SETR - CVPR 2021
Contents
SETR - CVPR 2021#
Information
Title: [SEmantic TRansformer] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers, CVPR 2021
Reference
Review By: Jongsu Choi
Last updated on Jun. 4, 2022
Introduction#
CNN 기반 Semantic Segmentation
기존 방식은 대부분 FCN(Fully Convolution Network)의 Encoder-Decoder로 구성되어 있다.
Encoder : Feature Representation Learning을 역할 하며, 주로 Stacked Conv. Layers로 구성되어 있다.
Decoder : Pixel Level Classification 역할을 수행한다.
Encoder에서 stacked convolution layers를 지남에 따라 얻어지는 feature map은 resolution은 감소하고 depth가 깊어짐에 따라, 점점 Spatial Information은 줄어들고, abstract한 정보를 학습하게 된다.
또한, 구조적인 관점에서 receptive field는 network의 depth에 선형적인 관계를 가진다. 따라서 넓은 receptive field를 갖도록 network를 구성하기 위해서 depth를 늘려야 하는데, 일정 depth 이상으로 layer를 추가 하는 것은 의미가 없다. 즉 receptive field가 구조적으로 제한이 있어 FCN은 long range context를 학습하기 어려운 문제가 있다.
이런 한계를 극복하고자 Atrous/Dilate Convolution 등 방법으로 receptive field를 늘리는 방법들을 사용하였지만, encoder-decoder 구조를 탈피하지 못하고, down-sampling 방식으로 인한 단점은 여전하다.
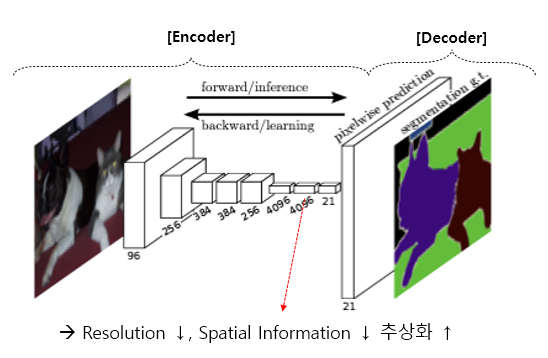
Fig. 31 FCN architecture (source: arXiv:1411.4038)#
SETR(“SE”mantic + “TR”ansformer)
Encoder에 pure Transformer만을 사용한 모델을 제안.
CNN 기반 모델과 다르게 pooling, stride와 같은 이미지/feature down-sampling 없이Transformer encoder를 이용하여 global context를 학습하는 새로운 접근 방법을 제안.
Transformer 모델은 이미 NLP분야에서 성능을 입증하였고, ViT(Vision Transformer)를 통해 Image Classification에서 좋은 성능을 보였다. 이는 이미지 특징 추출을 위해 stacked convolution 구조를 통한 공간 정보는 압축(손해)하며 global context를 학습한다는 종래 방식이 필수가 아님을 증명하였다. (Translation Equivariance + Locality를 Inductive Bais로 하는 Conv. 방식이 Image 분야의 가장 효율적이라는 기존 방법에서 탈피)
Contributions#
Transformer Encoder를 적용한 새로운 semantic segmentation 구조를 제안 (Encoder-Decoder -> Sequence to Sequence)
다양한 복잡도를 가진 Decoder를 적용하여 Self Attention의 특징 추출 효과에 대한 광범위한 해석 수행함.
SOTA 성능 달성 (ADE20K: 50.28% mIoU Pascal Context: 55.83% mIoU)
Proposed Method#
SETR(”SE”gmentation + “TR”ansformers)
모델은 크게 Sequentialization → Transformer → Decoder로 구성되어있으며, Decoder는 3가지 방식을 제안한다.
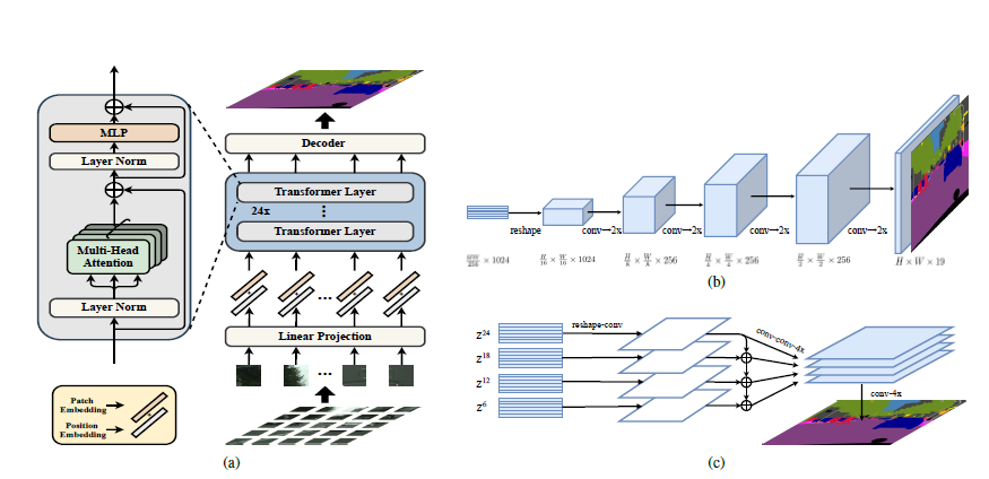
Fig. 32 Schematic illustration of SETR (source: arXiv:2012.15840)#
1. Sequentialization and Position Embedding#
Transformer 모델을 사용하기 위해 \(H \times W \times 3\) resolution의 이미지를 \(C\) hidden channel size를 가지는 \(L\)개의 sequential vector 형태로 re-representation 함.
본 논문에서는 ViT와 동일하게 입력 영상을 \(16 \times 16\) 개의 patch로 분할한다. 각각의 patch를 flatten 한 후 linear projection하여 \(C\)차원으로 축소하여 결과 적으로 1차원 patch embedding의 sequence로 변환한다. (L X C, L = H/16 X W/16)
순서 정보를 주기 위해 각 patch에 해당하는 position embedding을 추가한다.
2. Transformer Encoder#
기존 Transformer와 다른점은 다음과 같다. (1) MSA(Multi-Head Self Attention)전 layer norm을 적용한다.
(2) MLP(Multi-Layer Perceptron) layer를 추가.24개의 Transformer Block Layer로 모델을 구성
본 모델의 구조는 이미지 Patch형태로 Re-representation되어 Transformer Input으로 활용되어 모든 레이어는 “Global Receptive field”를 가진다.
각 Patch에 대한 attention score를 계산하기 위해 다른 모든 patch가 활용됨. —> 기존 FCN 형태의 Limited Receptive Field 한계를 개선

Fig. 33 Attention map of picked points (red) (source: arXiv:2012.15840)#
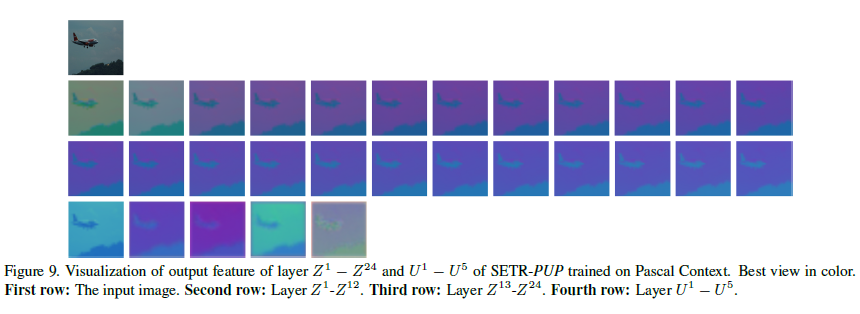
Fig. 34 Visualization of output features (source: arXiv:2012.15840)#
Auxiliary Loss : Transformer layer 중 해당 Index에 해당 되는 output을 \([H \times W \times \text{num. of class}]\)로 변환 후 auxiliary loss를 계산 (channel : 2D convolution. Resolution : Bilinear Interpolation)
3. Decoder#
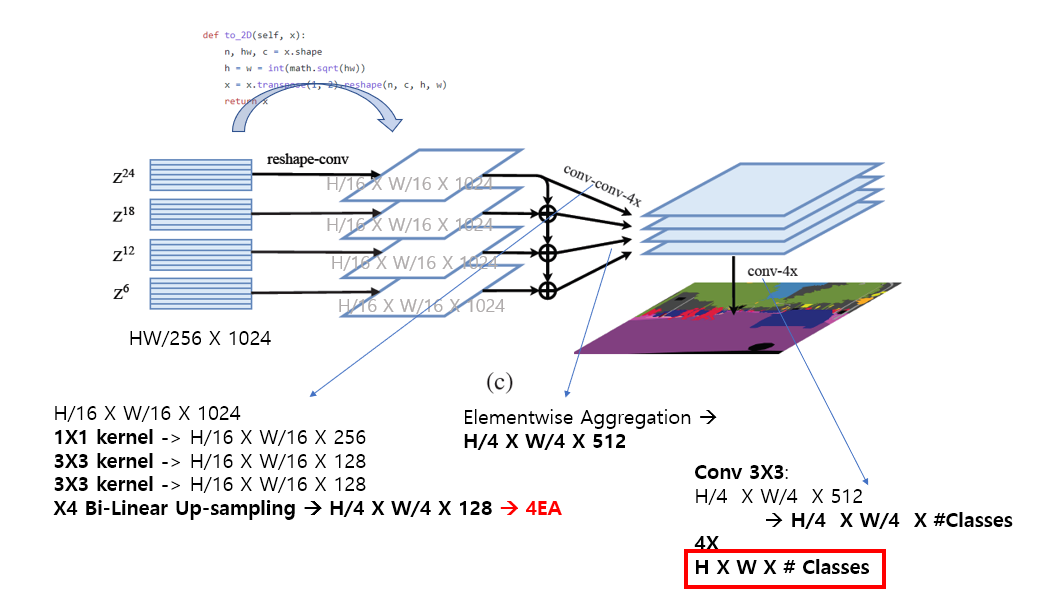
Fig. 35 SETR-MLA (source: arXiv:2012.15840)#
Pixel Level Segmentation을 위해 Transformer Encoder의 Output H/16 X W/16 X C Feature Map을 \([H \times W \times \text{num. of class}]\) 형태의 Segmentation Map 형태로 Re-representation 하는 역할
우선 transformer output \(Z\) (dim.: \(\frac{HW}{256} \times C\))를 \(\frac{H}{16} \times \frac{W}{16} \times C\)로 reshape 후 다음과 같은 3가지 decoder를 적용하여 최종 segment map을 도출한다.
(1) Naive Decoder
가장 기본적인 방법으로 우선 채널을 # of classes로 맞춰준 후 bi-linear interpolation을 통해 \([H \times W \times \text{num. of class}]\) segmentation map을 만들어 줌
(2) Progressive UP-sampling(PUP) :
One-step up-scaling은 많은 noise를 발생하므로 한번에 2배씩 총 4번 up-scale하는 방법을 적용한다.
(3) Multi_Level feature Aggregation(MLA)
FPN(Feature Pyramid Network)와 유사한 Multi-Level Feature를 사용하는데, 비슷한 개념을 차용하여, 24개의 Transformer Block Layer에서 추출하여 Multi-level Feature 개념으로 사용한다.
전체 e개의 Layers중 M개의 Layers를 e/M Step 등 간격으로 추출 하여 feature로 사용한다. e=24, M = 4인경우 6, 12, 18, 24번째 Layer를 MLA에 사용한다.
각 Level에서의 Feature는 2D shape(\(\frac{HW}{256} \times C\))을 \(\frac{H}{16} \times \frac{W}{16} \times C\) 형태의 3D feature map형태로 reshape되고 3개의 conv. laye를 거치며 channel을 축소한다. 이후 X4 resolution Up-Sampling(bi-Linear interpolation) 후 element wise aggregation한다. 이후 \(3 \times 3\) convolution을 통해 #Classes 만큼 Channel을 맞춰 준 후(128*4 → Num_Classes) X4 resolution upsampling을 통해 원본의 해상도 \(H \times W\)로 만들어 주어 최종 segmentation map을 만들어 낸다.
Experiment Result#
1. Implementation Details#
mmsegmentation 기반으로 구현
Augmentation:
Random cropping (768, 512 and 480 for Cityscapes, ADE20K and Pascal Context respectively)
Random horizontal flipping
Optimization
Init. learning rate: 0.001 (on ADE20K, Pascal Context), 0.01 (on Cityscapes)
SGD with polynomial learning rate decay schedule
Momentum = 0.9, weight decay =0
2. Setting#
Evaluation Dataset: Cityscapes, ADK20K, PASCAL Context
SETR variants
T-Large, T-Base : Transformer Block 수와 Head 수를 조절 하여 T-Large(24EA, 16head), T-Base(12EA, 12Head)로 디자인.
ViT, DeiT : ViT or DeiT에서 제공하는 weight를 transformer와 linear projection layer에 사용. (그 외 parameters는 random initialize.)
Single-scale(SS), multi-scale (MS, image scaling(x0.5, x0.75, x1.0. x1.25, x1.5, x1.75) 적용 후 sliging window를 적용하여 test set 추출 (e.g. Pascal Context의 경우 480x480 크기로 crop)
Hybrid setting의 경우 ResNet-50 기반 FCN의 output을 SETR에 입력하는 형태로 구성함.
3. Result#
Cityscape dataset을 이용하여 학습한 다양한 SETR model의 성능을 비교
Decoder의 경우 점진적으로 upsampling을 수행하는 SETR-PUP가 가장 좋은 성능을 나타냄. → SETR-MLA와 같이 서로 다른 transformer layers에서의 output이 FPN과 같이 장점을 가지지 않음.
T-Large setting에서 SETR-PUP-Base는 hybrid setting 대비 80K로 학습할 때 높은 성능을 나타냄. 이는 FCN encoder를 Transformer가 대체할 수 있음을 나타냄.
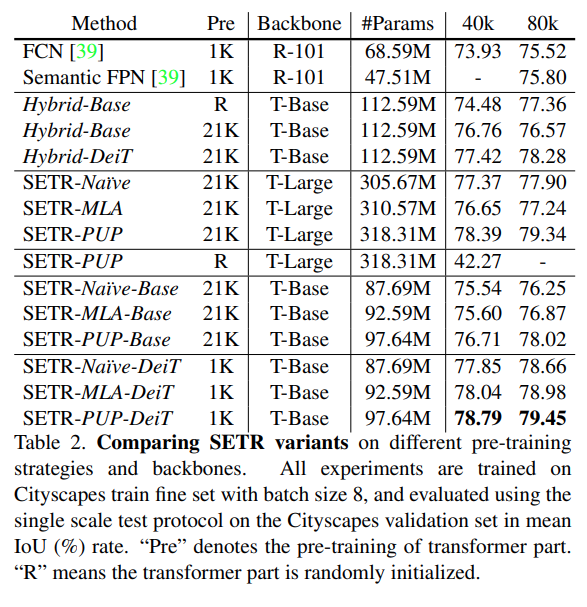
ADE20K val. set에서는 SETR-MLE가 약간의 성능 우위를 보임.
DeiT pre-train 모델을 사용한 경우 더 좋은 성능을 나타냄 → pre-train 선택이 중요함.
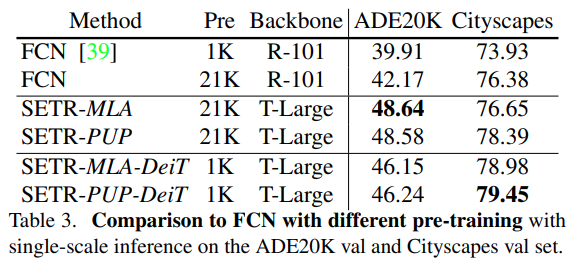
SOTA 방법과 비교
ADE20K dataset에서 기존 제안된 segmentation 대비 SETR-MLA 방법이 가장 높은 mIoU를 가짐을 확인 가능하며, multi-scale inference에서 SOTA를 달성했음을 알 수 있음.
Pascal Context dataset에서 FCN 모델 대비 월등히 높은 성능을 보임.
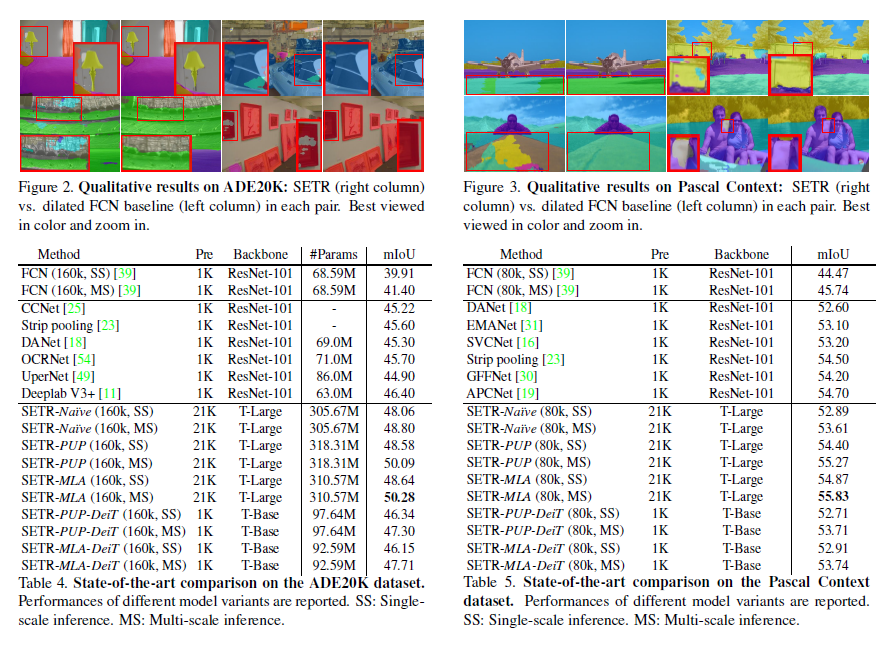
Cityscapes dataset에서 SETR이 FCN 방법대비 높은 성능을 나타내고, SOTA로 알려진 Non-local 및 CCNet과 같은 방법보다 높음 성능을 나타냄.
