1. 자연어 처리 모델 소개 (Introduction to NLP Model)¶
![]()
언어 모델 (Language Model) 문장 혹은 단어에 확률을 할당하여 컴퓨터가 처리할 수 있도록 하는 모델입니다. 한발 나아가 언어 모델링 (Language Modeling)은 기존의 데이터셋을 바탕으로 주어진 태스크 안에서의 단어 혹은 문장을 예측하는 작업을 뜻 합니다. 자연어 처리 (Natural Language Processing)에서 자연어는 말그대로 인간이 사용하는 언어를 뜻하며, 다른 종류의 언어는 컴퓨터 언어 (Computer Language), 수화 (Sign Language), 몸짓 언어 (Body Language) 등이 있습니다. 자연어를 컴퓨터가 처리하는 과정을 프로세싱 (Processing)이라는 표현을 붙여 자연어 처리 (Natural Language Processing)라고 일컫습니다.
자연어 처리를 위해서는 전처리 (preprocessing)이 필수적이며, 이후 여러가지 언어 모델을 통하여, 문제 생성 작업을 해보도록 하겠습니다. 이번 튜토리얼에서는 전통적으로 사용되었던 통계 기반의 언어 모델이 아닌, 최근 자주 사용되는 딥러닝 기반 자연어 처리 모델을 다룹니다.
전이 학습 (Transfer Learning)은 자연어 처리 분야에 있어서 경이로운 발전을 가져왔습니다. 구글의 BERT, OpenAI의 GPT와 같은 전이 학습 모델은 성능이 좋기로 유명합니다. 이후에도 XLNet, RoBERTa, T5와 같이 전이 학습이 다양한 방법에 사용될 수 있도록 개발되고 있습니다. 이번 튜토리얼에서는 전이 학습 기반의 모델인 T5, BERT, GPT-2를 통해 문제 생성 작업을 수행하고자 합니다.
1.1 문제 생성 작업 (Question Generation Task)¶
문제 생성 작업에 대한 분류는 학자에 따라 다양하게 나눠집니다. 우선 이번 챕터에서는 Kurdi et al.의 “A Systematic Review of Automatic Question Generation for Educational Purposes” 연구 기반으로 설명을 하도록 하겠습니다. 문제 생성 과정에 있어서 크게 이해 단계와 생성 과정이 있습니다. 인풋 데이터인 문장을 받아, 컴퓨터가 이해하는 과정을 이해 관계라고 봅니다. 이러한 이해 과정을 거친 후 인풋 데이터를 바탕으로 문제 생성을 하는 과정을 생성 과정이라고 합니다.
이해 단계에서는 구문론 기반 (syntax-based)과 의미론 기반 (semantic-based) 접근법이 있습니다.
구문론 기반 접근법은 텍스트의 구문론 트리(syntax tree)와 같은 인풋을 입력하여 문제를 생성합니다. 예를 들어, 구문론 기반 모델은 문장 내의 단어 의미와 상관없이, 품사 (Part of Speech) 태깅을 통해, 문장 내의 구문 특징을 추출하여, 품사 간의 관계를 파악하여 문제 생성을 결정하게 됩니다.
의미론 기반 전근법은 문장 속에 의미 관계를 파악하여 문제를 생성합니다. 구문론적 접근 방법을 뛰어 넘어, 인풋 데이터를 한층 깊게 이해 할 필요가 있는데, 단순히 품사의 의미를 추출하기 보다는, 품사 간의 의미를 유추 할 수 있어야 합니다. 예를 들어, bank의 의미는 은행 일수도 있고, 제방 일수도 있습니다. 이는 문단 안에서 해당 단어의 관계에 의해 의미가 특정됩니다.
생성 과정에 있어서 템플릿 (template), 규칙 (rule), 그리고 통계적인 방법 (statistical methods)이 있습니다.
템플릿 기반 (template-based)의 경우, 문제 구조의 템플릿을 정해 놓고, 텍스트의 의미 또는 구문론적인 접근법을 통해 특징을 추출하여 문제를 생성합니다. 규칙 접근법은 문장 안에 품사들의 주석(annotations) 정보를 이용하여, 문제를 생성합니다. 예를 들어, where, which, when과 같은 wh의문사 문제를 생성하는 작업이라면, 해당 자리에 wh가 들어가는 품사 주석의 정보를 받아 wh의문사 문제를 생성하게 됩니다. 마지막으로, 통계적 접근 방법은 시퀀스-투-시퀀스(sequence-to-sequence)가 대표적입니다. 데이터셋을 학습시켜 문장에서 어떤 단어가 나타날 수 있는 확률을 이용하여, 문제를 생성하게 됩니다. 하지만 학습한 코퍼스 안에 단어 시퀀스가 없다면, 확률이 0 또는 정의되지 않아 정확하게 단어를 예측하기 못하는 문제가 발생하기도 하는데, 이를 희소 문제(the Sparsity Problem)라고 합니다. 이를 해결하기 위해, n-gram과 같은 방법이 사용되지만, 여전히 통계적 접근 방법의 한계를 뛰어 넘지 못합니다.
다음으로 문제 생성 작업에 사용할 T5, BERT, GPT 모델에 대해서 간략히 살펴보도록 하겠습니다.
1.2 T5¶
T5 모델은 “Text-to-Text Transfer Transformer”에서 각각의 앞글자 T가 5번 나와서 붙혀진 명칭입니다. T5 모델은 “Colossal Clean Crawled Corpus” (C4) 데이터셋으로 사전 훈련된 모델입니다. C4 데이터셋은 텍스트 데이터로서 텍스트에 레이블이 되지 않은 거대한 데이터셋이며, T5 모델 학습을 위해 제작된 데이터셋입니다.

그림 1-1 T5 모델 작동원리 시각화 (출처: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
C4 데이터셋으로 사전 훈련된 T5 모델은 다양한 다운스트림 작업에 맞게 조정이 될 수 있도록 설계되었습니다. 예를 들어, 그림 1-1에서 보듯이 기계 번역, 질의 응답, 텍스트 요약과 같은 작업을 T5 모델에서는 손쉽게 가능하게 되었습니다. 이처럼 입력 범위 내에서만 출력할 수 있는 BERT와는 달리, T5 모델은 텍스트와 텍스트(text-to-text) 형식으로 입력 및 출력을 하는 이점이 있습니다.
1.3 BERT¶
BERT (Bidirectional Encoder Representations from Transformers)는 2019년 10월 25일 구글 리서치 팀에 의해 공개된 자연어처리 사전 훈련 모델입니다. BERT 모델은 100여개가 넘는 언어 학습을 지원하며, BERT-Base, BERT-Large, BERT-Base, Multilingual, 그리고 BERT-Base, Chinese 모델이 있습니다. 각각의 모델 뒤에 Cased와 Uncased가 붙혀져 있는데, Uncased의 경우 대소문자 구분을 하지 않는 모델입니다.
BERT를 이용하여 특정 과제를 수행할 수 있는데요, 이를 위해서는 세부적인 과제를 수행하도록 파인튜닝(fine-tuning) 작업이 필요합니다. BERT은 사전 학습된 언어모델로서 파인튜닝을 통해, 원하는 작업을 수행할 수 있습니다. 사전 학습된 언어모델을 이용하여 다운스트림 작업(down-stream tasks)을 수행할 수 있는 방법에는 feature-based와 파인튜닝(fine-tuning) 방식이 있습니다. feature-based 접근법에는 Word2Vec, GloVe, ELMo와 같은 방식이 있으며, 파인튜닝(fine-tuning) 방식에는 대표적으로 GPT 모델이 있습니다.
BERT가 발표 되었을 당시, GPT-2와 비교를 많이 했는데요, 두 모델 모두 파인튜닝(fine-tuning) 방식을 사용하지만, GPT-2는 단방향(unidirectional) 언어 모델인 반면, BERT는 양방향(bidirectional) 언어 모델로서 차이가 있었습니다. 향후 GPT를 개발한 OpenAI에서는 BERT처럼 양방향 언어 모델인 GPT-3를 내놓게 됩니다.
양방향 언어 모델의 장점은 fill-in-the-blanks와 같이 앞뒤 문맥에 맞게 빈칸에 알맞은 단어를 추측하는 작업에 아주 높은 성능을 보여주고 있습니다.
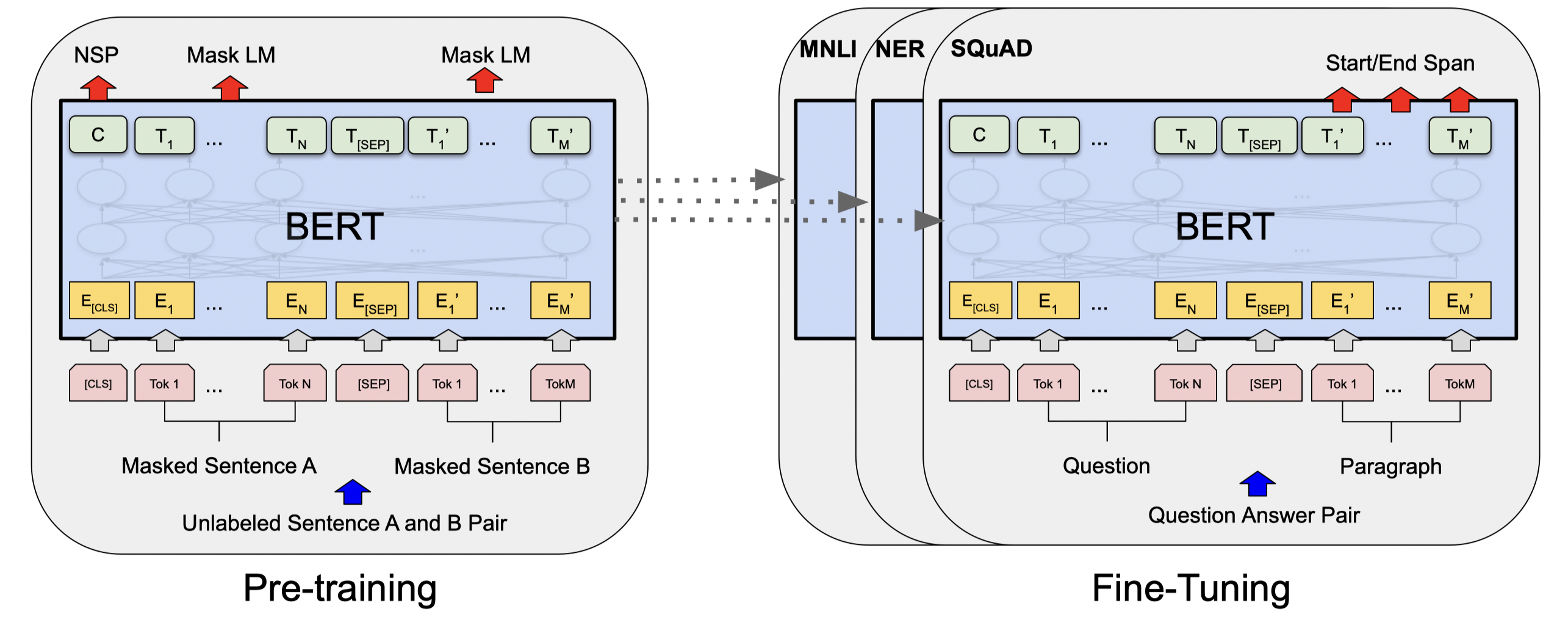
그림 1-2 BERT 모델 선행학습과 파인튜닝 시각화 (Devlin et al.)
BERT 모델은 선행학습(pre-training)과 파인튜닝(fine-tuning) 두 가지 과정을 거칩니다. 선행학습 과정에서는 라벨이 부여되지 않은 데이터(unlabeled data)를 가지고 선행학습 작업을 통해 모델은 학습됩니다. 이후 파인튜닝 과정에서, BERT 모델은 선행학습된 파라미터로 시작하여, 라벨이 부여된 데이터(labeled data)를 사용하여 파인튜닝 작업을 진행하게 됩니다.
BERT 모델을 파인튜닝하여 단어 예측, 문제 생성, 감성 분석과 같은 다양한 작업을 수행 할 수 있으며, 이번 튜토리얼에서는 문제 생성 작업 용도로 활용해보도록 하겠습니다.
1.4 GPT¶
GPT 모델은 일론 머스크와 샘 알트만이 설립한 openAI에서 개발한 자연어 처리 모델입니다. GPT-1, GPT-2, GPT-3 순으로 공개되었는데, 2019년 GPT-2의 공개 후 엄청난 성능으로 많은 사람들을 놀라게 하였고, 2020년 6월에는 GPT-3로 전세계 인공지능계에 또 한 번 돌풍을 몰고 왔습니다.
하지만 GPT 모델이 완벽한 것은 아닙니다. GPT-2는 단방향(unidirectional) 언어 모델로서, 입력 프롬프트 다음에 나오는 단어를 예측하도록 훈련이 되어 있습니다. 이는 양방향(bidirectional) 언어 모델인 BERT에 비해 단점이 뚜렷하다는 지적을 받았습니다. 하지만, 2019년에 단방향 언어 모델인 GPT-2의 진가를 보여주는 작업이 있었는데, 바로 텍스트 생성 작업이었습니다. 인공지능을 이용한 텍스트 생성 작업에 있어서 단방향 모델이 양방향 모델보다 뛰어난 성능을 보여준 것 입니다. GPT-1은 1억1천7백만개의 파라미터를 가지고 있고, GPT-2는 GPT-1보다 약 12.8배 많은 15억4천2백만개의 파라미터를 가지고 있고, 약 800만개의 문서, 40GB 용량의 데이터셋을 학습시킨 모델입니다.

그림 1-3 BERT, T5, GPT-3 모델 학습 시간 (Brown, et al.)
2020년 6월에 발표된 GPT-3는 비약적인 발전을 이루게 됩니다. GPT-3는 GPT-2보다 약 12배 많은 1750억개의 파라미터를 가지고 있으며, 필터 전 45TB, 필터 후 570GB 크기의 방대한 데이터셋을 학습시킨 모델입니다. 그림 1-3에서 보듯이, GPT-3 학습 시간은 BERT와 T5 모델을 상회할 만큼 방대한 모델임을 짐작할 수 있습니다.
1.5 결론¶
이번장에서는 전이 학습 기반의 모델인 T5, BERT, GPT 모델을 간단하게 살펴보았습니다. 다음장에서는 튜토리얼에 사용할 데이터셋을 살펴보고, 3장과 4장에서는 T5, BERT, GPT 모델을 이용하여 문제 생성 작업을 수행하고자 합니다.
1.6 출처¶
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Kurdi, G., Leo, J., Parsia, B., Sattler, U., & Al-Emari, S. (2020). A systematic review of automatic question generation for educational purposes. International Journal of Artificial Intelligence in Education, 30(1), 121-204.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
Roberts, A., & Raffel, C. (2020). Exploring Transfer Learning with T5: The Text-To-Text Transfer Transformer. (https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)