안녕하세요, 가짜연구소 Groovy Graph 팀의 김주연입니다. 이 글은, ‘Graph Attention Network’ 논문을 읽고, 정리한 글 입니다. 논문을 읽고, 정리한 글 입니다.
이 글은 Reference 자료들을 참고하여 정리하였음을 먼저 밝힙니다. 혹시 내용중 잘못된 점이나 보완할 점 있다면 댓글로 알려주시면 감사하겠습니다. 그럼 시작하겠습니다.
목차
들어가기 앞서
Graph Neural Networks의 흐름(A Comprehensive Survey on Graph Neural Networks, 2019) [1]
- 그리드 구조에서 CNN은 좋은 성능(semantic segmentation, machine translation) → 학습된 파라미터를 local filter에 효율적으로 재사용 가능
- 하지만, 많은 구조들이 그리드 구조로 되어있지 않고 주로 그래프의 형태로 표현 (3D meshes, social networks, telecommunication networks, biological networks or brain connectomes)


Spectral approaches
- 그래프를 spectral 표현으로 인식, context of node classification에 성공적으로 적용(e.g. GCN)
- 그래프 라플라시안의 eigendecomposition을 계산함으로써 푸리에 도메인 안에서 convolution 연산
- Smooth coefficients의 spectral filter의 parameterization도입
- 그래프 라플라시안의 Chebyshev expansion 도입
- 마지막으로, 각 노드 주변의 1-hop 이웃에서 필터가 작동하도록 제한하여 방법 단순화
- 한계 : 학습된 필터는 그래프 구조에 의존하는 라플라시안 eigenbasis에 의존 → 특정 구조에 의해서 훈련된 모델은 구조가 다른 그래프에 적용 불가
Non-spectral approaches
- Convolution 을 직접 그래프에 적용, Central node와 그 이웃 노드들 간의 관계 모델링
- 각각의 node degree를 위한 weight matrix를 학습하는 방식
- GraphSAGE
Inductive 방식으로 노드의 representations을 계산하는 방식, 각 노드의 고정된 크기의 이웃을 샘플링 후 특정한 aggregator를 수행(이웃의 특징 벡터를 평균내어 샘플링)하고 결과를 recurrent neural network에 먹이는 방식
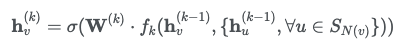
- GraphSAGE
Inductive 방식으로 노드의 representations을 계산하는 방식, 각 노드의 고정된 크기의 이웃을 샘플링 후 특정한 aggregator를 수행(이웃의 특징 벡터를 평균내어 샘플링)하고 결과를 recurrent neural network에 먹이는 방식
GAT
- Self-attention으로 노드 embedding layer가 정의, 노드의 embedding을 생성할 때 인접한 노드들에 대한 중요도를 계산하여 이를 기반으로 새로운 embedding 생성
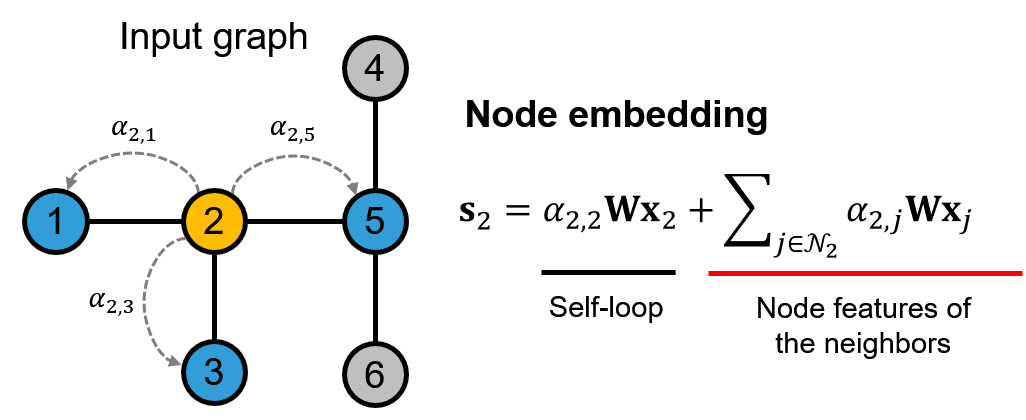
Self-attention Mechanism [3]

- Sequence-based task 주로 사용
- it 이 나타내는 것은?
- 이를 알기 위해서는 같이 입력된 문장 전체 고려
- 어떠한 입력을 이해하기 위해서 같이 입력된 요소들 중에서 무엇을 중요하게 고려햐아 하는가를 수치적으로 나타내는 기법 (가장 관련있는 부분에 초점)
-
Attention vs Self-attention종류 설명 Attention 방향이 정해졌을 때 자신보다 미래에 Input으로 들어갈 단어들은 활용 불가 Self-attention (Encoder측에서) 존재하는 모든 단어와 동시에 Attention 연산이 일어나기 때문에 문장에서 단어의 위차와 관계 없이 문장 내 모든 단어를 활용하여 연산 진행 - Attention 구조의 흥미로운 전략
- 효율적인 작동(노드-이웃 쌍 간에 병렬 처리 가능)
- 이웃에게 weight를 설정함으로써 그래프 노드의 중요도 반영 가능
- Inductive learning problems(unseen graph에 대해서 모델의 일반화 가능)
ABSTRACT
GAT (Graph Attention networks)
- Graph convolutions 기반 이전 연구들의 단점 극복을 위해서 self-attentional layer를 추가한 novel한 neural network 구조
- 이웃들의 features 학습 → 각각의 이웃에 다른 가중치를 부여(costly한 matrix 연산 없이(such as inversion) & 그래프 구조에 상관 없이)
- Spectral-based graph neural network, Inductive & Transductive problem 모두에 손쉽게 적용 가능 + 두가지 task SOTA 달성
GAT ARCHITECTURE
2.1 GRAPH ATTENTIONAL LAYER [4]
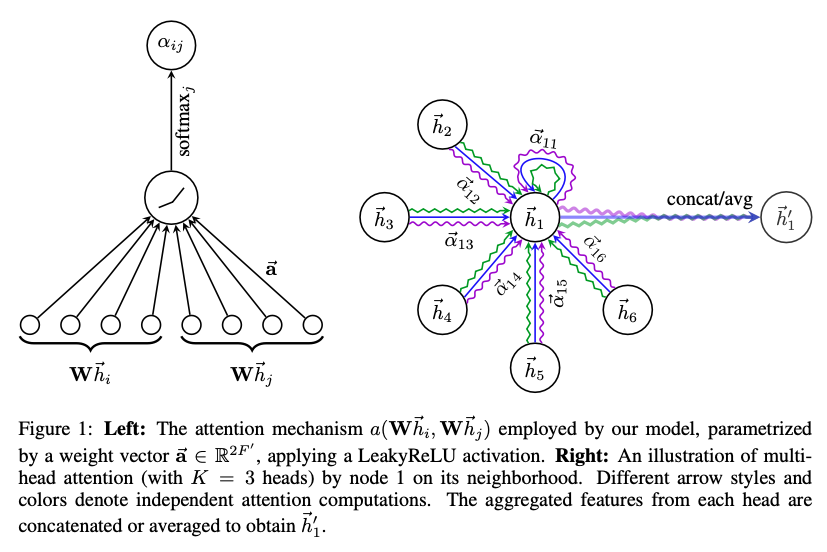
| 파라미터 | 노드의 feature의 set |
|---|---|
| Input | 노드의 feature의 set |
| Layer | 노드 feature의 새로운 set 생산 |
| N | 노드의 수 |
| F | 각 노드의 features의 수 |
| F’ | Hidden layer 길이 |
| W | Trainable parameter |
-
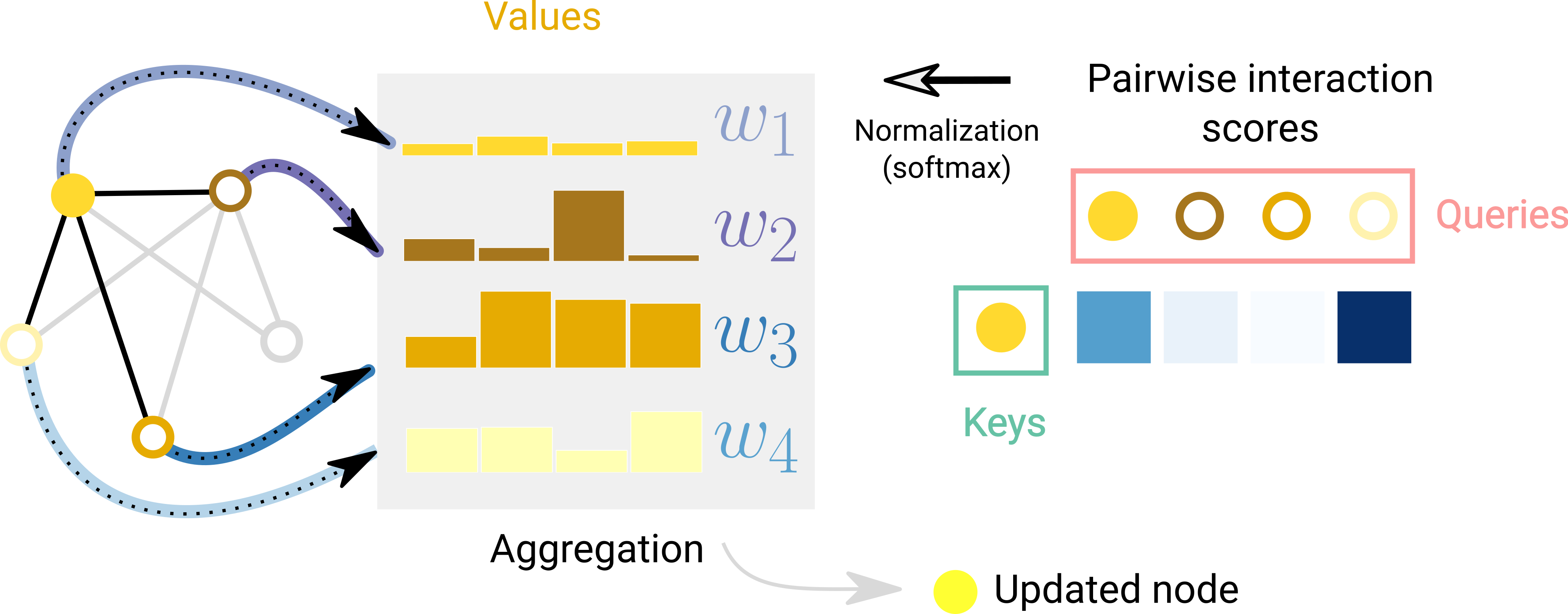
노드에 self-attention 적용, Attention coefficients (node i 에 대해 node j의 feature가 갖는 importance) j는 i의 이웃
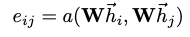
-
다른 노드로부터 coefficients를 쉽게 비교하게 만들기 위해, softmax 함수를 이용
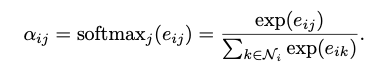
- 위의 $a$ = single-layer feedforward neural network weight vector($\overrightarrow a \in \mathbb{R}^{2F’}$)와 LeakyReLU activation으로 정의
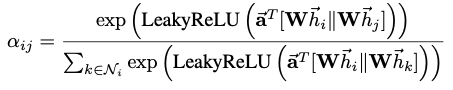
-
이렇게 계산된 Attention score는 Node i 의 중요도를 결정하여 Input data를 다시 정의
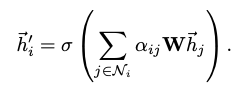
-
GAT에서는 concat한 임베딩 벡터를 feed forward하는 어텐션 네트워크를 K개 가진다. (|| = concatenation operation)
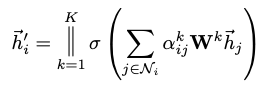
-
만약 h’ 뒤에 output을 위한 fc layer가 추가되는 것이 아닐 때 취하는 구조 5번과 같이 concat 하는 것이 아니라 K개의 F’ 길이 벡터들을 합해준 뒤 평균
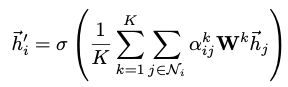
2.2 COMPARISONS TO RELATED WORK
- 계산이 매우 효율적
- Self-attentional layer → 모든 edge 병렬화 가능
- Eigendecompositions or similar costly matrix 작동 필요 X
- GCN과 반대로, 우리의 모델은 주변 이웃의 노드에 different importance를 부여
- Attention mechanism은 그래프의 모든 Edge에 공유 방식으로 적용, 전체적인 그래프 구조 혹은 모든 노드에 대한 사전 접근에 의존 X
- 그래프는 undirected(무방향)가 아니여도 OK (만약 $j → i$ 의 edge가 없다면 $a_{i,j}$를 계산하지 않아도 OK ) → inductive learning을 가능하게 함, 훈련동안 완전히 unseen한 그래프 평가 가능
- 최근의 방식 = LSTM기반 이웃 aggregator를 사용할 때 가장 좋은 결과
- 이것은 neighbor 전체에 걸쳐 일관된 sequential node의 순서를 가정하고, 저자는 무작위로 정렬된 sequence를 일관되고 LSTM에 공급하여 이를 수정
- 우리의 technique은 더 이상 이러한 이슈를 겪지 않음, 순서를 가정할 필요가 없음.
- GAT는 MoNet의 특정 속성으로써 reformulated 될 수 있음
-
pseudo-coordinate function을 setting하여 to be u(x,y) = f(x) f(y) - 그럼에도 불구하고 Monet 인스턴스들과 비교하자면, 우리의 모델은 비슷한 계산을 위해서 노드의 구조적인 속성 보다는 노드의 features들을 사용
-
EVALUATION
3.1 DATASETS
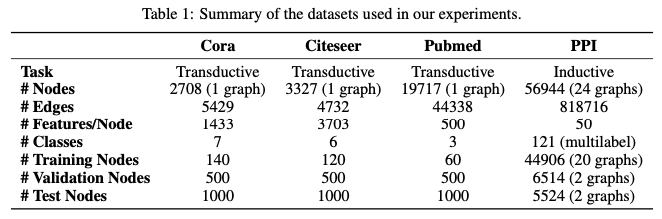
- Transductive & Inductive 모두에 적용되는 graph benchmark dataset
3.2 STATE-OF-THE-ART METHODS
Transductive learning
- Label propagation (LP), semi-supervised embedding(SemiEmb), manifold regularization, skip-gram based embeddings(Deep Walk), iterative classification algorithm(ICA), Planetoid, GCNs, graph convolutional model (Chebyshev filters를 활용한), MoNet
Inductive learning
- GraphSAGE(GraphSAGE-GCN, GraphSAGE-mean, GraphSAGE-LSTM, GraphSAGE-pool)
3.3 EXPERIMENTAL SETUP
Transductive learning
- Two-layer GAT model
| First layer | Second layer(classification) | |
|---|---|---|
| Attention heads | K = 8 | |
| Features | F’ = 8 | |
| Activation function | Exponential linear unit (ELU) nonlinearity | softmax |
-
ELU
-
Hyperparameter를 Cora dataset에 최적화 시킨 후, Cite-seer dataset에도 재사용
Hyperparameter 사용여부 L2 regularization (⁍ = 0.0005) 적용 Normalized attention coefficients 적용 Dropout(⁍) both layer input에 적용 -
Monet의 연구에도 비슷하게, Pubmed’s trainig dataset에 약간의 GAT 구조의 변화 필요, K=8, ouput attention heads, L2 regularization 강화($λ = 0.001$)
Inductive learning
-
Three-layer GAT model
First & Second layer Final layer(multi-label classification) Attention heads K = 4 Features F’ = 256 Activation function Exponential linear unit (ELU) nonlinearity Sigmoid activation -
Hyperparameter
Hyperparameter 사용여부 L2 regularization 미적용 (데이터 셋이 크기 때문에) Dropout 미적용 Skip connection 적용(intermediate attentional layer)
Transductive & Inductive
-
Hyperparameter Glorot initialization Minimize cross-entropy(Adam SGD optimizer) LR 0.01(Pubmed 0.05) Early stopping strategy 100 epoch
3.4 RESULTS
Transductive learning
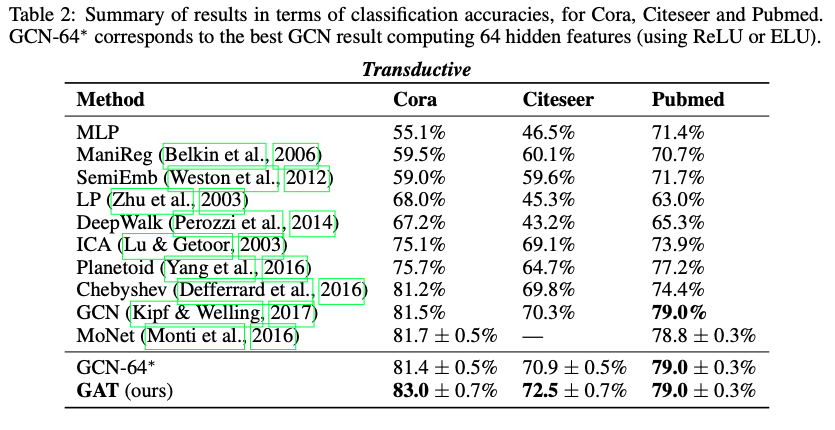
- 평가 : Mean classification accuracy (표준편차 포함)
Inductive learning
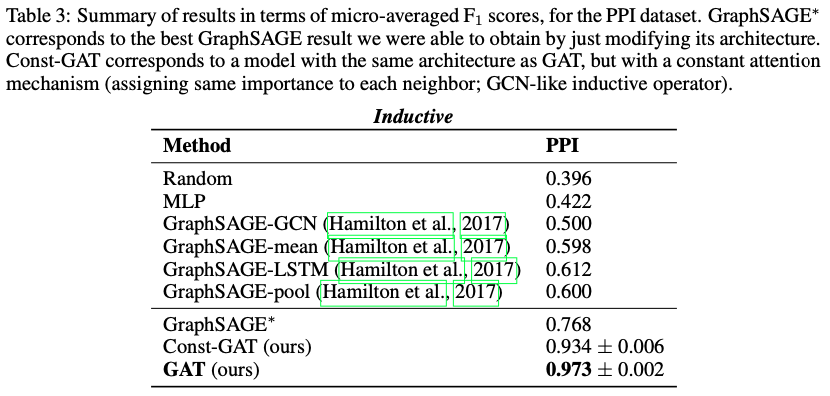
- 평가 : Micro averaged F1 score
→ 4개의 데이터 셋(Trans, Induct)에서 모두 SOTA 달성
- Cora, Citeseer dataset에서 GCN의 성능 개선 → 같은 이웃 노드에 서로 다른 가중치를 적용하는 것이 의미가 있다
- PPI dataset, best GraphSAGE 모델보다 20.5%나 성능 개선 → Inductive setting에 적용해도 좋은 결과를 보인다는 것을 증명
- Const-GAT (the identical architecture with constant attention mechanism)는 서로 다른 이웃에 서로 다른 가중치를 할당한다는 것의 중요성을 의미
-
학습된 features의 표현의 효과를 질적으로 측정 가능, Cora dataset에서 사전 훈련된 GAT 모델의 첫번째 layer에서 추출한 features representation의 시각화 제공

CONCLUSIONS
- GAT = 그래프 구조에 작동하는 masked self-attentional layer를 활용한 novel convolution-style neural networks
- Graph attentional layer = 효율적인 계산(matrix operation 필요 없음, 모든 노드를 병렬로 계산 가능), 서로 다른 노드에 서로 다른 가중치 부여 가능, 전체 그래프 구조에 의존하지 않고, spectral-based approaches 사용
- 4가지 dataset에서 좋은 성능 → Transductive and Inductive에서 좋은 성능
limitation & Future work
- 더 큰 batch size 를 처리할 수 있도록
- Attention mechanism을 활용하여 모델 해석 가능성에 대한 분석
- 노드 분류 대신 그래프 분류에도 적용 가능
- Edge feature를 통합하도록 모델 확장 필요
Reference
[3] [머신 러닝/딥 러닝] 그래프 어텐션 네트워크 (Graph Attention Network) 구조 및 설명
[4] Graph Attention Networks (Pytorch)
[5] 고려대학교 DMQA 연구실