InstanceFCN - ECCV 2016
Contents
InstanceFCN - ECCV 2016#
Information
Title: Instance-sensitive Fully Convolutional Networks, ECCV 2016
Reference
Review By: Taeyup Song, Jeonghyon Kim
Last updated on Nov. 1, 2022
Problem Statement#
Fully convolutional network(FCN)은 semantic segmentation task에서 효과가 있다는 것이 확인되었지만, 개별 object instance를 구분하는 것은 불가능하다.
개별 instance에 대한 mask map을 구하기 위해 object detection에서 적용되는 RPN(region proposal network)를 적용할 수 있다. 다만 RPN의 경우 mask level proposal을 추출할 수 없다.
제안된 InstanceFCN은 각 pixel에 대한 classifier로써 동작하지만, 하나의 score map을 가지는 FCN과 다르게 각 instance에 대응되는 score map의 set을 계산하여 instance level의 segmentation을 수행한다. (Instance proposal은 sliding window 방식을 사용함.)
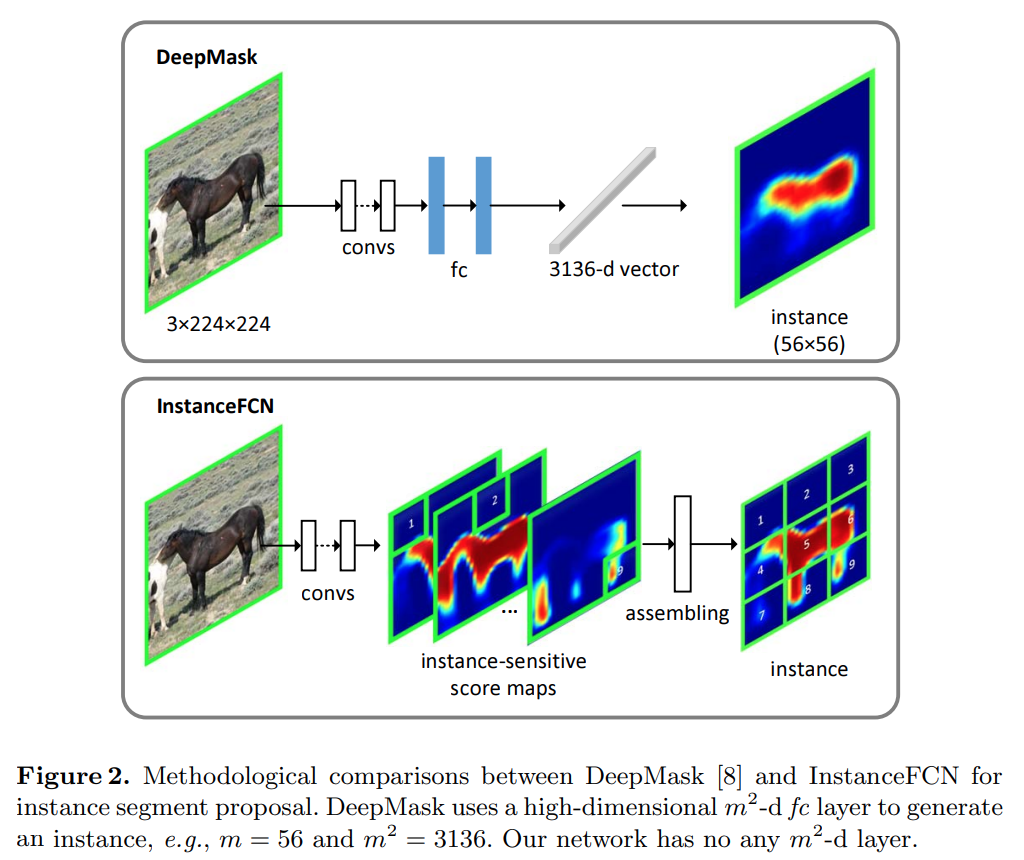
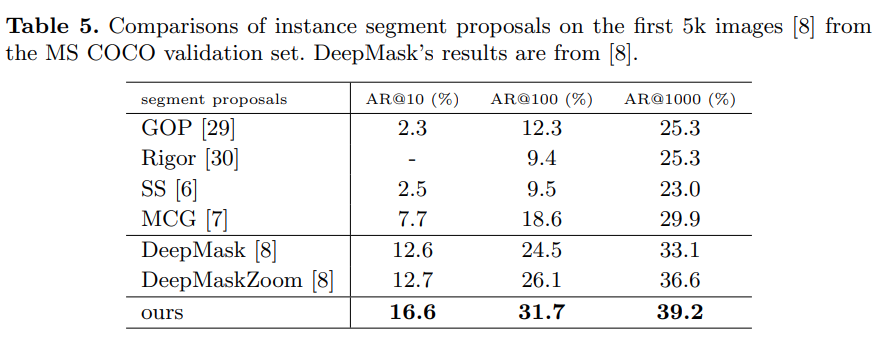
Fig. 41 Methodological comparison between DeepMask and InstanceFCN (source: arXiv:1603.08678)#
Proposed Method#
기존의 FCN과 같은 Semantic segmentation에서는 각 픽셀에 대해 cross-entropy loss를 학습에 사용하기 때문에 각 픽셀에 대해 하나의 semantic 정보만 존재하며, 두 instance가 겹치는 영역에 대한 instance segmentation 달성할 수 없다.
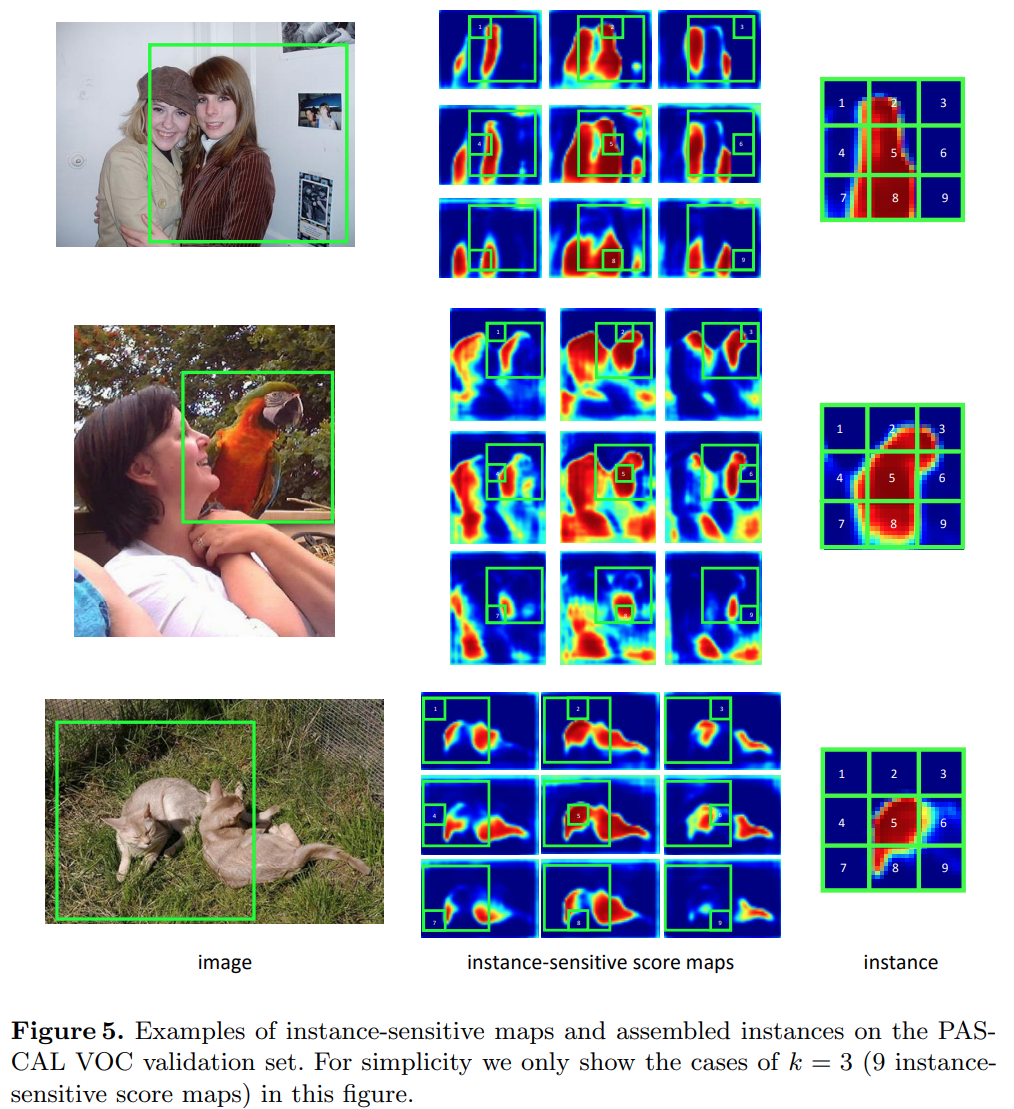
추출한 ROI에 대해 \(K \times K\) instance sensitive score map을 구하고 (첫번째 instance sensitive score map은 ROI의 왼쪽 상단 영역의 score를 나타내고 두 번째는 중간 상단을 나타내는 방식) assemble하여 최종 score map을 구한다.
\(K \times K\) 개의 feature map을 생성
각 ROI를 \(K \times K\) 영역으로 분할 후 각 영역의 segment map을 조합하여 최종 segment map 생성함.
e.g. ) ROI의 (x,y) = (0,0) 영역은 첫번째 feature map에서 가저오고, (x,y) = (1,0) 영역은 두번째 feature map에서 가져옴. …
이 경우 각 score map은 인스턴스의 상대적인 위치에 대한 score만을 나타내므로 이를 통해 instance를 구분할 수 있다.
(1) Network Architecture#
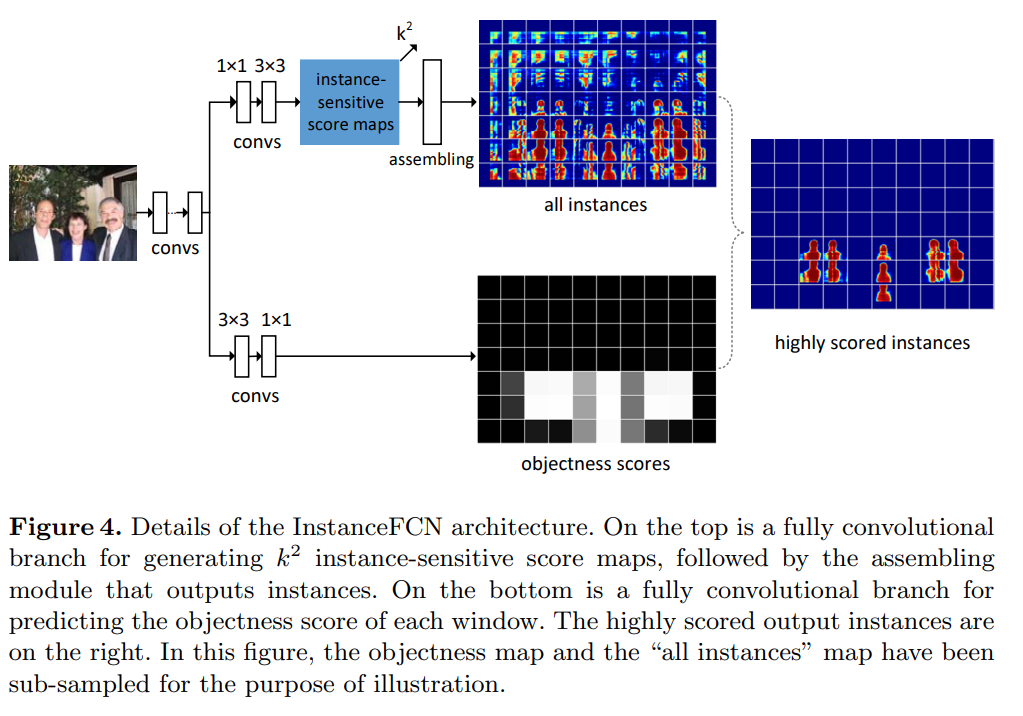
Fig. 42 Details of the InstanceFCN architecture. (source: arXiv:1603.08678)#
Backbone
ImageNet으로 pre-trained된 VGG-16을 backbone을 적용함.
13개의 convolutional layer만으로 구성하여 임의의 입력에 대응 가능하도록 함
[24] Hole algorithm, max pooling → ???
Feature map에서 segment map과 instances의 score를 구하기 위한 branch로 분기함.
Instance-sensitive score maps and Instance assembling module
영상의 임의의 pixel은 ROI에 따라 상대적인 위치가 다르다. (Sliding window를 이용하여 ROI 추출)
각 ROI에 대해 Instance의 상대적인 위치에 대한 score만을 표현하는 Instance-sensitive score map을 생성한다.
Relative position을 나타내기 위해 \(k \times k\) regular grid를 사용하는 경우, backbone에서 구한 feature에 대해 1x1 conv.(output ch. 512)와 3x3 conv.를 거쳐 \(K^2\) channel의 output을 구함
이후 assembling module에서 \(m \times m\) 크기의 sliding window를 통해 얻은 각 ROI에 대해 score를 조합하여 object instance 를 생성함. (\(m=21\) pixel을 적용, feature map의 stride 8)
Objectness score
backbone에서 구한 feature에 대해 3x3 conv.(output ch. 512)와 1x1 conv. 적용함.
1x1 conv는 per-pixel logistic regression의 역할을 함.
각 sliding window에 대한 instance/non-instance를 판단함
(2) Local Coherence#
Fig. 43 Local coherence (source: arXiv:1603.08678)#
Natural image의 pixel에 대해 인접한 ROI가 같은 prediction 값을 가질 가능성이 높으므로, sliding window를 이용하여 ROI를 추출하는 과정에서 모든 prediction을 다시 계산할 필요가 없음
따라서 영상의 local coherence를 이용하여 sliding window의 수를 줄여 연산속도를 개선한다.
(3) Algorithm and Implementation#
Training
256 sliding window를 random하게 생성한 후, 다음과 같은 loss function을 적용하여 network를 학슴함.
\[ \sum_i \left( \mathcal{L}(p_i,p_i^* )+\sum_j \mathcal{L}(S_{i,j},S_{i,j}^* )\right) \]여기서 \(i\) 는 sampled된 windows의 index이며, \(p_i\) 는 \(i\) 번재 window의 objectness score로 1인 경우 positive sample, 0인 경우 negative sample로 간주한다. \(S_{i,j}\) 는 \(i\) 번재 ROI의 \(j\) pixel의 segment map을 나타낸다. \(\mathcal{L}\) 은 logistic regression loss를 적용한다.
Inference
입력된 영상에 대해 instance-sensitive score maps과 objectness score map을 구한다.
Assembling module은 densely sliding windows를 적용하여 각 position에서의 segment instance를 구한다.
Multiple scale에 대응하기 위해 영상의 짧은 축에 대해 \(600 \times 1.5 ^{\{-4,-3,-2,-1,.0,1\}}\) 로 resize하여 instance를 추출한다.
output segment에 대해 NMS를 적용하여 최종 segment map을 구한다.
Experimental Result#
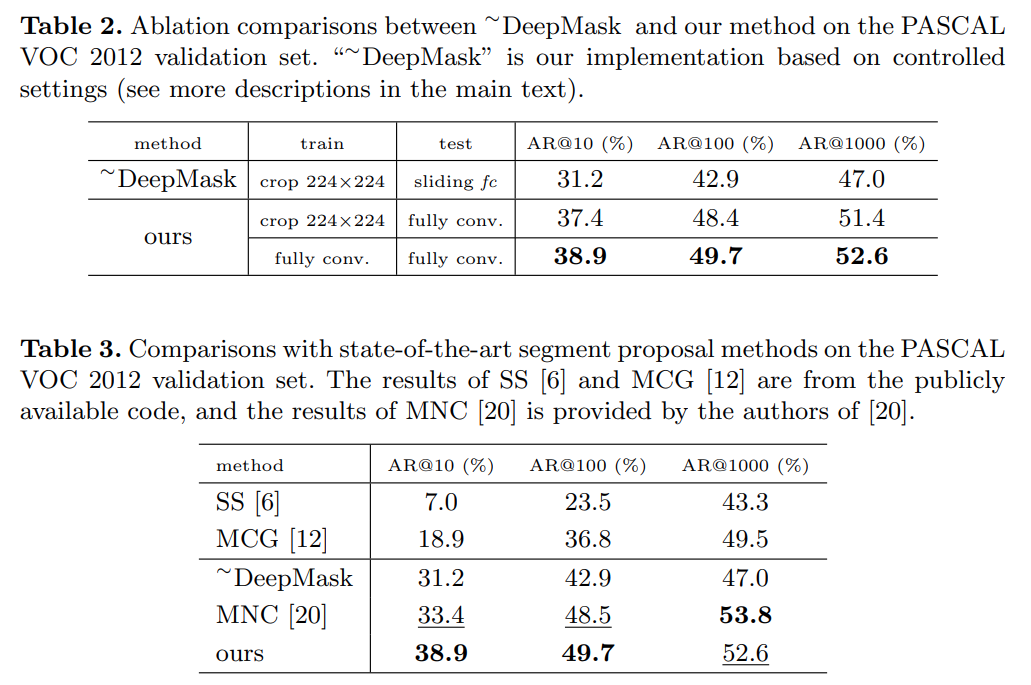
2. Result (PASCAL VOC 2012)#
2. Result (MS COCO)#