Separable Self-attention for Mobile VisionTransformers
Contents
Separable Self-attention for Mobile VisionTransformers#
Introduction#
MobileViT는 CNN과 ViT의 장점을 가지는 light-weight network이다. 본 논문에서는 linear complexity를 가지는 separable self-attention을 소개한다.
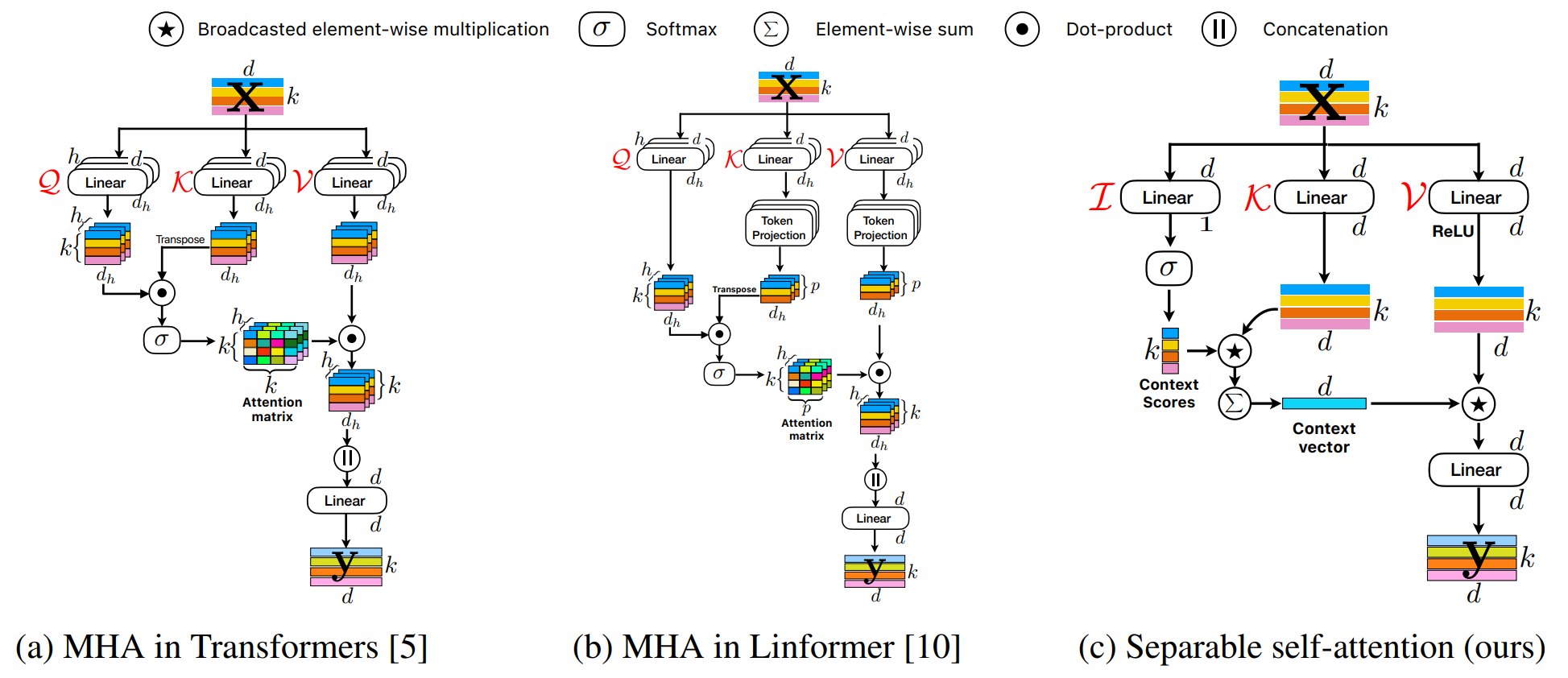
separaple self-attention은 위와 같이 quadratic MHA를 두 개의 linear computation으로 대체하면서 global information을 encoding 한다.
Separable self-attention#
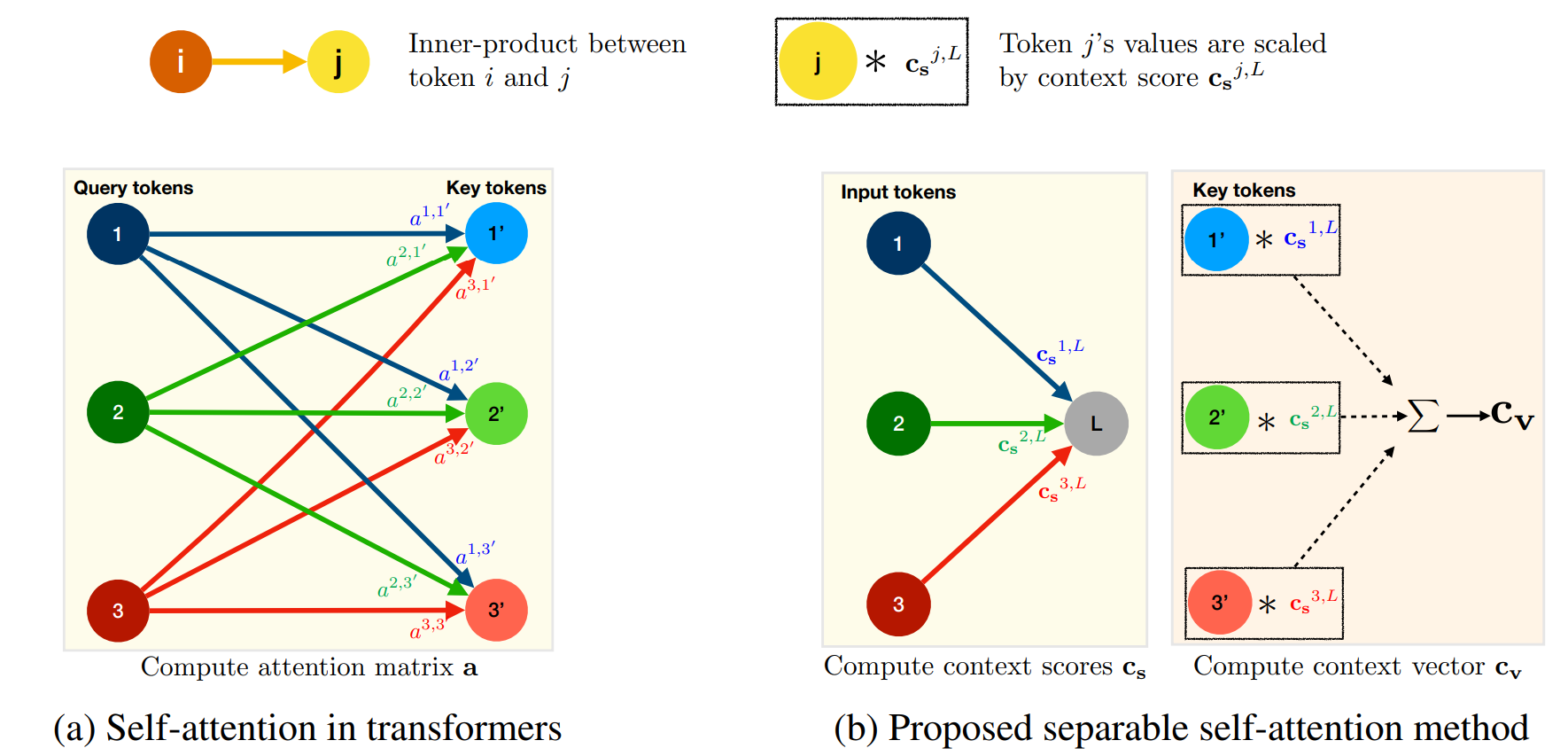
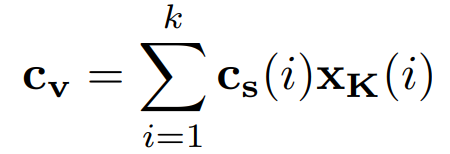
\(c_s\): context score
\(c_v\): context vector
\(x_K\): dxd 차원의 weight를 가지는 key를 사용하여 linearly projection
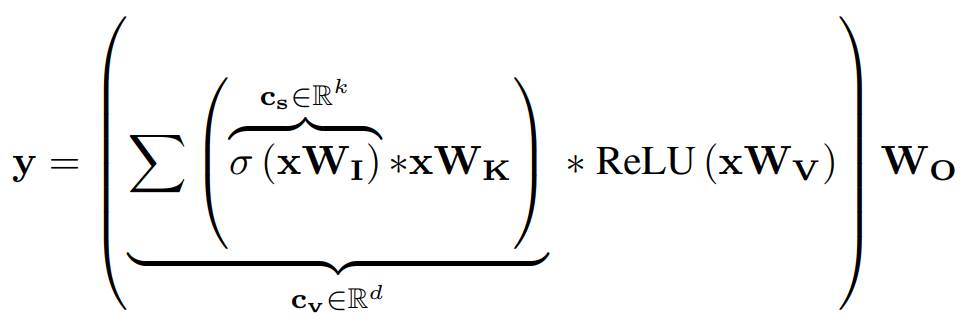
contextual information을 가지는 \(c_v\)는 \(ReLU(xW_v)\)와 element-wise multiplication을 하고 \(W_O\) weight를 가지는 linear layer를 통과한다.

[iPhone12에서의 측정 결과]
Author by 김주영
Edit by 김주영