1. 객체 탐지 소개¶
![]()
객체 탐지(Object Detection)는 컴퓨터 비전 기술의 세부 분야중 하나로써 주어진 이미지내 사용자가 관심 있는 객체를 탐지하는 기술입니다.
인공지능 모델이 그림 1-1 좌측에 있는 강아지 사진을 강아지라고 판별한다면 해당 모델은 이미지 분류 모델 입니다. 하지만 우측 사진 처럼 물체가 있는 위치를 탐지함과 동시에 해당 물체가 강아지라고 분류 한다면 해당 모델은 객체 탐지 모델입니다.

그림 1-1 이미지 분류 모델과 객체 탐지 모델 비교 (출처: https://www.pexels.com/search/dog/)
객체 탐지 모델은 여러 분야에서 활용 가능합니다. 가장 대표적인 활용 사례는 자율 주행 자동차입니다. 자율 주행 자동차를 만들기 위해서는 컴퓨터가 스스로 주변 사물을 인식할 수 있어야 합니다. 정지 신호가 있을 때 속도를 줄이고 초록불이 켜지면 다시 주행을 시작하는 등 주변 환경과 상호작용이 필요한 자율 주행 자동차에 객체 탐지 기술이 사용 됩니다.
객체 탐지 기술은 보안 분야에서 효율적인 자원 관리에도 사용됩니다. 일반적으로 CCTV는 쉬지 않고 기록이 되기 때문에 방대한 양의 메모리가 필요합니다. 허나 객체 탐지 기술과 결합하여 특정 사물이 탐지 되었을 때만 기록을 시작하면 메모리를 효율적으로 사용할 수 있습니다.
이번 장에서는 마스크를 탐지하는 객체 탐지 모델을 구축해보겠습니다. 주어진 이미지를 입력을 받았을 때 얼굴 위치를 탐지하고, 얼굴에 마스크가 씌여져 있는지를 확인하는 모델을 구축해볼 것입니다.
1.1. 바운딩 박스¶
객체 탐지 모델을 만들기에 앞서, 우선시 되어야 할 과정은 바운딩 박스를 만드는 것 입니다. 객체 탐지 모델에 사용되는 데이터의 크기가 방대하기 때문에, 바운딩 박스를 통하여 객체를 올바르게 탐지하고 딥러닝 과정에서 바운딩 박스 영역만 대상이 되기 때문에, 딥러닝을 효율적으로 수행할 수 있습니다.
바운딩 박스는 특정 사물을 탐지하여 모델을 효율적으로 학습 할 수 있도록 도움을 주는 방법입니다. 객체 탐지 모델에서 바운딩 박스는 타겟 위치를 특정하기 위해 사용됩니다. 타겟 위치를 X와 Y축을 이용하여 사각형으로 표현합니다. 예를 들어, 바운딩 박스 값은 (X 최소값, Y 최소값, X 최대값, Y 최대값)으로 표현이 됩니다.

그림 1-2 바운딩 영역 픽셀값으로 지정 (출처: https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection)
그림 1-2와 같이 X와 Y의 최소값과 최대값 사이의 면적을 바운딩 박스 영역으로 잡습니다. 하지만, 위의 X, Y 값은 픽셀값으로 효율적인 연산을 위해서는 최대값 1로 변환을 해줘야 합니다.

그림 1-3 바운딩 영역 백분위로 지정 (출처: https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection/raw/master/img/bc2.PNG)
그림 1-3의 X, Y 값은 각각 X의 최대값 971, Y의 최대값 547을 나눈 값입니다. X의 최소값은 640에서 971을 나누면 0.66이 되는 것입니다. 이렇게 분수화는 효율적인 연산을 위한 과정이라고 볼 수 있지만, 필수적인 과정은 아닙니다.
데이터셋에 따라, 바운딩 박스 값이 메타데이터로 따로 포함된 경우가 있으며, 메타데이터가 없을 경우 따로 코드 구현을 통해 바운딩 박스 지정이 가능합니다. 본 튜토리얼에서 사용하는 Face Mask Detection 데이터셋에는 바운딩 박스가 함께 제공되며, 2장에서 바운딩 박스 도식화를 진행해보겠습니다.
1.2. 모델 형태¶
객체 탐지 모델은 크게 One-Stage 모델과 Two-Stage 모델로 구분할 수 있습니다. 각각의 모델 형태에 대해서 알아보도록 하겠습니다.

그림 1-4 객체 탐지 알고리즘 타임라인 (출처: Zou et al. 2019. Object Detection in 20 Years: A Survey)
그림 1-4는 객체 탐지 모델의 계보도를 나타내고 있습니다. 2012년 이후 등장한 딥러닝 기반의 객체 탐지 모델 종류는 One-Stage Detector, Two-Stage Detector로 나눌 수 있습니다. 두 종류의 흐름을 이해하기 위해선 Classification과 Region Proposal의 개념을 이해해야 합니다. Classification은 특정 물체에 대해 어떤 물체인지 분류를 하는 것이고, Region Proposal은 물체가 있을만한 영역을 빠르게 찾아내는 알고리즘 입니다.
Two-Stage Detector은 객체를 검출하는 정확도 측면에서는 좋은 성능을 냈지만, 예측 속도가 느려 실시간 탐지에는 제한됐습니다. 이러한 속도 문제를 해결하기 위해 Classification과 Region Propsal을 동시에 하는 One-Stage Detector가 제안되었습니다. 다음 절에서 One-Stage Detector와 Two-Stage Detector의 구조도를 확인해보도록 하겠습니다.
1.2.1. One-Stage Detector¶
One-stage Detector는 Classification, Regional Proposal을 동시에 수행하여 결과를 얻는 방법입니다. 그림 1-5와 같이 이미지를 모델에 입력 후, Conv Layer를 사용하여 이미지 특징을 추출합니다.

그림 1-5 One-Stage Detector 구조(출처:https://jdselectron.tistory.com/101)
1.2.2. Two-Stage Detector¶
Two-stage Detector는 Classification, Regional Proposal을 순차적으로 수행하여 결과를 얻는 방법입니다. 그림 1-6과 같이 Region Proposal과 Classification을 순차적으로 실행하는 것을 알 수 있습니다.

그림 1-6 Two-Stage Detector 구조(출처:https://jdselectron.tistory.com/101)
결과적으로 One-Stage Detector는 비교적 빠르지만 정확도가 낮고, Two-Stage Detector는 비교적 느리지만 정확도가 높습니다.
1.3. 모델 구조¶
One-Stage Detector와 Two-stage Detector 별로 여러 구조가 존재합니다. R-CNN, Fast R-CNN, Faster R-CNN은 Two-Stage Detector이며 YOLO, SSD, RetinaNet은 One-Stage Detector입니다. 각각의 모델 구조 특성에 대해 알아보도록 하겠습니다.
1.3.1. R-CNN¶

그림 1-8 R-CNN 구조 (출처: Girshick et al. 2014. Rich feature gierarchies for accurate object detection and semantic segmentation)
R-CNN은 Selective Search를 이용해 이미지에 대한 후보영역(Region Proposal)을 생성합니다. 생성된 각 후보영역을 고정된 크기로 wrapping하여 CNN의 input으로 사용합니다. CNN에서 나온 Feature map으로 SVM을 통해 분류, Regressor을 통해 Bounding-box를 조정합니다. 강제로 크기를 맞추기 위한 wrapping으로 이미지의 변형이나 손실이 일어나고 후보영역만큼 CNN을 돌려야하하기 때문에 큰 저장공간을 요구하고 느리다는 단점이 있습니다.
1.3.2. Fast R-CNN¶
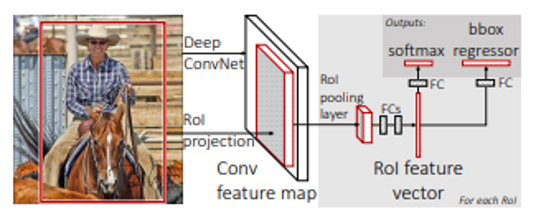
그림 1-9 Fast R-CNN 구조 (출처: Girshick. ICCV 2015. Fast R-CNN)
각 후보영역에 CNN을 적용하는 R-CNN과 달리 이미지 전체에 CNN을 적용하여 생성된 Feature map에서 후보영역을 생성합니다. 생성된 후보영역은 RoI Pooling을 통해 고정 사이즈의 Feature vector로 추출합니다. Feature vector에 FC layer를 거쳐 Softmax를 통해 분류, Regressor를 통해 Bounding-box를 조정합니다.
1.3.3. Faster R-CNN¶


그림 1-10 Faster R-CNN 구조 (출처: Ren et al. 2016. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
Selective Search 부분을 딥러닝으로 바꾼 Region Proposal Network(RPN)을 사용합니다. RPN은 Feature map에서 CNN 연산시 sliding-window가 찍은 지점마다 Anchor-box로 후보영역을 예측합니다. Anchor-box란 미리 지정해놓은 여러 개의 비율과 크기의 Bounding-box입니다. RPN에서 얻은 후보영역을 IoU순으로 정렬하여 Non-Maximum Suppression(NMS) 알고리즘을 통해 최종 후보영역을 선택합니다. 선택된 후보영역의 크기를 맞추기 위해 RoI Pooling을 거치고 이후 Fast R-CNN과 동일하게 진행합니다.
1.3.4. YOLO¶

그림 1-11 YOLO 구조 (출처: Redmon et al. 2016. You Only Look Once: Unified, Real-Time Object Detection)
Bouning-box와 Class probability를 하나의 문제로 간주하여 객체의 종류와 위치를 한번에 예측합니다.이미지를 일정 크기의 그리드로 나눠 각 그리드에 대한 Bounding-box를 예측합니다. Bounding-box의 confidence score와 그리드셀의 class score의 값으로 학습하게 됩니다. 간단한 처리과정으로 속도가 매우 빠르지만 작은 객체에 대해서는 상대적으로 정확도가 낮습니다.
1.3.5. SSD¶

그림 1-12 SSD 구조 (출처: Liu et al. 2016. SSD: Single Shot MultiBox Detector)
각 Covolutional Layer 이후에 나오는 Feature map마다 Bounding-box의 Class 점수와 Offset(위치좌표)를 구하고, NMS 알고리즘을 통해 최종 Bounding-box를 결정합니다. 이는 각 Feature map마다 스케일이 다르기 때문에 작은 물체와 큰 물체를 모두 탐지할 수 있다는 장점이 있습니다.
1.3.6. RetinaNet¶

그림 1-13 Focal Loss (출처: Lin et al. 2018. Focal Loss for Dense Object Detection)
RetinaNet은 모델 학습시 계산하는 손실 함수(loss function)에 변화를 주어 기존 One-Stage Detector들이 지닌 낮은 성능을 개선했습니다. One-Stage Detector는 많게는 십만개 까지의 후보군 제시를 통해 학습을 진행합니다. 그 중 실제 객체인 것은 일반적으로 10개 이내 이고, 다수의 후보군이 background 클래스로 잡힙니다. 상대적으로 분류하기 쉬운 background 후보군들에 대한 loss값을 줄여줌으로써 분류하기 어려운 실제 객체들의 loss 비중을 높이고, 그에 따라 실제 객체들에 대한 학습에 집중하게 합니다. RetinaNet은 속도 빠르면서 Two-Stage Detector와 유사한 성능을 보입니다