Q&A
Contents
Q&A#
visual tokenizer를 사용하면 디테일한 부분은 취약한 성능을 보이지 않을까요?#
아 beit가 visual tokenizer를 사용해서 이미지를 토큰화한다고 했는데 이렇게 visual tokenizer로 토큰화하여 학습하면 디테일한 부분은 잘 못본다고 dalle논문(?)에서 본 것 같습니다. 그래서 cookbook 크기를 크게해서 이 부분을 보완했다고는 했는데 그래도 디테일한 부분은 좀 취약한 성능을 보이지 않을까요?
BEIT v2 논문에서 참고문헌 조사한 내용중에서 디테일한 부분을 보존하기 위한 방법으로 VQGAN이 있다고 소개하고 있는데 https://devocean.sk.com/blog/techBoardDetail.do?ID=164090 여기에 VQGAN에 대한 설명이 잘 되어 있네요
Aspect ratio of block을 지정하는 코드#
혹시 코드에서 Aspect ratio of block (0.3)이 하이퍼파라미터로 지정되어 있거나 특정 비율을 반영하는 부분이 따로 있을까요?

https://github.com/microsoft/unilm/blob/master/beit/masking_generator.py 이 파일의 MaskingGenerator 클래스에서 min_aspect값 초기값이 0.3으로 되어 있는데 변경해서도 넣어줄 수 있습니다.
self-superevised learning이 어떤 점을 보완하였나요?#
2 페이지 이부분에서 beit가 pretraining 시에 사용하는 self-superevised learning이 supervised learning을 보완한다라고 나와 있는데 어떤 점을 보완한다고는 안나와 있었던거 같습니다. 뒤에 나오는 ablation study에서 self-supervised pretraining 테크닉이 성능에 영향을 준다고만 나와 있습니다. 혹시 어떤 점을 보완하고 있는지 알 수 있는 부분이 있을까요?

저는 supervised learning의 경우 labeling 이 되어있는 데이터가 필요해서 비용이 많이 들지먼 self-supervised learning은 필요가 없어서 비용적인 면에서 보완한 것이라고 알고있습니다.
덧붙이자면, 6페이지 3.1 Image Classification 부분입니다. self-supervised 방식으로 pre-training을 하고 labeled ImageNet data로 intermediate fine-tuning 함으로써 보완한다는 내용이네요.

#
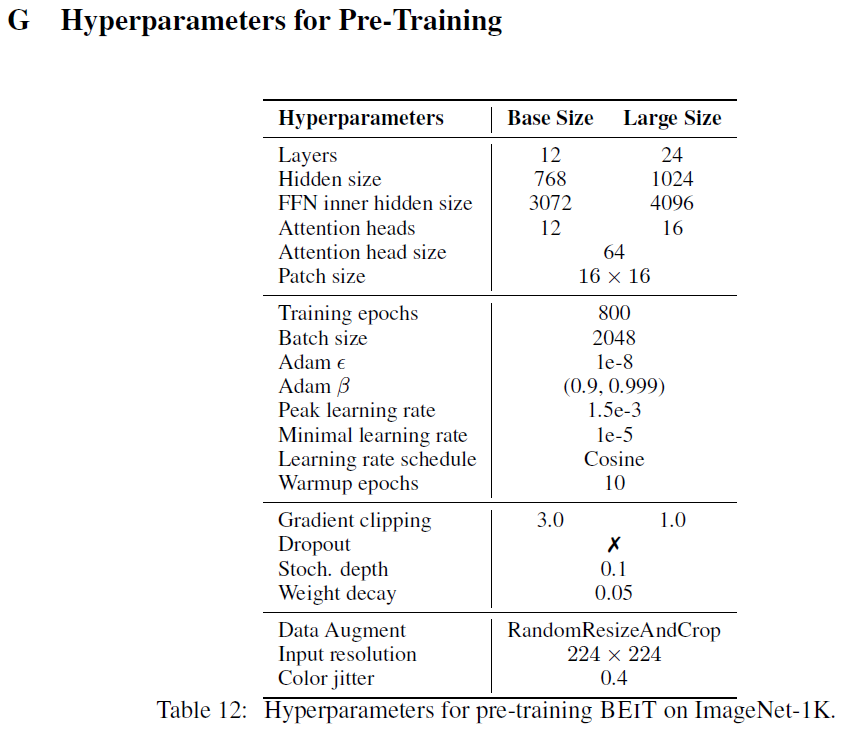
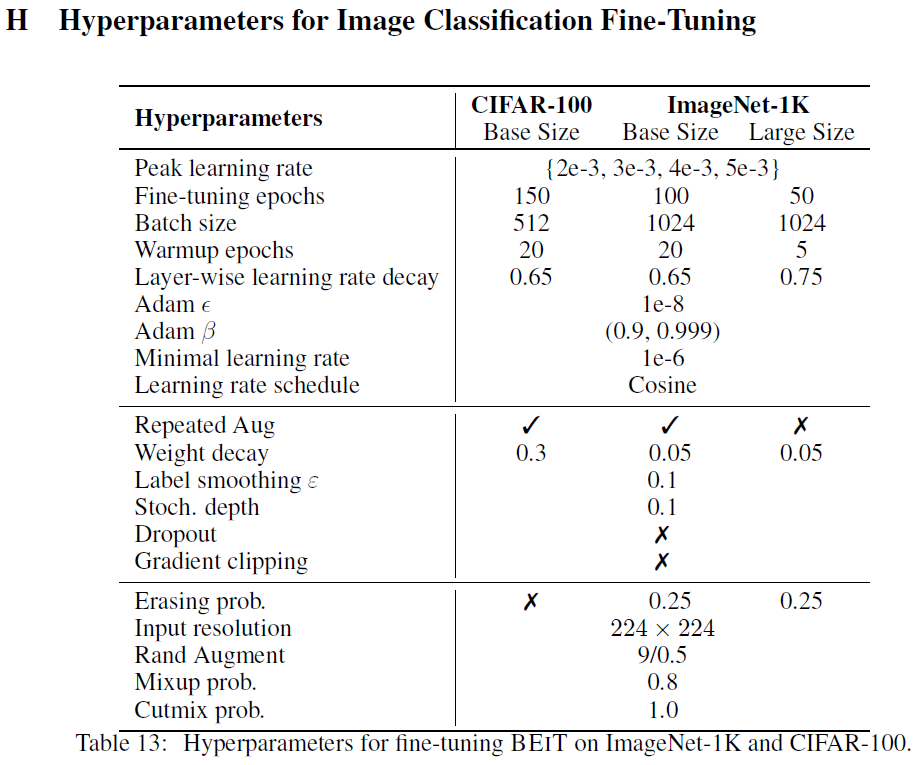
혹시 pre-train과 fine-tuning 할 때 learning rate를 어떻게 설정하는지 정확히 알고 있는 분 계신가요? 보통 미세조정 할 땐 over fitting을 막기 위해서 pre-train 할 때보다 적게 잡는걸로 알고 있었는데 논문에서는 더 크게 잡아줬다고 하고 있네요. 그만큼 epoch 수를 줄인다곤 하지만 상쇄가 될 지 궁금하네요..

Appendix를 보면 pre-train 할 때 peak가 1.5e-3, mininal이 1e-5고 fine-tuining이 peak가 제일 낮은게 2e-3, minimal 1e-6로 mininal에서는 fine-tuning lr이 더 낮긴 합니다. cosine 스케줄러로 알아서 가는건가 싶네요.
[Reference]
VAE
DALL-E
Edit by 김주영