3. MC 문제¶
![]()
이전 장에서는 실습에 사용할 데이터셋을 다운로드하고 시각화하며 전처리를 진행해보았습니다. 이번 장에서는 해당 데이터셋을 이용하여 MC 문제를 생성하는 모델을 실습해보도록 하겠습니다.
3.1절에서는 문제를 생성하는 데에 사용되는 GPT-2와 BERT 모델을 소개하고, 3.2절에서는 데이터를 불러와서 다시 한 번 살펴봅니다. 이어 3.3절에서는 T5 모델을 이용하여 Text 데이터를 요약하는 작업을 진행하며, 마지막으로 3.4절에서는 텍스트 속의 문장들을 필터링하고 GPT-2와 BERT를 이용하여 MC 문제를 생성해보도록 하겠습니다.
MC 문제를 생성하는 과정은 크게 5단계로 설명될 수 있습니다. 가장 먼저 MC 문제를 생성하기 위한 지문이 되는 텍스트로부터 주요 문장들을 추출하여 요약합니다. 두번째, 추출된 주요 문장들을 유사 어휘와 어구를 활용하여 변환하며(pharaphrasing) 세번째, 이 변환된 문장들을 파싱합니다. 네번째로 이 파싱된 문장들과 GPT-2 모델을 이용해 거짓 문장을 생성하고, 마지막으로 유사도를 평가해서 정답 문장과 가장 유사하지 않은 문장들을 오답 선택지로 활용합니다. 이 과정은 3.2절부터 순서대로 확인할 수 있습니다.
3.1 GPT2 & BERT¶
3.1.1 GPT2¶
GPT-2는 OpenAI에서 개발한 GPT-N 시리즈의 2번째 자연어처리 모델입니다. GPT-2는 8백만 개의 웹페이지 데이터셋과 15억 개의 파라미터로부터 학습된 트랜스포머 기반 자연어처리 모델이며 이전의 단어들을 포함하는 텍스트 다음에 올 단어를 예측하는 것을 목적으로 짜여진 모델입니다. 우리는 MC 문제 생성 태스크에서 거짓 문장을 생성하는 데에 GPT-2를 활용하게 됩니다.
3.1.2 BERT¶
BERT는 Bidirectional Encoder Representations from Transformers 의 약어로 구글에서 2018년 개발한 자연어처리 모델입니다. BERT는 Transformer를 기반으로 Sentence Embedding 혹은 Contextual Word Embedding을 구하는 네트워크로, 문장을 토큰 단위로 쪼개서 네트워크에 넣으면 전체 문장에 대한 vector와 문장 안의 단어 각각에 대응되는 vector를 출력합니다. 이를 기반으로 Text Classification 등의 Task를 학습하여 수행할 수 있습니다.
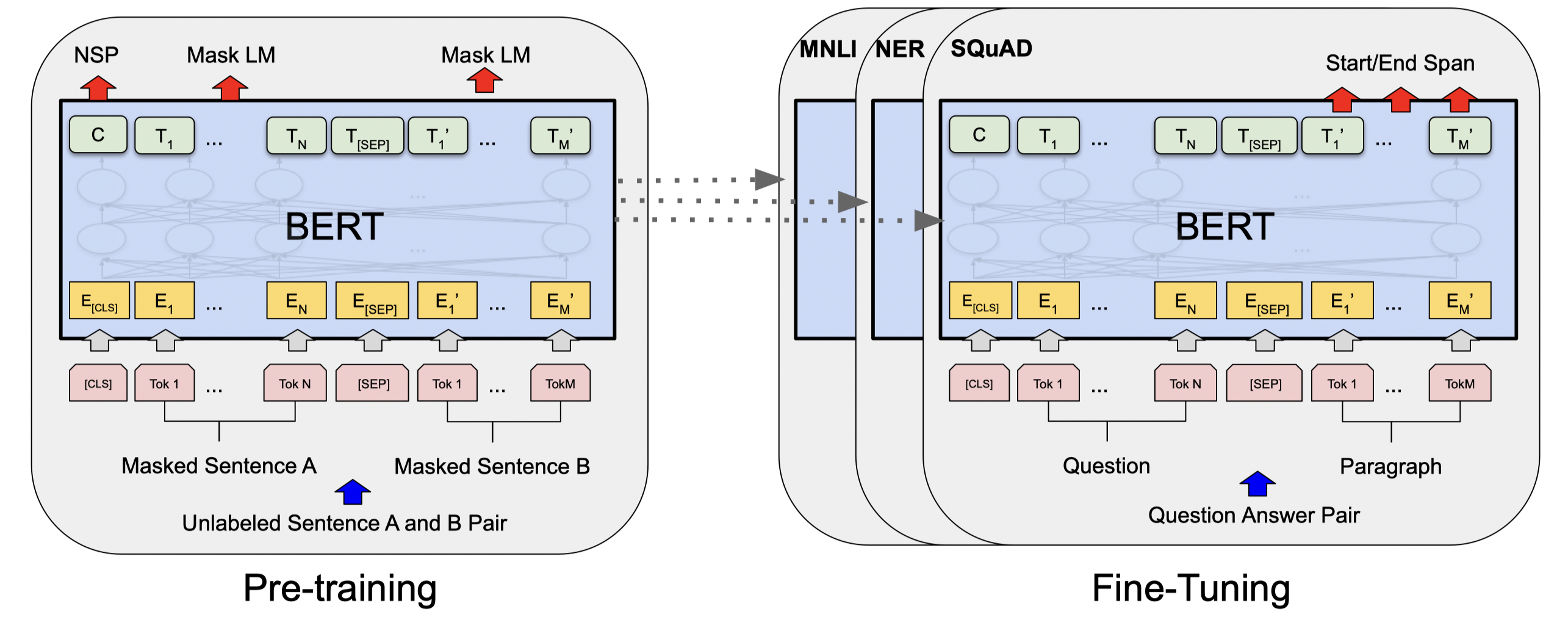
그림 3.1 전반적인 BERT의 pre-training 과정과 fine-tuning 과정 (출처: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)
NLP Task 성능 평가와 관련하여 다양한 NLP Task들의 성능을 바탕으로 모델들의 순위를 매기는 GLUE Benchmark(General Language Understatnding Evaluation Benchmark)라는 collection이 있는데, BERT는 여기에서 OpenAI GPT 등의 다른 모델들을 큰 차이로 앞서며 그 당시 최고의 성능을 보여 주었습니다.
3.2 데이터셋 다운로드¶
2장에서 나온 코드를 활용하여 데이터셋을 불러오도록 하겠습니다. 데이터셋은 올바른 문법으로 수정이 된 에세이 텍스트 데이터입니다. 이 데이터는 MC 문제를 만들 지문으로 사용됩니다. 데이터를 읽어 오기 위해서 pickle 패키지를 이용합니다.
import pickle
!git clone https://github.com/Pseudo-Lab/Tutorial-Book-Utils
!python Tutorial-Book-Utils/PL_data_loader.py --data NLP-QG
file_name = "CoNLL+BEA_corrected_essays.pkl"
open_file = open(file_name, "rb")
data = pickle.load(open_file)
open_file.close()
Cloning into 'Tutorial-Book-Utils'...
remote: Enumerating objects: 30, done.
remote: Counting objects: 100% (30/30), done.
remote: Compressing objects: 100% (24/24), done.
remote: Total 30 (delta 9), reused 18 (delta 5), pack-reused 0
Unpacking objects: 100% (30/30), done.
CoNLL+BEA_corrected_essays.pkl is done!
!pip install -q benepar
!pip install -q sentence_transformers
import requests
import json
import benepar
import string
import nltk
from nltk import tokenize
from nltk.tokenize import sent_tokenize
from string import punctuation
import re
from random import shuffle
import spacy
import warnings
import torch
import pandas as pd
import numpy as np
import scipy
torch.manual_seed(42)
warnings.filterwarnings(action='ignore')
nlp = spacy.load('en')
nltk.download('punkt')
benepar.download('benepar_en3')
benepar_parser = benepar.Parser("benepar_en3")
|████████████████████████████████| 3.3 MB 23.1 MB/s
|████████████████████████████████| 2.5 MB 45.7 MB/s
|████████████████████████████████| 1.2 MB 44.4 MB/s
|████████████████████████████████| 895 kB 43.9 MB/s
?25h Building wheel for benepar (setup.py) ... ?25l?25hdone
|████████████████████████████████| 85 kB 3.6 MB/s
?25h Building wheel for sentence-transformers (setup.py) ... ?25l?25hdone
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
[nltk_data] Downloading package benepar_en3 to /root/nltk_data...
[nltk_data] Unzipping models/benepar_en3.zip.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
def preprocess(sentences):
output = []
for sent in sentences:
single_quotes_present = len(re.findall(r"['][\w\s.:;,!?\\-]+[']",sent))>0
double_quotes_present = len(re.findall(r'["][\w\s.:;,!?\\-]+["]',sent))>0
question_present = "?" in sent
if single_quotes_present or double_quotes_present or question_present :
continue
else:
output.append(sent.strip(punctuation))
return output
def get_flattened(t):
sent_str_final = None
if t is not None:
sent_str = [" ".join(x.leaves()) for x in list(t)]
sent_str_final = [" ".join(sent_str)]
sent_str_final = sent_str_final[0]
return sent_str_final
def get_termination_portion(main_string,sub_string):
combined_sub_string = sub_string.replace(" ","")
main_string_list = main_string.split()
last_index = len(main_string_list)
for i in range(last_index):
check_string_list = main_string_list[i:]
check_string = "".join(check_string_list)
check_string = check_string.replace(" ","")
if check_string == combined_sub_string:
return " ".join(main_string_list[:i])
return None
def get_right_most_VP_or_NP(parse_tree,last_NP = None,last_VP = None):
if len(parse_tree.leaves()) == 1:
return get_flattened(last_NP),get_flattened(last_VP)
last_subtree = parse_tree[-1]
if last_subtree.label() == "NP":
last_NP = last_subtree
elif last_subtree.label() == "VP":
last_VP = last_subtree
return get_right_most_VP_or_NP(last_subtree,last_NP,last_VP)
def get_sentence_completions(key_sentences):
sentence_completion_dict = {}
for individual_sentence in key_sentences:
sentence = individual_sentence.rstrip('?:!.,;')
tree = benepar_parser.parse(sentence)
last_nounphrase, last_verbphrase = get_right_most_VP_or_NP(tree)
phrases= []
if last_verbphrase is not None:
verbphrase_string = get_termination_portion(sentence,last_verbphrase)
if verbphrase_string is not None:
phrases.append(verbphrase_string)
if last_nounphrase is not None:
nounphrase_string = get_termination_portion(sentence,last_nounphrase)
if nounphrase_string is not None:
phrases.append(nounphrase_string)
longest_phrase = sorted(phrases, key=len, reverse=True)
if len(longest_phrase) == 2:
first_sent_len = len(longest_phrase[0].split())
second_sentence_len = len(longest_phrase[1].split())
if (first_sent_len - second_sentence_len) > 4:
del longest_phrase[1]
if len(longest_phrase)>0:
sentence_completion_dict[sentence]=longest_phrase
return sentence_completion_dict
def sort_by_similarity(original_sentence, generated_sentences_list):
sentence_embeddings = bert_model.encode(generated_sentences_list)
queries = [original_sentence]
query_embeddings = bert_model.encode(queries)
number_top_matches = len(generated_sentences_list)
dissimilar_sentences = []
for query, query_embedding in zip(queries, query_embeddings):
distances = scipy.spatial.distance.cdist([query_embedding], sentence_embeddings, "cosine")[0]
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
for idx, distance in reversed(results[0:number_top_matches]):
score = 1-distance
# print(score)
if score < 0.99:
dissimilar_sentences.append(generated_sentences_list[idx].strip())
sorted_dissimilar_sentences = sorted(dissimilar_sentences, key=len)
return sorted_dissimilar_sentences[:2]
def generate_sentences(partial_sentence,full_sentence):
input_ids = gpt2_tokenizer.encode(partial_sentence, return_tensors='pt') # use tokenizer to encode
input_ids = input_ids.to(device)
maximum_length = len(partial_sentence.split())+80
sample_outputs = gpt2_model.generate(
input_ids,
do_sample=True,
max_length=maximum_length,
top_p=0.90,
top_k=50,
repetition_penalty = 10.0,
num_return_sequences=5
)
generated_sentences=[]
for i, sample_output in enumerate(sample_outputs):
decoded_sentences = gpt2_tokenizer.decode(sample_output, skip_special_tokens=True)
decoded_sentences_list = tokenize.sent_tokenize(decoded_sentences)
generated_sentences.append(decoded_sentences_list[0]) # takes the first sentence
top_3_sentences = sort_by_similarity(full_sentence, generated_sentences)
return top_3_sentences
## load models
from transformers import AutoModelWithLMHead, AutoTokenizer, AutoModelForSeq2SeqLM
import torch
summarize_tokenizer = AutoTokenizer.from_pretrained("t5-small")
paraphrase_tokenizer = AutoTokenizer.from_pretrained("Vamsi/T5_Paraphrase_Paws")
gpt2_tokenizer = AutoTokenizer.from_pretrained("gpt2")
summarize_model = AutoModelWithLMHead.from_pretrained("t5-small")
paraphrase_model = AutoModelForSeq2SeqLM.from_pretrained("Vamsi/T5_Paraphrase_Paws")
# add the EOS token as PAD token to avoid warnings
gpt2_model = AutoModelWithLMHead.from_pretrained("gpt2", pad_token_id=gpt2_tokenizer.eos_token_id)
summarize_model.to(device)
paraphrase_model.to(device)
gpt2_model.to(device)
from sentence_transformers import SentenceTransformer
bert_model = SentenceTransformer('bert-base-nli-mean-tokens')
bert_model.to(device)
df_TFQuestions = pd.DataFrame({'id': np.zeros(20),
'passage': np.zeros(20),
'distractor_1': np.zeros(20),
'distractor_2': np.zeros(20),
'distractor_3': np.zeros(20),
'distractor_4': np.zeros(20)})
A: raw
A’: paraphrased
A_False: false
distractor_1: A’
distractor_2: A’_False
distractor_3: B’_False
distractor_4: C’_False
## main.py
import random
random.seed(42)
passage_id_list = [163,
28,
62,
57,
35,
26,
22,
151,
108,
55,
59,
129,
167,
143,
50,
161,
107,
56,
114,
71]
for id_idx in range(20):
# select passage for question generation
passage_id = passage_id_list[id_idx]
passage = data[passage_id]
# summarize
inputs = summarize_tokenizer.encode("summarize: " + passage, return_tensors="pt", max_length=512)
inputs = inputs.to(device)
outputs = summarize_model.generate(inputs, max_length=300, min_length=100, length_penalty=2.0, num_beams=4, early_stopping=True)
extractedSentences = summarize_tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
tokenized_sentences = nltk.tokenize.sent_tokenize(extractedSentences)
filter_quotes_and_questions = preprocess(tokenized_sentences)
# paraphrase
paraphrased_sentences = []
for summary_idx in range(len(filter_quotes_and_questions)):
sentence = filter_quotes_and_questions[summary_idx]
inputs = "paraphrase: " + sentence + " </s>"
encoding = paraphrase_tokenizer.encode_plus(inputs, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"].to(device), encoding["attention_mask"].to(device)
outputs = paraphrase_model.generate(
input_ids=input_ids, attention_mask=attention_masks,
max_length=256,
do_sample=True,
top_k=50,
top_p=0.95,
early_stopping=True,
num_return_sequences=3
)
paraphrased_sentences.append(paraphrase_tokenizer.decode(outputs[0], skip_special_tokens=True,clean_up_tokenization_spaces=True))
if len(paraphrased_sentences) == 3:
print('3 filled')
break
if (summary_idx == (len(filter_quotes_and_questions) - 1)) & (len(paraphrased_sentences) < 3): # 마지막인데 채워지지 않았을 경우 존재하는 paraphrased sentence 반복해서 false 문장 생성
print(summary_idx)
print('hit')
for paraphrase_idx in range(1, 3):
paraphrased_sentences.append(paraphrase_tokenizer.decode(outputs[paraphrase_idx], skip_special_tokens=True,clean_up_tokenization_spaces=True))
sent_completion_dict = get_sentence_completions(paraphrased_sentences)
df_TFQuestions.loc[id_idx, 'id'] = passage_id
df_TFQuestions.loc[id_idx, 'passage'] = passage
df_TFQuestions.loc[id_idx, 'distractor_1'] = list(sent_completion_dict.keys())[0]
distractor_cnt = 2
for key_sentence in sent_completion_dict:
if distractor_cnt == 5:
break
partial_sentences = sent_completion_dict[key_sentence]
false_sentences =[]
# df_TFQuestions.loc[0, 'id'] =
# print_string = "**%s) True Sentence (from the story) :**"%(str(index))
# printmd(print_string)
# print (" ",key_sentence)
false_sents = []
for partial_sent in partial_sentences:
for repeat in range(10):
false_sents = generate_sentences(partial_sent, key_sentence)
if false_sents != []:
break
false_sentences.extend(false_sents)
df_TFQuestions.loc[id_idx, f'distractor_{distractor_cnt}'] = false_sentences[0]
distractor_cnt += 1
print(id_idx, 'complete')
df_TFQuestions
| id | passage | distractor_1 | distractor_2 | distractor_3 | distractor_4 | |
|---|---|---|---|---|---|---|
| 0 | 163.0 | The waters of the culinary seas had been calm ... | The microwave is the source of life that most ... | The microwave is the source of life that most ... | It uses radiation to excite water particles in... | The microwave cut cooking time in half, making... |
| 1 | 28.0 | The world is increasingly becoming flat with a... | Social network sites provide us with many conv... | Social network sites provide us with the tools... | We can know her recent news without hanging ou... | a piece of research shows that people will unc... |
| 2 | 62.0 | The best places for y... | The report looks at the best places to visit f... | The report looks at the best places to visit f... | It is based on a survey of young people from t... | It is based on my own opinion as a permanent r... |
| 3 | 57.0 | Puerquitour: A great experience for your mouth... | The place is Tacos La Chule and there are gour... | The place is Tacos La Chule and there are two ... | The name of the place is Tacos La Chule, and t... | The place is sooooo nice and the decoration an... |
| 4 | 35.0 | Nowadays, social media sites are commonly used... | 80% of people use social media sites to connec... | 80% of people use social media sites to connec... | They consist of the function of a particular n... | but there are also disadvantages that occur du... |
| 5 | 26.0 | Interpersonal skills, like any other skills re... | The growing use of social media has its benefi... | The growing use of social media has its benefi... | It is a good practice not to constantly add ne... | It is a good practice not to use social media." |
| 6 | 22.0 | Nowadays, with the advancement of technology, ... | A known genetic risk should not be obligated t... | A known genetic risk should not be obligated t... | The government should set the law to protect t... | However, a carrier of a known genetic risk can... |
| 7 | 151.0 | In this century there have been many technolog... | Television has brought other worlds into the l... | Television has brought other worlds into the l... | Television has the power to bring war into the... | In the minds of most Americans, television is ... |
| 8 | 108.0 | I met a friend about one week ago, and he aske... | It's about a teen couple who are dying of canc... | It's about a teen couple who are dying of canc... | It's about a teen couple who are dying of canc... | Now, I have an awful feeling about what I am d... |
| 9 | 55.0 | Dear Sir or Madam,\nI am writing to apply for ... | Camp counselor is currently advertised on your... | Camp counselor is currently advertised on the ... | At this moment, I have finished the second yea... | I am looking forward to hearing from you XYZ, ... |
| 10 | 59.0 | Anna knew that it was going to be a very speci... | She knew that it was going to be a very specia... | She knew that it was going to be a very specia... | She had known that she had been adopted since ... | After her 18th birthday, she felt a sudden nee... |
| 11 | 129.0 | On Britain's roads there is an ever-increasing... | The government has started adding a fourth lan... | The government has started adding a fourth lan... | There appears to be an endless series of roadw... | The inability to cope with the volume of traff... |
| 12 | 167.0 | According the Lunde, 35% of homicide victims a... | 35% of the homicide victims are killed by some... | 35% of the homicide victims are killed by some... | Today racial prejudice still exists, but less ... | It still exists racial prejudice, but has been... |
| 13 | 143.0 | "In Vitro fertilisation" is the fertilisation ... | In a test tube | In | The egg is taken from the mother and placed in... | There are people who are against this, saying ... |
| 14 | 50.0 | Dear Mrs. Ashby, \n\nYesterday I was in Green ... | I am very interested in this work and believe ... | I am very interested in this work and believe ... | I worked a year in London as a waiter at Hard ... | I am also very good at dealing with people, I ... |
| 15 | 161.0 | Computers have definitely affected peoples liv... | Computers have had a significant impact on peo... | Computers have had a significant impact on the... | Without the use of a computer, I have to balan... | I had to balance my checkbook once a month wit... |
| 16 | 107.0 | Cricket is my passion. I love playing, watchin... | Cricket is a team sport, which teaches us team... | Cricket is a team sport, which teaches us team... | It also teaches us how to overcome individual ... | Cricket is going through a rough phase due to ... |
| 17 | 56.0 | Well, I would like to talk about my school lif... | I'm a electronics student from Italy, North | I'm a electronics student from Michigan. | A chance to be a great engineer one day, so I ... | I am good at school, my marks prove it ; I hav... |
| 18 | 114.0 | I have been learning English as a second langu... | My teachers thought it was better to learn in ... | My teachers thought it was better to learn in ... | I had decided to take the Cambridge Advanced E... | One year ago, I decided to take the Cambridge ... |
| 19 | 71.0 | Glad to hear that you've been invited to att... | You've been invited to the last round of inter... | You've been invited to the last round of inter... | Here are some tips on how to make sure that yo... | First, the state's top elected officials are i... |
df_TFQuestions.to_csv('TFQuestions.csv', index=False)