한 scale의 object를 다룰수있음
FCN의 장점: object의 전체적인 형체를 잘 추출함
두 알고리즘의 output을 각각 구함 → 두 output의 평균을 구함 → CRF를 적용해 final semantic segmentation 생성
Experiments and Conclusion#
candidate proposal 생성을 위해 edge-box 이용
결과
CRF를 적용하면 accuracy가 근소하게 향상됨.
Deconvolution Network (DeconvNet)보다 ensemble Deconvolution Network (EDeconvNet)가 전반적으로 더 좋은 결과를 냄.
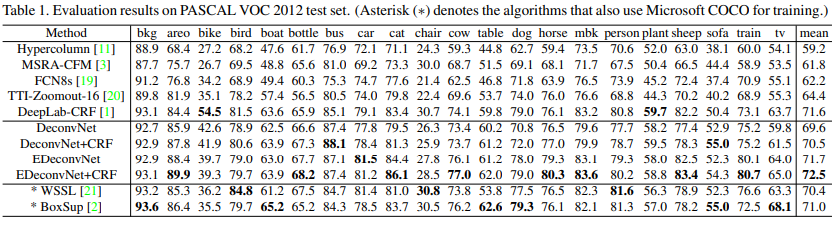
Aggregation을 위한 proposal의 개수가 늘어나면 알고리즘이 더 세밀하게 segmentation함
Deconvolution network, FCN, CRF, instancewise prediction의 장점을 이용해 더 정밀하고 자세한obejct segmentation mask를 생성.
